

什么是数据一致性
数据一致性这个单词在平常开发中,或者各种文章中都能经常看见,我们常常听见什么东西数据不一致了,造成了一定的损失,赶快修复一下。但是很多同学对一致性具体代表什么意思,他有什么作用依然不是很了解,今天我们就来聊聊一致性。
一般来说数据一致性我们可以分成三类,时间点一致性,事务一致性,应用一致性。
时间点一致性(Point in time Consistency)
时间点一致性我觉得也可以叫做副本一致性,时间点一致性的定义为:
如果所有相关的数据组件在任意时刻都是一致的,那么可以称作为时间点一致性。
这个定义如果你了解过CAP理论的话,那么你应该不会太陌生。(如果不熟悉的同学可以看我这篇文章分布式事务)
在CAP中的C的定义为对某个指定的客户端来说,读操作能返回最新的写操作。我们可以发现时间点并没有规定一致的需要保证是最新的,所以可能有同学会提出疑问时间点一致性的范围比CAP中的一致性范围要大一点。其实细想一下如果我们某个数据组件更新了数据,如果为了满足时间点一致性,那么我们所有相关的数据组件的数据都是一致的,所以其他的数据都会变为最新的,那么其实就和CAP是一样的,都需要满足如果在某个节点更新了数据,那么在其他节点如果都能读取到这个最新的数据。
当然CAP和时间点一致性并不是完全的一致:时间点一致性的定义中要求所有数据组件的数据在任意时刻都是完全一致的,但是一般来说信息传播的速度最大是光速,其实并不能达到任意时刻一致,总有一定的时间不一致,对于我们CAP中的一致性来说只要达到读取到最新数据即可,达到这种情况并不需要严格的任意时间一致。
这里我们还需要注意的是这个并不总是用于分布式系统中的,在我们单个机器中如果有多核处理器,我们再任意时刻访问不同处理器对同一变量数据都需要是一致的也可以同样适用。
事务一致性
一致性不仅仅可以表示数据的同时变更或相同性,还可以用来表示约束,而我们的事务一致性就是其中的一种。事务一致性就是我们平时所说的ACID中的C,其定义如下:
事务的一致性指的是在一个事务执行之前和执行之后数据库都必须处于一致性状态。如果事务成功地完成,那么系统中所有变化将正确地应用,系统处于有效状态。如果在事务中出现错误,那么系统中的所有变化将自动地回滚,系统返回到原始状态。
事务一致性只能存在在事务开始前的和事务完成之后,在事务过程中数据有可能不一致。举个例子:比如A转100元给B,A扣减100,B加上100,在事务开始前和事务完成之后都能保证他们的帐是对上的,那么这就是事务一致性。但是在事务过程中有可能会出现A扣减了100元,B没有加上100元的情况,这就是不一致。
这里一般的初学者都会把CAP和ACID中的C都会误解成一样的含义,其实他们其中一个表示的数据的相同,而另一个是用来表示某种约束。
应用一致性
应用一致性可以看做是约束一致性中的一种。上面的事务一致性代表的是单一数据源,如果数据源是多个,比如数据源有多个数据库,文件系统,缓存等。那么就需要我们应用一致性,这里也看做是分布式事务一致性。
在应用程序中涉及多个不同的单机事务,只有在所有的单机事务完成之前和完成之后,数据是完全一致的。比如给用户发送券和积分,券服务和积分服务是两个服务,他们各自有自己单机事务,这两个单机单机事务开始前和完成后都能保证用户的帐是对应上的。但是在这两个单机事务执行过程有可能会出现只送了券,没有送积分的情况,有可能状态不正确。
这三种一致性可以简单的看做两类,一个是数据副本一致,另一个是数据约束一致。接下来我更多的会介绍数据副本的一致的类型,而数据约束的一致,可以参考我之前写过的分布式事务的那篇文章。
一致性的模型
再写这篇文章之前,我一直以为一致性就那么几个常听说的,强一致,弱一致,最终一致。再查询了一些文献资料之后发现一致性的类型真的是非常的多,这里我挑选一些比较重要的
如果有人问你你知道哪些一致性模型呢?很多人马上答出,强一致,最终一致。其实一致性的模型远远不止这么点,在《Operational Characterization of Weak Memory Consistency Models》这篇论文当中描述了15种弱内存一致模型,而在维基百科对内存模型的描述还有更多。
很多一致性的模型最开始是用来描述内存是否一致的,也就是最开始并不是运用于分布式系统当中的。如果我们的机器是单核的话,那么他的内存一定是强一致的。如果我们的机器是多核的话,那么由于处理器并不是直接访问的内存而是访问的处理器独享的缓存,那么就有可能会出现不一致。再分布式中我们的每个节点其实就可以看成一个独立的处理器,而我们最初运用于内存一致性模型,也可以运用于我们分布式系统当中。下面我会从强到弱讲讲一些常见的一致性模型。
线性一致性
线性一致性又叫做原子一致性,强一致性。线性一致性可以看做只有一个单核处理器,或者可以看做只有一个数据副本,并且所有操作都是原子的。在可线性化的分布式系统中,如果某个节点更新了数据,那么在其他节点如果都能读取到这个最新的数据。可以看见线性一致性和我们的CAP中的C是一致的。
举个非线性一致性的例子,比如有个秒杀活动,你和你的朋友同时去抢购一样东西,有可能他那里的库存已经没了,但是在你手机上显示还有几件,这个就违反了线性一致性,哪怕过了一会你的手机也显示库存没有,也依然是违反了。
线性一致性有什么作用呢?在《DDIA》这本书中描述了下面3个作用:
- 加锁与主节点选举:主从复制系统需要确保只有一个主节点,否则会产生脑裂。选举新的主节点一般是使用锁:每个启动的节点都需要获得锁。而这个锁就需要满足可线性化,让所有的节点都同时同意哪个节点有锁。我们的ZooKeeper就可以用来提供分布式锁功能,那么我们就可以说ZooKeeper是满足线性一致性的吗?这个只能说说对了一部分,后面再顺序一致性的时候会对ZK是什么一致性再次说明。
- 约束与唯一性保证:比如同一个文件目录下不允许有两个相同的文件名,数据库主键不能重复,这些都需要线性化。其实这些本质和加锁类似,比如相同的文件名,那其实就是对这个文件名去做一个加锁操作,然后去保存,后保存的自然会出错。
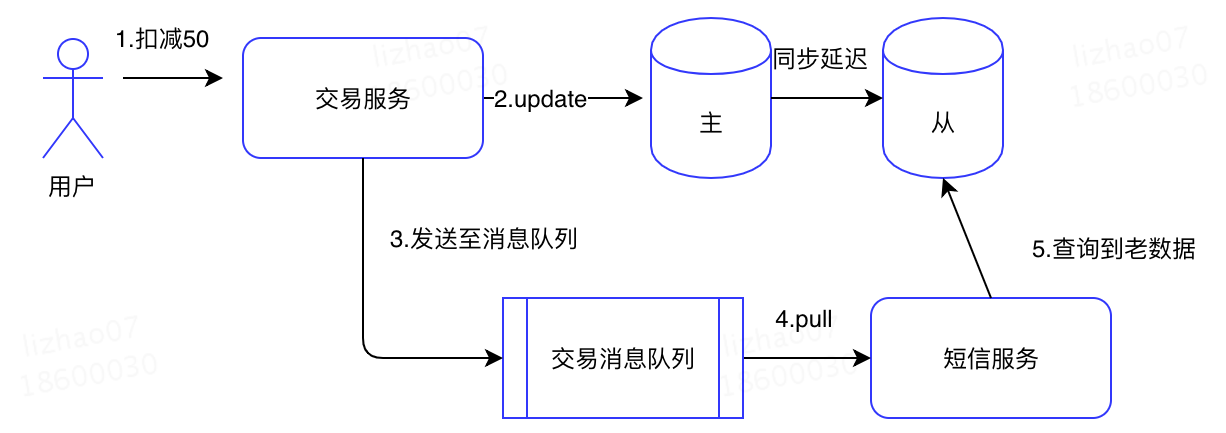
- 跨通道的时间依赖:之前的那个抢购的那个例子为什么会被违反呢?原因是因为我们通过朋友告知这个通道,让我们提前知道了这个货物已经卖完。同样的如果我们计算机中出现了多个通道。举个例子,在用户交易的场景下,用户使用了50元,那么会在其余额中扣减50元,这个时候把这个事件作为一个消息队列给发送出去,然后短信服务会查询用户的余额然后进行发送短信,如果余额数据库的从库这个时候还没有更新数据,那么这个短信就有可能会取到用户旧的余额。这里出现不一致的原因就是因为多了一个通道,就和我们上面朋友告知我们卖完的通道一样。解决这个办法可以控制某一个通道,比如说将这个用户的余额作为参数给传进去,或者只读主库。秒杀的那个例子中,你可以不要自己的手机,去用朋友的手机。
顺序一致性
顺序一致性弱于严格一致性。对变量的写操作不一定要在瞬间看到,但是,不同处理器对变量的写操作必须在所有处理器上以相同的顺序看到,这里处理器再分布式系统中可以换成不同的节点。
这里我们又再回到Zookeeper到底是什么一致性?有很多面试题都会问到Zookeeper是CP还是AP呢?很多人都会回答到Zookeeper是CP,其实这个回答并不是很严谨的,我们从线性一致性中知道CAP中的一致性指的是线性一致性,那我们就可以说Zookeeper是线性一致性的吗?答案是否定的。当我们写入一个值的时候,会交由Leader去处理,Zab协议只需要保证半数从节点成功即可,那么就会有节点的数据是老的数据,这样客户端就有可能读出的数据并非是最新的从而破坏了线性一致性。
Zookeeper其实实现的是顺序一致性,在ZK中利用zxid(ZooKeeper Transaction Id),实现了整体顺序一致性,当然也可以认为Zookeeper的的写是线性一致性,读是顺序一致性。从节点通过zxid顺序的接收leader的广播,所以ZK不能保证所有的信息马上看到,但是最终都会看到。当然Zookeeper其实可以实现线性化,在ZK中有一个sync()命令,只要我们每次读的时候都去调用sync()强制同步数据,那么我们都能保证其是最新的。
顺序一致性是由Lamport(Paxos算法的作者)提出的,最开始只用来定义多处理内存的一致性,在Lamport的《How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs》中其定义了什么是顺序一致性:
the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program.
这句话的大致意思是多处理器的执行效果和单个处理器的执行效果是一样的,每个独立的处理器的操作都会按照指定的顺序出现在操作队列。这个最开始是用于并发编程的,但是让多处理器的执行变得和单处理器的确是没啥作用,后来就用于分布式系统当中。在ZK中所有的写操作都会交给Leader节点去做,并且所有操作的更新都会根据zxid的顺序进行更新,这里就是上面所说的指定的顺序,这个队列就是按照zxid的顺序。
因果一致性
因果一致性是弱于顺序一致性的一致性模型,顺序一致性要求所有的操作的顺序都必须按照某个单个处理器(节点)的顺序,而因果一致性只需要满足有因果关系的操作是顺序一致性即可。
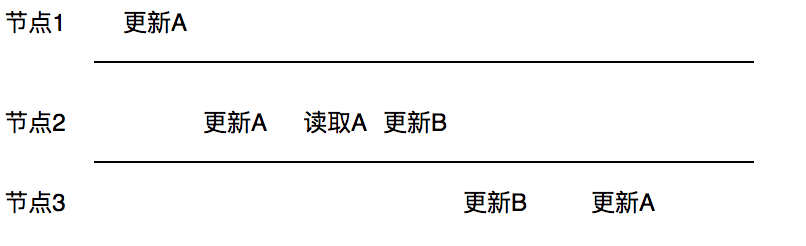
怎么理解因果关系呢?简单来说如果有人问你一个问题,那么你给出答案,这两个就是因果关系,但如果你给出答案再问题之前,那么这个就违反了因果关系。 举个简单的例子如果节点1更新了数据A,节点2读取数据A,并更新数据B,这里的数据B有可能是根据数据A计算出来的,所有具备因果关系,但是如果节点3看到的是先更新的B,再更新的A那么就破坏了因果一致性。
处理器一致性
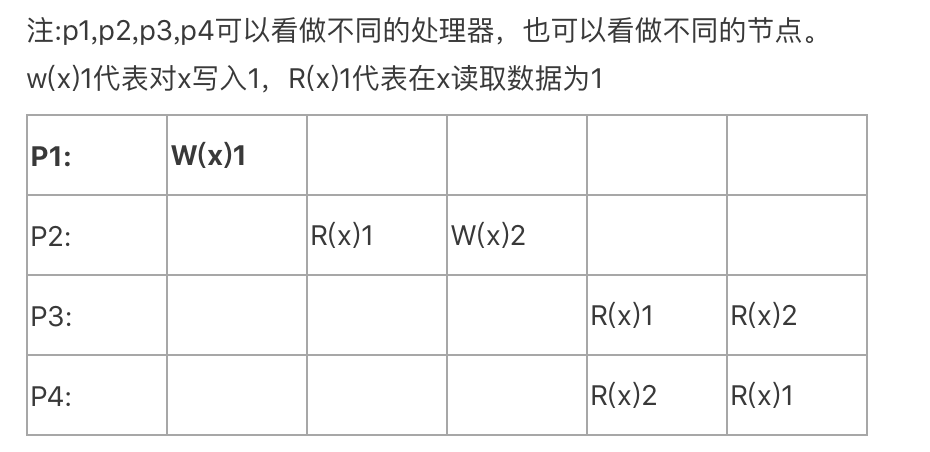
处理器一致性是更加弱的一致性模型,他只需要保证处理器看到某个处理器或者多个不同处理对相同位置的写入都是一致的。不需要考虑因果关系,而是对同一个内存或者同一个数据更新需要看到一致的顺序。
FIFO一致性
FIFO一致性是比处理器一致性还更加弱的一种,它不需要保证对相同位置的写入是一致的。 是指在一个处理器上完成的所有写操作,将会被以它实际发生的顺序通知给所有其它的处理器;但是在不同处理器上完成的写操作也许会被其它处理器以不同于实际执行的顺序所看到。这个在分布式系统中反映了网络中不同节点的延迟可能是不相同的。为了说明其和处理器一致性不同有如下例子:
最终一致性
其实除了强一致以外,其他的一致性都可以看作为最终一致性,只是根据一致性不同模型的不同要求又衍生出了很多具体一致性模型。当然最简单的最终一致性,是不需要关注中间变化的顺序,只需要保证在某个时间点一致即可。只是这个某个时间点需要根据不同的系统,不同业务再去衡量。再最终一致性完成之前,有可能返回任何的值,不会对这些值做任何顺序保证。
BASE理论中的E就是最终一致。
一致性模型有什么用
上面介绍了这么多一致性模型,我们了解到越强的一致性他的约束条件就越多,如果我们实现的话成本那么也就会越大。可以看见ZK如果想实现完全的线性一致性,那么他就需要随时都调用sync()去进行同步数据。
再我们真实的场景中我们数据库的主从复制模型(通过binlog复制也是顺序一致性),从库的很大作用就是为了缓解主库的读压力,如果我们想盲目的达到线性化一致性,那么就必须去访问主库,这样我们的从库的意义就微乎其微了。
所以根据不同的系统的模型,不同的业务要求,我们对于一致性的要求是不同的,所以我们了解这些一致性的模型是有很多必要的。
总结
这篇文章主要是介绍了什么是一致性,包括很多一致性模型,这里少讲了两个一致性事务一致性和应用一致性,有兴趣的可以阅读分布式事务。还有一个值得一提的是,谈到一致性其实就离不开共识,因为当数据副本有多个的时候,到底选择谁,如何选择才是正确的,这个有兴趣的同学可以自行查阅一些资料,比如Raft,Paxos和Zab等。
最后也再给大家几个问题:
- ZK到底是一致性模型?
- Mysql主从是什么一致性模型?
- Mysql主主是什么一致性模型?
- 你常用的一致性模型是什么?
最后这篇文章被我收录于JGrowing-CaseStudy篇,一个全面,优秀,由社区一起共建的Java学习路线,如果您想参与开源项目的维护,可以一起共建,github地址为:github.com/javagrowing… 麻烦给个小星星哟。
欢迎留言和我讨论,当然最好是关注我的公众号和我一起探讨哦,如果大家觉得这篇文章对你有帮助,你的关注和转发是对我最大的支持,O(∩_∩)O:

参考文档:
-
如何理解Zookeeper的顺序一致性:blog.csdn.net/cadem/artic…
-
How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs,Lamprot
-
Operational Characterization of Weak Memory Consistency Models:mp.weixin.qq.com/s/gg4q_53ei…
-
Designing Data-Intensive Applications, Martin Kleppman
