

(注意:这是一篇试图向不完全熟悉统计数据的读者解释Logistic回归背后的直觉的帖子。因此,你可能在这里找不到任何严谨的数学工作。)
1.与实测回归法不同,逻辑回归不会尝试在给定一组输入的情况下预测数值变量的值。相反,输出是给定输入点属于某个类的概率。为简单起见,假设我们只有两个类(对于多类问题,您可以查看多项Logistic回归),并且所讨论的概率是P+ - >某个数据点属于' +'类的概率。当然,P_ =1-P+。因此,Logistic回归的输出总是在[0,1]中。
2. Logistic回归的核心前提是假设您的输入空间可以被分成两个不错的“区域”,每个类对应一个线性(读取:直线)边界。那么“线性”边界是什么意思呢?对于两个维度,它是一条直线 - 没有弯曲。对于三维,它是一个平面。等等。这个边界将由您的输入数据和学习算法决定。但是为了理所当然,很明显数据点必须通过线性边界分成上述两个区域。如果您的数据点确实满足此约束,则称它们是线性可分的。看下面的图片。
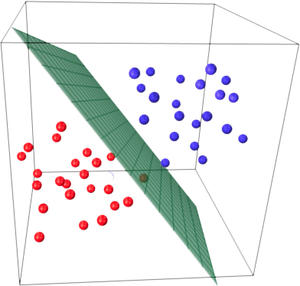
这个划分平面称为线性判别式,因为 1.它的功能是线性的,2。它有助于模型在属于不同类别的点之间“区分”。(注意:如果您的点在原始概念空间中不能线性分离,您可以考虑通过添加交互项的维度,更高维度项等来将特征向量转换为更高维度的空间。这样的线性算法更高维空间的使用为您提供了非线性函数学习的一些好处,因为如果在原始输入空间中绘制回边界,则边界将是非线性的。)
========== X ===========
首先,让我们尝试理解输入空间“划分”到两个不同的区域的几何意义。假设两个输入简单变量(与上面显示的三维图不同) x1和x2,对应边界的函数将类似于

。(至关重要的是要注意x1和x2输入变量是两个,并且输出变量不是概念空间的一部分 - 与线性回归等技术不同。)考虑一下(a,b)。输入x1 和x2的值到边界函数,我们会得到它的输出

。现在依据(a,b)的位置,有三种可能性 :
1. (a,b)位于由+类点定义的区域。结果
将是正向的,位于(0,∞)的某个地方。在数学上,该值的幅度越大,点与边界之间的距离越大。直观地说,(a,b)属于+类的概率越大。因此,P+将在(0.5,1)。
2. (a,b)位于由-类定义的区域。现在,
将是负向的,躺在( - ∞,0)。但是在正面情况下,函数输出的绝对值越高,(a,b)属于-类的概率就越大。P+现在将位于[0,0.5]。
3. (a,b)位于线性边界上。在这种情况下,

。这意味着该模型无法真正说明是(a,b)属于+类还是-类。结果,P+将正好是0.5。
所以现在我们有一个函数在给定输入数据点的情况下输出( - ∞,∞)的值。但是我们如何将其映射到P+,从[0,1] 开始的概率?答案就在
} {1-P(X)}")
,基本上是事件发生概率与未发生概率之比。很明显,概率和几率传达完全相同的信息。但是当$ P(X)$从0变为1时,OR(X)从0变为 ∞.
然而,我们仍然还没有应用,因为我们的边界函数从给出的值- ∞到∞。所以我们要做的,就是以
所以我们终于有办法解释将输入属性带入边界函数的结果。边界函数实际上定义了+类在我们模型中的对数几率。因此基本上,在二维的例子中,给定一点
(a,b),Logistic回归会做的事情 如下:
第1步。计算边界函数(或者,log-odds函数)值
。让我们简单地称这个值t。
第2步。通过这样做来计算优势比

。(因为t是OR+的对数)。
第3步。知道了OR+,它会使用简单的数学关系进行计算P+

。事实上,一旦你知道从第1步得出的t,你可以结合第2步和第3步给出

上述等式的RHS称为逻辑函数。因此,也给这个学习模型的名称:-)。
========== X ===========
我们现在已经理解了Logistic回归背后的直觉,但问题仍然存在 - 它如何学习边界函数
?这背后的数学工作超出了这篇文章的范围,但这是一个粗略的想法:考虑一个函数g(x),其中x是训练数据集中的数据点。g(x)可以简单地定义为:如果x是+类的一部分,g(x)=P+,(这里P+是Logistic回归模型给出的输出)。如果x是-类的一部分,g(x)=1-P+。直观地,g(x)量化您的模型
========== X ===========
目前为止就这样了!就像我的所有博客帖子一样,我希望这个可以帮助一些尝试通过Google和自己学习一些东西的人,去理解Logistic回归技术的误解。
更多文章欢迎访问: http://www.apexyun.com
公众号:银河系1号
联系邮箱:public@space-explore.com
(未经同意,请勿转载)
