


推荐系统直接学习小码哥iOS底层原理班---MJ老师的课确实不错,强推一波。
CPU和GPU
CPU(Central Processing Unit,中央处理器)
- 对象的创建和销毁
- 对象属性的调整
- 布局计算
- 文本的计算和排版
- 图片的格式转换和解码
- 图像的绘制(Core Graphics)
GPU(Graphics Processing Unit,图形处理器)
- 纹理的渲染 用来就是用来给屏幕展示的数据格式
协作工作
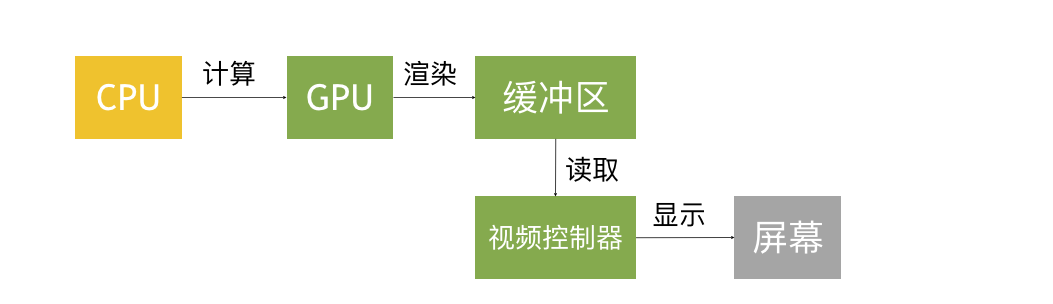
- CPU负责计算位置、大小、颜色等等一系列参数
- GPU负责将数据进行渲染后放入缓冲区备用
- 控制器从缓冲区读取数据并展示到屏幕上
- 在iOS中是双缓冲机制,有前帧缓存、后帧缓存。可以提高渲染效率
屏幕成像原理

显示器将要展示一页数据
- 发送VSync
- 从上至下依次发出HSync逐行进行填充
- 循环步骤1
卡顿产生的原因
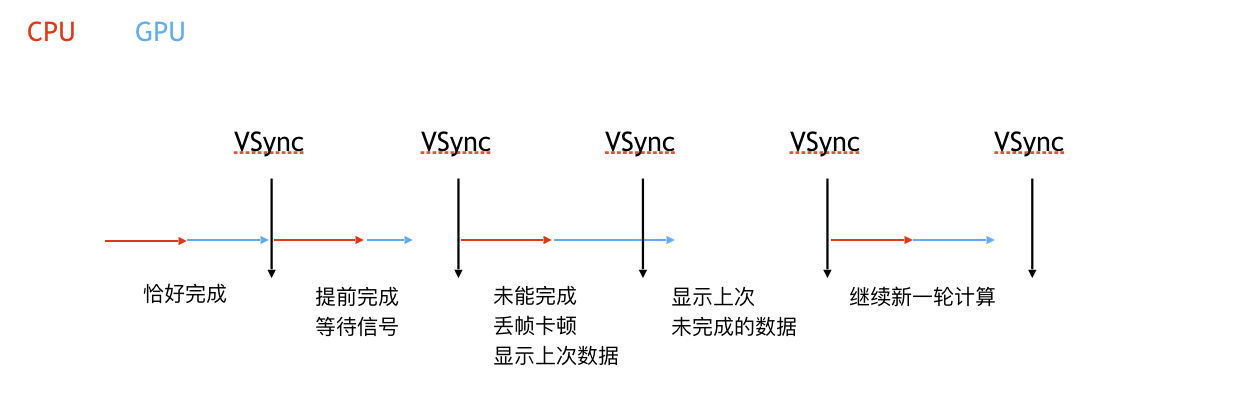
VSync信号
- 会将缓冲区的数据显示到屏幕上
- 马上让CPU和GPU开始下一帧的处理
60FPS
按照60FPS的刷帧率,每隔16ms就会有一次VSync信号
卡顿优化 - CPU
-
尽量用轻量级的对象
比如用不到事件处理的地方,可以考虑使用CALayer取代UIView
-
不要频繁地调用UIView的相关属性
比如frame、bounds、transform等属性,尽量减少不必要的修改
-
尽量提前计算好布局
在有需要时一次性调整对应的属性,不要多次修改属性
-
Autolayout会比直接设置frame消耗更多的CPU资源
-
图片的size最好刚好跟UIImageView的size保持一致
减少ImageView对图片的伸缩操作
-
控制一下线程的最大并发数量
-
尽量把耗时的操作放到子线程
充分利用多核优势
文本处理(尺寸计算、绘制)
图片处理(解码、绘制)
[UIImage imageNamed:@"timg"]加载出来的图片是未解码的,当UIImageView需要被展示的时候才会由CPU进行解码操作。而这个解码操作默认在主线程进行。我们可以将解码操作转移到异步。
- (void)image
{
UIImageView *imageView = [[UIImageView alloc] init];
imageView.frame = CGRectMake(100, 100, 100, 56);
[self.view addSubview:imageView];
self.imageView = imageView;
dispatch_async(dispatch_get_global_queue(0, 0), ^{
// 获取CGImage
CGImageRef cgImage = [UIImage imageNamed:@"timg"].CGImage;
// 获取图片信息
CGImageAlphaInfo alphaInfo = CGImageGetAlphaInfo(cgImage) & kCGBitmapAlphaInfoMask;
BOOL hasAlpha = NO;
if (alphaInfo == kCGImageAlphaPremultipliedLast ||
alphaInfo == kCGImageAlphaPremultipliedFirst ||
alphaInfo == kCGImageAlphaLast ||
alphaInfo == kCGImageAlphaFirst) {
hasAlpha = YES;
}
// bitmapInfo
CGBitmapInfo bitmapInfo = kCGBitmapByteOrder32Host;
bitmapInfo |= hasAlpha ? kCGImageAlphaPremultipliedFirst : kCGImageAlphaNoneSkipFirst;
// 获取图片大小size
size_t width = CGImageGetWidth(cgImage);
size_t height = CGImageGetHeight(cgImage);
// 创建图形上下文
CGContextRef context = CGBitmapContextCreate(NULL, width, height, 8, 0, CGColorSpaceCreateDeviceRGB(), bitmapInfo);
// 将图片绘制到上下文中
CGContextDrawImage(context, CGRectMake(0, 0, width, height), cgImage);
// 获取解码后的获取CGImage
cgImage = CGBitmapContextCreateImage(context);
// 将解码后的CGImage包装成UIImage
UIImage *newImage = [UIImage imageWithCGImage:cgImage];
// 释放资源
CGContextRelease(context);
CGImageRelease(cgImage);
// back to the main thread
dispatch_async(dispatch_get_main_queue(), ^{
//回到主线程设置图片
self.imageView.image = newImage;
});
});
}
卡顿优化 - GPU
- 尽量减少视图数量和层次 每一个View都需要被计算并渲染
- 尽量避免短时间内大量图片的显示 每张图片都需要被单独渲染,尽可能将多张图片合成一张进行显示
- GPU能处理的最大纹理尺寸是4096x4096 一旦超过这个尺寸,就会占用CPU资源进行处理,所以纹理尽量不要超过这个尺寸
- 减少透明的视图(alpha<1) 不透明的就设置opaque为YES
- 尽量避免出现离屏渲染
离屏渲染
在OpenGL中,GPU有2种渲染方式
-
On-Screen Rendering:
当前屏幕渲染,在当前用于显示的屏幕缓冲区进行渲染操作
-
Off-Screen Rendering:
离屏渲染,在当前屏幕缓冲区以外新开辟一个缓冲区进行渲染操作
为什么会使用离屏渲染
当使用某些效果时,图层的效果处理起来很费时,有可能超过16.67ms导致丢帧。系统会在当前屏幕的缓冲区之外另开辟一个缓冲区去预合成。
在VSync(垂直脉冲)信号作用下,视频控制器每隔16.67ms就会去帧缓冲区(当前屏幕缓冲区)读取渲染后的数据;但是有些效果被认为不能直接呈现于屏幕前,而需要在别的地方做额外的处理,进行预合成。
当使用圆角,阴影,遮罩的时候,图层属性的混合体被指定为在未预合成之前(下一个VSync信号开始前)不能直接在屏幕中绘制,所以就需要屏幕外渲染。
你可以这么理解. 老板叫我短时间间内做一个app.我一个人能做,但是时间太短,所以我得让我朋友一起来帮着我做.(性能消耗: 也就是耗 你跟你朋友之间沟通的这些成本,多浪费啊).但是没办法 谁让你做不完呢.
离屏渲染消耗性能的原因
-
需要创建新的缓冲区
-
频繁的切换缓冲区
离屏渲染的整个过程,需要多次切换上下文环境,先是从当前屏幕(On-Screen)切换到离屏(Off-Screen);等到离屏渲染结束以后,将离屏缓冲区的渲染结果显示到屏幕上,又需要将上下文环境从离屏切换到当前屏幕
哪些操作会触发离屏渲染?
-
光栅化
layer.shouldRasterize = YES
-
遮罩
layer.mask
-
圆角
同时设置layer.masksToBounds = YES、layer.cornerRadius大于0 考虑通过CoreGraphics绘制裁剪圆角,或者叫美工提供圆角图片
-
阴影,layer.shadowXXX
如果设置了layer.shadowPath就不会产生离屏渲染
-
富文本效果
卡顿检测
平时所说的“卡顿”主要是因为在主线程执行了比较耗时的操作
可以添加Observer到主线程RunLoop中,通过监听RunLoop状态切换的耗时,以达到监控卡顿的目的。
通常是监听Runloop被唤醒到休眠之前这段时间的时长,连续超过阀值一定次数就打印当前主线程的堆栈。
MJ里的项目是LXDAppFluecyMonitor
耗电
主要来源
- CPU处理,Processing
- 网络,Networking
- 定位,Location
- 图像,Graphics
耗电优化
-
尽可能降低CPU、GPU功耗
-
少用定时器
-
优化I/O操作
尽量不要频繁写入小数据,最好批量一次性写入
读写大量重要数据时,考虑用dispatch_io,其提供了基于GCD的异步操作文件I/O的API。用dispatch_io系统会优化磁盘访问
数据量比较大的,建议使用数据库(比如SQLite、CoreData)
- 网络优化
减少、压缩网络数据
如果多次请求的结果是相同的,尽量使用缓存
使用断点续传,否则网络不稳定时可能多次传输相同的内容
网络不可用时,不要尝试执行网络请求
让用户可以取消长时间运行或者速度很慢的网络操作,设置合适的超时时间
批量传输,比如,下载视频流时,不要传输很小的数据包,直接下载整个文件或者一大块一大块地下载。如果下载广告,一次性多下载一些,然后再慢慢展示。如果下载电子邮件,一次下载多封,不要一封一封地下载
- 定位优化
如果只是需要快速确定用户位置,最好用CLLocationManager的requestLocation方法。定位完成后,会自动让定位硬件断电
如果不是导航应用,尽量不要实时更新位置,定位完毕就关掉定位服务
尽量降低定位精度,比如尽量不要使用精度最高的kCLLocationAccuracyBest
需要后台定位时,尽量设置pausesLocationUpdatesAutomatically为YES,如果用户不太可能移动的时候系统会自动暂停位置更新
尽量不要使用startMonitoringSignificantLocationChanges,优先考虑startMonitoringForRegion:
- 硬件检测优化
用户移动、摇晃、倾斜设备时,会产生动作(motion)事件,这些事件由加速度计、陀螺仪、磁力计等硬件检测。在不需要检测的场合,应该及时关闭这些硬件
APP的启动
冷启动 && 热启动
APP的启动可以分为2种
-
冷启动(Cold Launch):从零开始启动APP
-
热启动(Warm Launch):APP已经在内存中,在后台存活着,再次点击图标启动APP
启动时间的优化
APP启动时间的优化,主要是针对冷启动进行优化
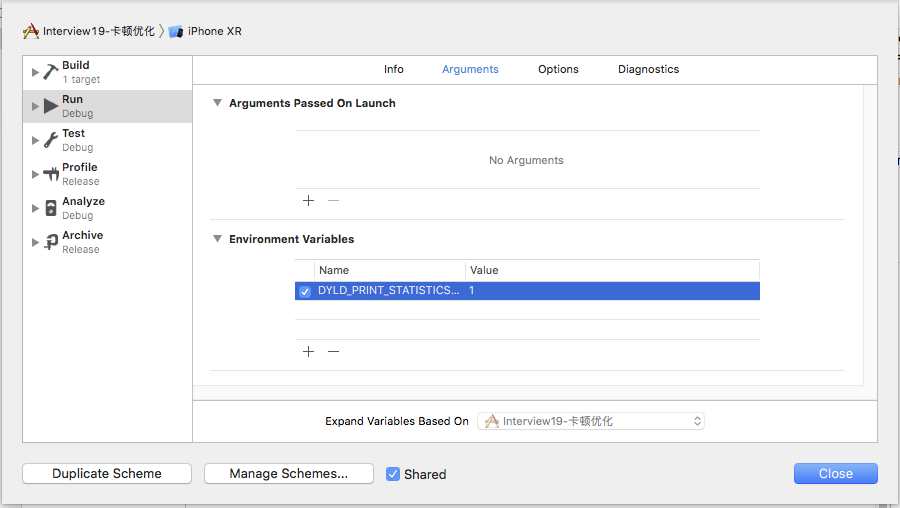
冷启动时间分析
通过添加环境变量可以打印出APP的启动时间分析(Edit scheme -> Run -> Arguments) DYLD_PRINT_STATISTICS设置为1 如果需要更详细的信息,那就将DYLD_PRINT_STATISTICS_DETAILS设置为1
total time: 1.4 seconds (100.0%)
total images loaded: 257 (0 from dyld shared cache)
total segments mapped: 764, into 103339 pages with 7230 pages pre-fetched
total images loading time: 720.70 milliseconds (48.1%)
total load time in ObjC: 71.93 milliseconds (4.8%)
total debugger pause time: 539.08 milliseconds (36.0%)
total dtrace DOF registration time: 0.12 milliseconds (0.0%)
total rebase fixups: 2,519,273
total rebase fixups time: 635.12 milliseconds (42.4%)
total binding fixups: 283,078
total binding fixups time: 36.50 milliseconds (2.4%)
total weak binding fixups time: 0.52 milliseconds (0.0%)
total redo shared cached bindings time: 52.57 milliseconds (3.5%)
total bindings lazily fixed up: 0 of 0
total time in initializers and ObjC +load: 31.39 milliseconds (2.0%)
libSystem.B.dylib : 2.92 milliseconds (0.1%)
libBacktraceRecording.dylib : 3.50 milliseconds (0.2%)
CoreFoundation : 1.74 milliseconds (0.1%)
Foundation : 2.02 milliseconds (0.1%)
libMainThreadChecker.dylib : 18.89 milliseconds (1.2%)
total symbol trie searches: 132606
total symbol table binary searches: 0
total images defining weak symbols: 20
total images using weak symbols: 61
冷启动
APP的启动由dyld主导,将可执行文件加载到内存,顺便加载所有依赖的动态库
并由runtime负责加载成objc定义的结构
所有初始化工作结束后,dyld就会调用main函数
APP的冷启动可以概括为3大阶段
-
dyld
Apple的动态链接器,可以用来装载Mach-O文件(可执行文件、动态库等)
装载APP的可执行文件,同时会递归加载所有依赖的动态库
当dyld把可执行文件、动态库都装载完毕后,会通知Runtime进行下一步的处理
-
runtime
调
用map_images进行可执行文件内容的解析和处理在
load_images中调用call_load_methods,调用所有Class和Category的+load方法进行各种objc结构的初始化(注册Objc类、初始化类对象等等)
调用C++静态初始化器和
__attribute__((constructor))修饰的函数到此为止,可执行文件和动态库中所有的符号(Class,Protocol,Selector,IMP,…)都已经按格式成功加载到内存中,被runtime 所管理
-
main
安装包瘦身
安装包(IPA)主要由可执行文件、资源组成
资源(图片、音频、视频等)
-
采取无损压缩
-
去除没有用到的资源:
可执行文件瘦身
- 编译器优化 Strip Linked Product、Make Strings Read-Only、Symbols Hidden by Default设置为YES
去掉异常支持,Enable C++ Exceptions、Enable Objective-C Exceptions设置为NO, Other C Flags添加-fno-exceptions
-
利用AppCode(www.jetbrains.com/objc/) 检测未使用的代码:
菜单栏 -> Code -> Inspect Code
-
编写LLVM插件检测出重复代码、未被调用的代码
