

by laifeipeng 2019-03-01
0、前言
前端需要的数据通常有这几种方法产生:
- 1、自己建数据库,并开发服务器把数据丢给前端
- 2、使用第三方的公共API调用第三方的数据
- 3、模拟第三方的接口请求,获取第三方的数据,jsop、cors等【不一定可行】
- 4、自己写爬虫,爬第三方的数据
这几种方法中,爬虫是比较简单直接且靠谱的,因为第一种太麻烦,第二种人家第三方不一定有这样的公共API接口,第三种人家不一定给你用,所以还是第四种(爬虫)比较好,只要你会,一般能拿到数据。
如果你还不会,来来来,5分钟就教会!
1、初始代码
const superagent = require('superagent'); //nodejs里一个非常方便的客户端请求代理模块
const cheerio = require('cheerio'); //Node.js 版的jQuery
const BASE_URL = 'https://www.zbjuran.com/'; // 高清美女图片大全
const SUB_PATH = 'mei/';
const fullUrl = BASE_URL + SUB_PATH;
const rst = []; // 存放最后的结果
superagent.get(fullUrl)
.end((err, res) => {
if (err) {
return console.error(err);
}
// console.log(res.text)
let $ = cheerio.load(res.text);
$('.main .pic-list li .picbox img').each((idx, element) => {
const $element = $(element)['0']['attribs'];
let pic = $element['data-original'];
!$element['data-original'].includes(BASE_URL) && (pic = BASE_URL + pic); // 如果没有前缀则加上
rst.push({
picUrl: pic,
alt: $element['alt'],
width: $element['width'],
height: $element['height'],
})
})
console.log(rst);
})
2、过程分析
1、先找一个美女多的网站,比如 www.zbjuran.com/mei/
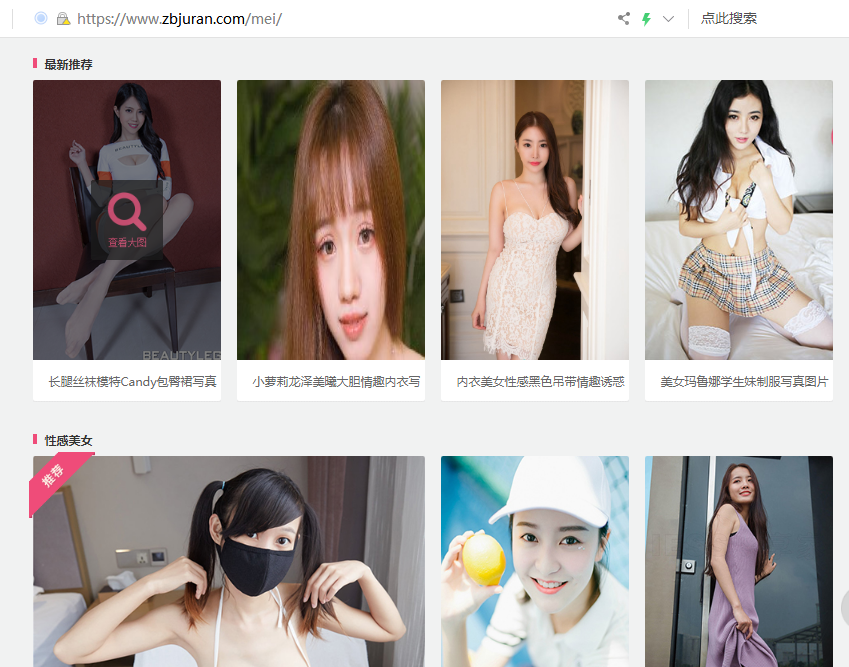
2、再找到要爬取的照片的html结构
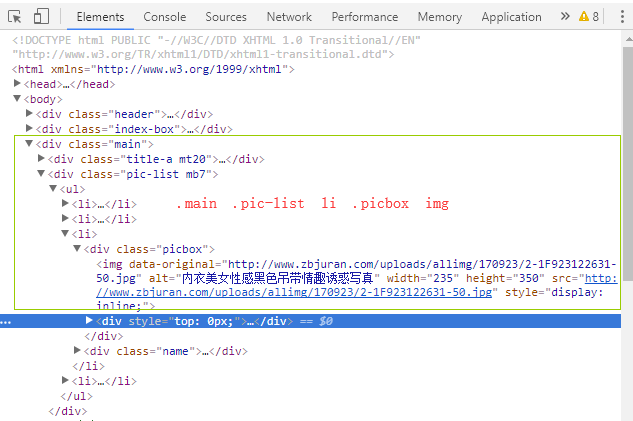
3、编码(见文章开头代码)
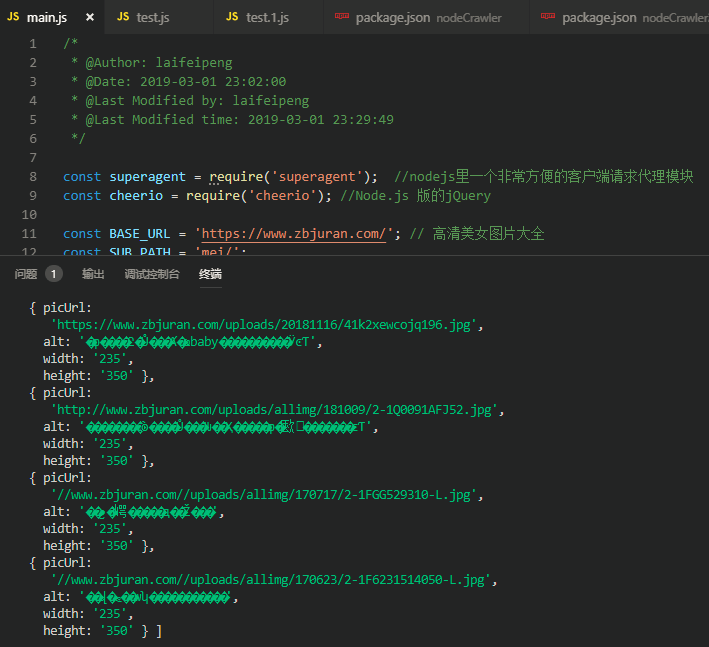
4、控制台打印出来的结果
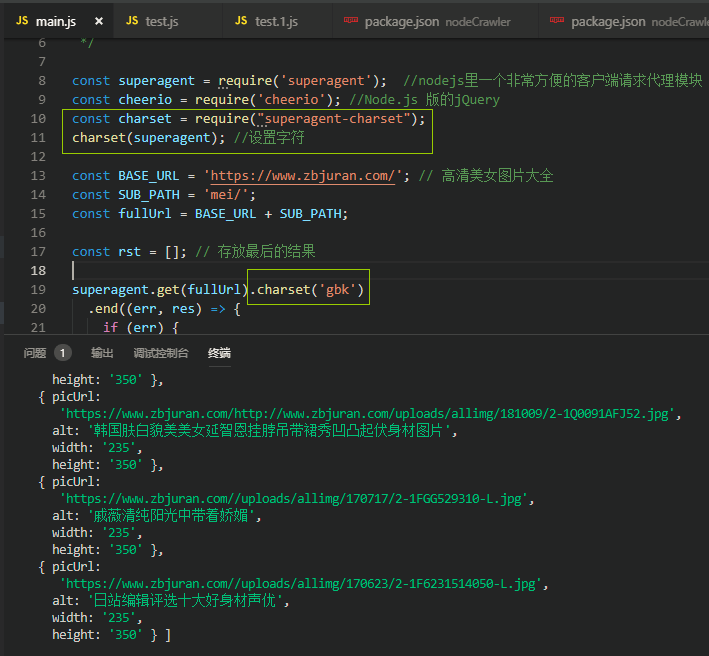
5、中文乱码的解决
如下图,增加3句代码即可!
6、保存图片到本地
//创建目录
function mkdir(_path, callback) {
if (fs.existsSync(_path)) {
console.log(`${_path}目录已存在`)
} else {
fs.mkdir(_path, (error) => {
if (error) {
return console.log(`创建${_path}目录失败`);
}
console.log(`创建${_path}目录成功`)
})
}
callback(); //没有生成指定目录不会执行
}
//下载爬到的图片
function downloadImg() {
rst.forEach((imgUrl, index) => {
//下载图片存放到指定目录
const stream = fs.createWriteStream(`./pic/${imgUrl.alt}.jpg`);
const req = superagent.get(imgUrl.picUrl); //响应流
req.pipe(stream);
})
}
mkdir('./pic', downloadImg); // 保存图片到本地
3、最终代码
/*
* @Author: laifeipeng
* @Date: 2019-03-01 23:02:00
* @Last Modified by: laifeipeng
* @Last Modified time: 2019-03-06 12:13:59
*/
const path = require('path');
const fs = require('fs');
const superagent = require('superagent'); //nodejs里一个非常方便的客户端请求代理模块
const cheerio = require('cheerio'); //Node.js 版的jQuery
const charset = require("superagent-charset"); //解决superagent中文乱码问题
charset(superagent); //设置字符
superagent.buffer['jpg'] = true;
//创建目录
function mkdir(_path, callback) {
if (fs.existsSync(_path)) {
console.log(`${_path}目录已存在`)
} else {
fs.mkdir(_path, (error) => {
if (error) {
return console.log(`创建${_path}目录失败`);
}
console.log(`创建${_path}目录成功`)
})
}
callback(); //没有生成指定目录不会执行
}
//下载爬到的图片
function downloadImg() {
rst.forEach((imgUrl, index) => {
//下载图片存放到指定目录
const stream = fs.createWriteStream(`./pic/${imgUrl.alt}.jpg`);
const req = superagent.get(imgUrl.picUrl); //响应流
req.pipe(stream);
})
}
const MEI_URL = 'https://www.zbjuran.com/mei/';// 高清美女图片大全
const rst = []; // 存放最后的结果
superagent.get(MEI_URL)
.charset('gbk') // 解决中文乱码
.end((err, res) => {
if (err) {
return console.error(err);
}
// console.log(res.text)
let $ = cheerio.load(res.text);
$('.main .pic-list li .picbox img').each((idx, element) => {
const $element = $(element)['0']['attribs'];
let pic = $element['data-original'];
// 把相对路径的图片地址加上hostname,构成完整的url路径【如果没有前缀则加上】
!$element['data-original'].includes('//www.zbjuran.com/') && (pic = 'https://www.zbjuran.com/' + pic);
rst.push({
picUrl: pic,
alt: $element['alt'],
width: $element['width'],
height: $element['height'],
})
})
console.log(rst);
mkdir('./pic', downloadImg); // 保存图片到本地
})
github地址:github.com/laifeipeng/…
