


微信公众号:深广大数据Club关注可了解更多大数据相关的咨询。问题或建议,请公众号留言;如果你觉得深广大数据Club对你有帮助,欢迎转发朋友圈推荐关注
每当我们拥有一个拥有大量用户的数据库时,遇到数据库中的热点并不罕见。对于Redis,频繁访问分区中的相同Key称为热点。在本文中,我们将讨论热点的常见原因,评估此问题的影响,并提出有效的解决方案来处理热点。
热点的常见原因
原因1:用户消费数据的大小远远大于生产数据的大小,包括热门项目,热门新闻,热门评论和名人直播。
在你的日常工作和生活中出现意外事件,例如:当天降价和促销某些热门商品,当其中一件物品被浏览或购买数万次时,需求会更大,并且这种情况会导致热点问题。
同样,它已经被大量的热门新闻,热门评论,明星直播等发布和观看,这些典型的无读写场景也产生了热点问题。
原因2:请求切片数超过单个服务器的性能阈值。
在服务器上访问一条数据时,通常会对数据进行拆分或切片。在此过程中,将在服务器上访问相应的Key。当访问流量超过服务器的性能阈值时,会出现热键问题。
热点问题的影响
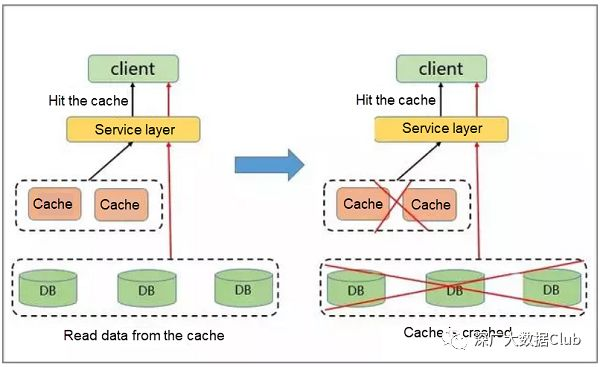
-
流量集中,达到物理网络适配器的上限。
-
请求排队太多,导致缓存的分片服务崩溃。
-
数据库过载,导致服务雪崩。
如前所述,当服务器上的热点请求数超过服务器上网络适配器的上限时,由于流量过度集中,服务器停止提供其他服务。
如果热点的分布过于密集,则会缓存大量热点,从而耗尽缓存容量并导致缓存的分片服务崩溃。
缓存服务崩溃后,新生成的请求将缓存在后台数据库中。由于该数据库性能不佳,很容易因大量请求而耗尽,导致服务雪崩和性能大幅下降。
推荐解决方案
提高性能的常见解决方案是通过服务器或客户端上重建。
Server缓存解决方案
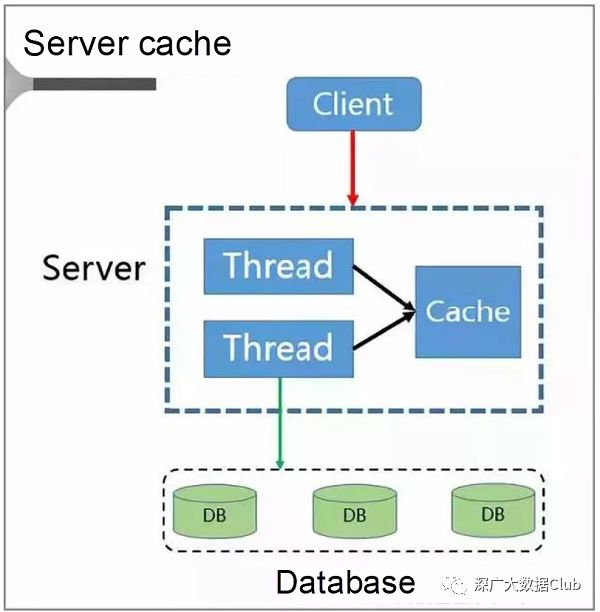
客户端将请求发送到服务器。假定服务器是多线程服务,则可以使用基于高速缓存LRU策略的本地高速缓存空间。
当服务器变得拥挤时,它直接将请求转发回来而不是将它们转发到数据库。只有在稍后清除拥塞之后,服务器才会将请求从客户端发送到数据库并将数据重新写入缓存。访问并重建缓存。
但是,该程序还存在以下问题:
-
缓存失败时缓存多线程服务的构建问题
-
缓存丢失时缓存构建问题
-
脏读问题
“MemCache + Redis”解决方案
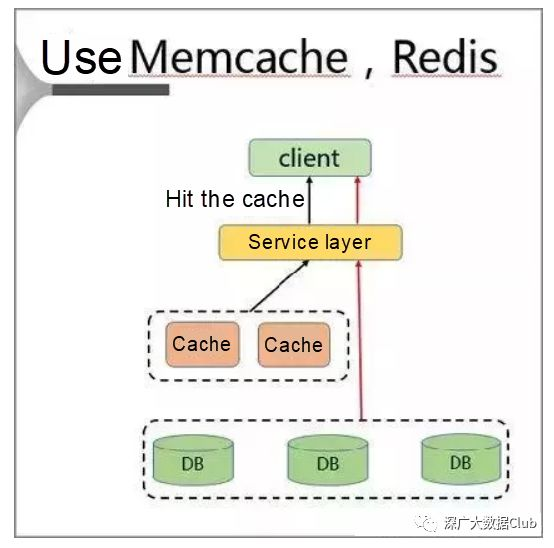
在此解决方案中,在客户端上部署单独的缓存以解决热点问题。
采用此解决方案时,客户端首先访问服务层,然后访问同一主机上的缓存层。
该解决方案具有以下优势:就近访问,高速和零带宽限制。但是,它也有以下缺点:
-
浪费了内存资源
-
脏读问题
本地缓存解决方案
使用本地缓存会产生以下问题:
-
必须提前检测热点。
-
缓存容量有限。
-
不一致的持续时间很长。
-
热点不完整。
如果传统的热点解决方案都有缺陷,那么如何解决热点问题呢?
读/写拆分解决方案
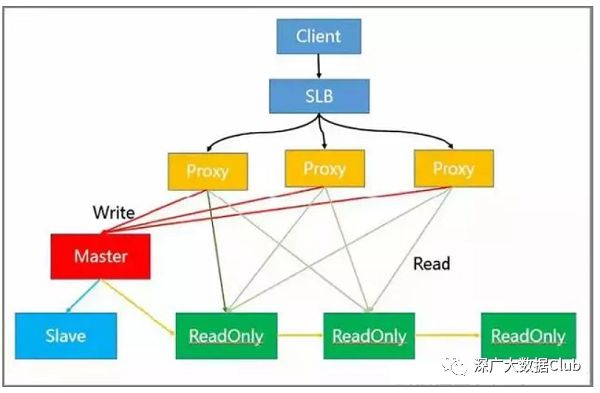
该解决方案解决了热点读取问题。以下描述了体系结构中不同节点的功能:
-
负载平衡在SLB层实现。
-
在代理层实现读/写分离和自动路由。
-
写请求由主节点处理。
-
读取请求由只读节点处理。
-
HA在从节点和主节点上实现。
实际上,客户端向SLB发送请求,SLB将这些请求分发给多个代理。然后,代理识别并分类请求并进一步分发它们。
例如,代理将所有写请求发送到主节点,并将所有读请求发送到只读节点。但是模块中的只读节点可以进一步扩展,从而有效地解决了热点读取的问题。读写分离还具有灵活扩容读取热点的能力,可以存储大量热点关键,客户端友好等优点。
热点数据解决方案
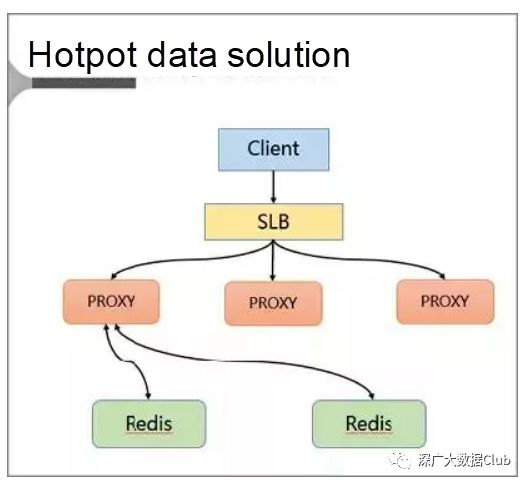
在此解决方案中,发现并存储热点以解决热点问题。
具体来说,客户端访问SLB并通过SLB将请求分发给代理。然后,代理通过路由将请求转发到后台Redis。
此外,还在服务器上添加了缓存。
具体而言,将本地缓存添加到代理。此缓存使用LRU算法来缓存热点数据。此外,将热点数据计算模块添加到后台数据库节点以返回热点数据。
代理架构的主要优点是:
-
代理在本地缓存热点数据,其读取能力可水平扩展。
-
数据库节点定期计算热点数据集。
-
数据库将热点数据反馈给代理。
-
代理体系结构对客户端是完全透明的,因此不必增加兼容性。
处理热点
读取热点数据
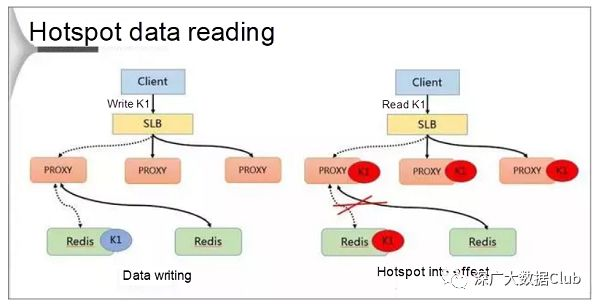
热点处理分为两个部分:写入和读取。在数据写入期间,SLB接收数据K1并通过代理将其写入Redis数据库。
如果K1在后台热点模块进行计算后成为热点,则代理会缓存热点。通过这种方式,客户端可以在下次绕过Redis时直接访问K1。
最后,因为代理可以水平扩展,所以热点数据的可访问性也可以无限增强。
发现热点数据
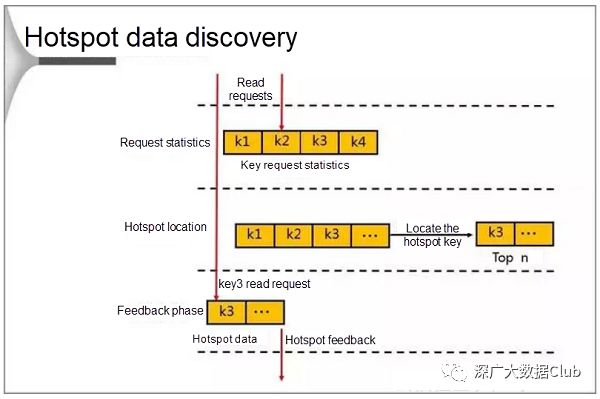
在发现期间,数据库首先计算在一个周期中发生的请求。当请求数达到阈值时,数据库将找到热点并将其存储在LRU列表中。当客户端通过向代理发送请求来尝试访问数据时,Redis会进入反馈阶段并在发现目标访问点是热点时标记数据。
数据库使用以下方法计算热点:
-
基于统计阈值的热点统计。
-
基于统计周期的热点统计。
-
基于版本号的统计信息收集方法,在使用时不需要重置初始值。
-
计算数据库上的热点具有最小的性能影响和轻量级内存占用。
解决方案的比较
从前面的分析可以看出,在解决热点问题时,这两种解决方案都是传统解决方案的改进。此外,读/写分离和热点数据解决方案都支持灵活的容量扩展,并且对客户端是透明的,尽管它们无法确保100%的数据一致性。
读/写分离解决方案支持存储大型热点数据卷,而基于代理的热点数据解决方案更具成本效益。
参考链接:
https://www.alibabacloud.com/blog/redis-hotspot-key-discovery-and-common-solutions_594446?spm=a2c41.12559851.0.0https://medium.com/@Alibaba_Cloud/redis-hotspot-key-discovery-and-common-solutions-95474d27e0f8
关注公众号


