

一个容易出错的题
贪心算法(英语:greedy algorithm),又称贪婪算法,是一种在每一步选择中都采取在当前状态下最好或最优(即最有利)的选择,从而希望导致结果是最好或最优的算法。 比如在旅行推销员问题中,如果旅行员每次都选择最近的城市,那这就是一种贪心算法。
描述
给定一个区间的集合,找到需要移除区间的最小数量,使剩余区间互不重叠。
注意:
- 可以认为区间的终点总是大于它的起点。
- 区间 [1,2] 和 [2,3] 的边界相互“接触”,但没有相互重叠。
示例 1:
输入: [ [1,2], [2,3], [3,4], [1,3] ]
输出: 1
解释: 移除 [1,3] 后,剩下的区间没有重叠。
输入: [ [1,2], [1,2], [1,2] ]
输出: 2
解释: 你需要移除两个 [1,2] 来使剩下的区间没有重叠。
输入: [ [1,2], [2,3] ]
输出: 0
解释: 你不需要移除任何区间,因为它们已经是无重叠的了。
解题
首先进行排序,排序后的数据更容易比较,不然再无序状态下需要频繁的遍历数组。
- 排序,首先根据起始点排序,起始位置相同的情况下比较结束位置。
- 排序之后,可能会出现多种情况。如图下5种情况。
- 情况1,重叠 A1.start < A2.start && A1.end < A2.end
- 情况2,重叠 A1.strat < A2.start && A1.end > A2.end
- 情况3,重叠 A1.strat < A2.start && A1.end = A2.end
- 情况4,不重叠 A2.start >= A1.end
- 情况5,重叠 A1.start=A2.start && A1.end < A2.end,因为已经排好序了,所以不会出现A1.end > A2.end的情况
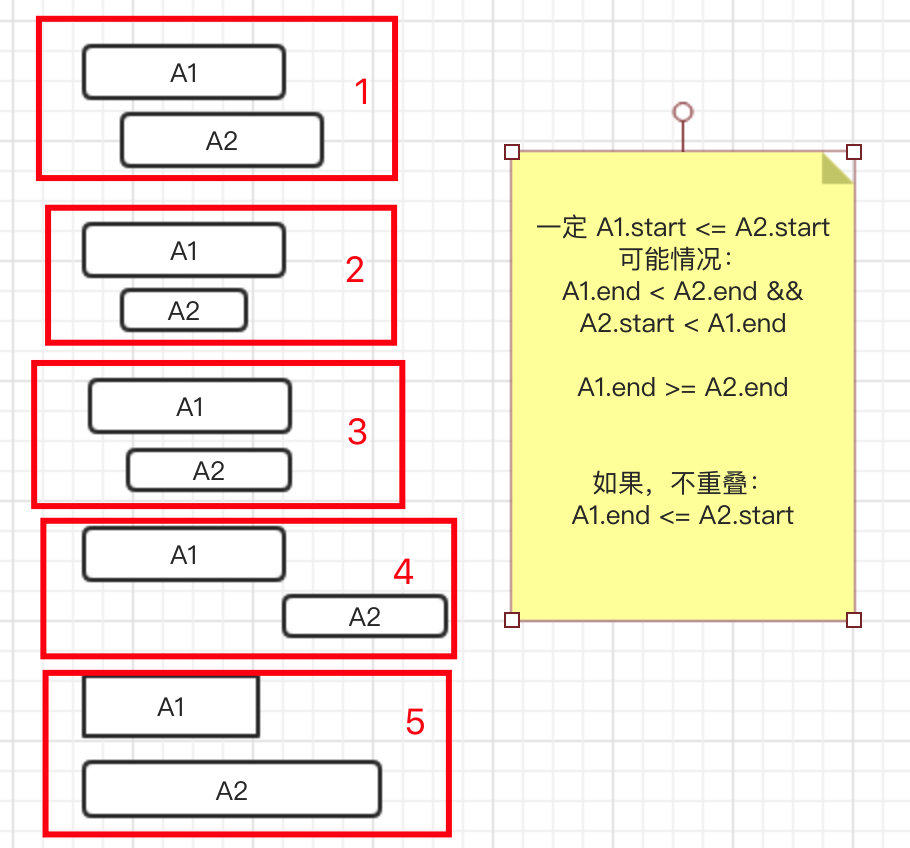
- 除了要判断是否重叠,还有一个要考虑的因素。找到需要移除区间的最小数量,那么在上面的5种情况中,要移除哪一个比较合适呢?移除A1,还是A2
- 情况1,移除A2,因为A2更可能与后面的元素重叠
- 情况2,移除A1,因为A1占的空间更大,与A1重叠的可能性大于A2
- 情况3,移除A1,原因同上
- 情况4,不重叠,无需处理
- 情况5,移除A2,A2更容易与后面的元素重叠。
编码
- 首先排序。
// 对数组排序,从小到大排序,首先比较start,再比较end
// 排序前 [ [1,2], [2,3], [3,4], [1,3] ]
// 排序后 [ [1,2], [1,3],[2,3], [3,4] ]
Arrays.sort(intervals, new Comparator<Interval>() {
@Override
public int compare(Interval o1, Interval o2) {
if (o1.start == o2.start) {
return o1.end - o2.end;
}
return o1.start - o2.start;
}
});
- 考虑各种情况,与元素的处理。这一步的情况处理,与上面分析的一致,只需要看明白上面的解题思路即可
// 当前需要被比较的Interval坐标
int currentIndex = 0;
// 重复区间的个数
int count = 0;
for (int i = 1; i < intervals.length; i++) {
// 情况1
// currentIndex [=====]
// intervals[i] [=====]
boolean overLapFlag = false;
if (intervals[currentIndex].end <= intervals[i].end && intervals[i].start < intervals[currentIndex].end) {
count++;
overLapFlag = true;
}
// 情况2 && 情况3
// currentIndex [=====]
// intervals[i] [==]
else if (intervals[currentIndex].end >= intervals[i].end) {
count++;
overLapFlag = true;
}
// 情况 5 ,因为已经排好序了,所以后续元素肯定大于前一个
// currentIndex [====]
// intervals[i] [======]
else if (intervals[currentIndex].start == intervals[i].start) {
count++;
overLapFlag = true;
}
// 当某个元素占的空间太大的时候,考虑换一下位置
// 判断条件同条件2
if (overLapFlag){
if (intervals[currentIndex].end >= intervals[i].end)
{
System.out.println("替换元素:currentIndex" + intervals[currentIndex] + "~" + intervals[i]);
currentIndex = i;
}
continue;
}
// 最后一种
// currentIndex [====]
// intervals[i] [===]
currentIndex = i;
}
- 代码汇总
public static int eraseOverlapIntervals(Interval[] intervals) {
if (intervals.length == 0 || intervals.length == 1) {
return 0;
}
// 对数组排序,从小到大排序,首先比较start,再比较end
// 排序前 [ [1,2], [2,3], [3,4], [1,3] ]
// 排序后 [ [1,2], [1,3],[2,3], [3,4] ]
Arrays.sort(intervals, new Comparator<Interval>() {
@Override
public int compare(Interval o1, Interval o2) {
if (o1.start == o2.start) {
return o1.end - o2.end;
}
return o1.start - o2.start;
}
});
// 当前需要被比较的Interval坐标
int currentIndex = 0;
// 重复区间的个数
int count = 0;
// for (int i = 0; i < intervals.length; i++) {
// System.out.println("[" + intervals[i].start + "," + intervals[i].end + "]");
// }
for (int i = 1; i < intervals.length; i++) {
// 情况1
// currentIndex [=====]
// intervals[i] [=====]
boolean overLapFlag = false;
if (intervals[currentIndex].end <= intervals[i].end && intervals[i].start < intervals[currentIndex].end) {
count++;
overLapFlag = true;
}
// 情况2 && 情况3
// currentIndex [=====]
// intervals[i] [==]
else if (intervals[currentIndex].end >= intervals[i].end) {
count++;
overLapFlag = true;
}
// 情况 5 ,因为已经排好序了,所以后续元素肯定大于前一个
// currentIndex [====]
// intervals[i] [======]
else if (intervals[currentIndex].start == intervals[i].start) {
count++;
overLapFlag = true;
}
// 当某个元素占的空间太大的时候,考虑换一下位置
// 判断条件同条件2
if (overLapFlag){
if (intervals[currentIndex].end >= intervals[i].end)
{
System.out.println("替换元素:currentIndex" + intervals[currentIndex] + "~" + intervals[i]);
currentIndex = i;
}
continue;
}
// 最后一种
// currentIndex [====]
// intervals[i] [===]
currentIndex = i;
}
return count;
}
- 执行结果

额外
还有一种用贪心算法,只比较不重复元素的数量,剩下的都是要删除的,只比较了第4种情况
如图:
- 如果,A1的start很小,但是end很长,那么会错过很多元素。
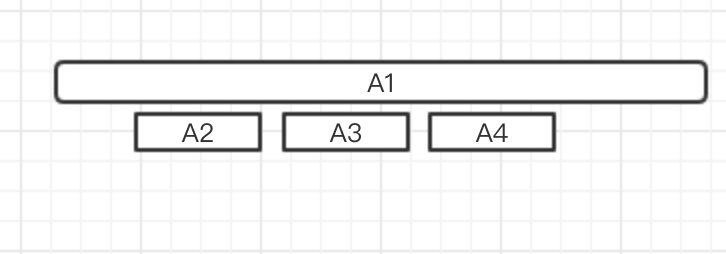
所以,也要进行判断当前的元素是不是过于长。包含了前一个元素
思路如下:
public static int eraseOverlapIntervalsV2(Interval[] intervals) {
if (intervals.length == 0 || intervals.length == 1) {
return 0;
}
// 对数组排序,从小到大排序,首先比较start,再比较end
// 排序前 [ [1,2], [2,3], [3,4], [1,3] ]
// 排序后 [ [1,2], [1,3],[2,3], [3,4] ]
Arrays.sort(intervals, new Comparator<Interval>() {
@Override
public int compare(Interval o1, Interval o2) {
if (o1.start == o2.start) {
return o1.end - o2.end;
}
return o1.start - o2.start;
}
});
// 当前需要被比较的Interval坐标
int currentIndex = 0;
// 重复区间的个数
int count = 1;
for (int i = 1; i < intervals.length; i++) {
// 最后一种
// currentIndex [====]
// intervals[i] [===]
if (intervals[i].start >= intervals[currentIndex].end){
count++;
currentIndex = i;
}
else {
if (intervals[i].end <= intervals[currentIndex].end){
currentIndex=i;
}
}
}
return intervals.length - count;
}
其实和上一步是一样的了。
最后
思路清晰才能写出优雅的代码
