

SNIP阅读笔记
Abstract
Basic Analysis
- CNN对于尺度变换不具有鲁棒性。
- 单独在较大或较小的尺度上检测大目标和小目标较为困难。
- 数据集:训练数据集ImageNet与测试机COCO中的物体大小分布差异大(domain-shift)。
解决方法
SNIP - Scale Normalization for Image Pyramid,将目标在不同大小下的梯度信息选择性反向传播(selectively back-propogates)。
Introduction
理论依据

issues
-
通过上采样来保留good performance对于目标检测而言是至关重要的吗?为什么要把480x480的图像上采样为800x1200?我们可以用smaller strides来与训练ImageNet上的low resolution images然后fine-tune为目标数据集中的大小吗?
-
在与训练是应当将训练集中所有大小的目标都参与训练吗?还是应该只取一部分大小的,如64x64~256x256。
Improvement
- 融合multiple scales
- 只对与训练模型相似的RoI/anchors的梯度进行回传,来减小domain-shift带来的影响。
Related Work
对于目标检测任务,学习尺度变换的信息至关重要。
增加feature map的resolution
- dilated/atrous convolutions
- up-sampling:训练时1.5-2倍,测试时4倍
SDP、SSH、MS-CNN:对不同层进行独立预测。 FPN、Mask R-CNN、RetinaNet:使用金字塔表示,并将浅层信息与高层信息结合来进行预测。
缺陷: 若小目标为25x25的大小,即使up-sampling后(2倍),仍只有50x50的大小,然而通常预训练的网络中样本目标大小为224x224,因此对于检测小目标而言,feature pyramid的作用是有限的。
Image Classification at Multiple Scales
研究由于训练和测试时出入图像的分辨率(resolution)不同而引起的domain-shift效应
所涉及的模型:

实验一:Naive Multi-Scale Inference
CNN-B:将InamgeNet中的样本缩小到48x48,64x64,80x80,96x96,128x128,然后上采样至224x224来模拟不同的分辨率。
该实验模拟了训练数据的分辨率与测试数据的分辨率不同时所带来的影响,结果如下图:
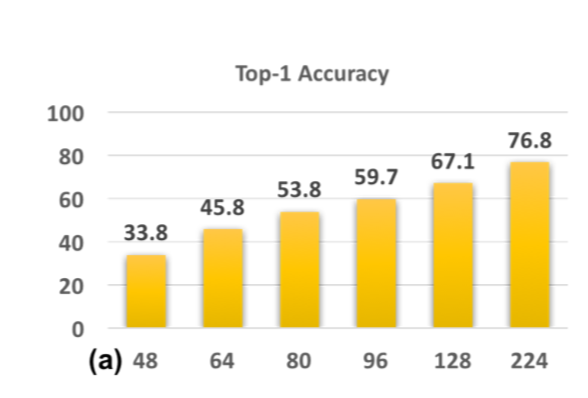
可见,在模型未训练过的分辨率上进行测试的结果会陷入局部最优(sub-optimal)。
实验二:Resolution Specific Calssifiers
在实验一的基础上,控制训练数据集与测试数据集的分辨率保持一致,仍选取5种分辨率,但各自训练不同的结构,如48x48的图像,结构中的ResNet-101的第一层修改为stride 1, kernel_size 3x3,而96x96的图像预测模型第一层为stride 2,kernel_size 5x5。
卷积层输出计算式:N = [(W - F + 2 * P) / S] + 1 N:输出维度 W:输入维度 F:kernel维度 P:padding(在SAME计算时使用)
[(48 - 3) / 1] + 1 = 46 [(96 - 5) / 2] + 1 = 46
实验结果如下:
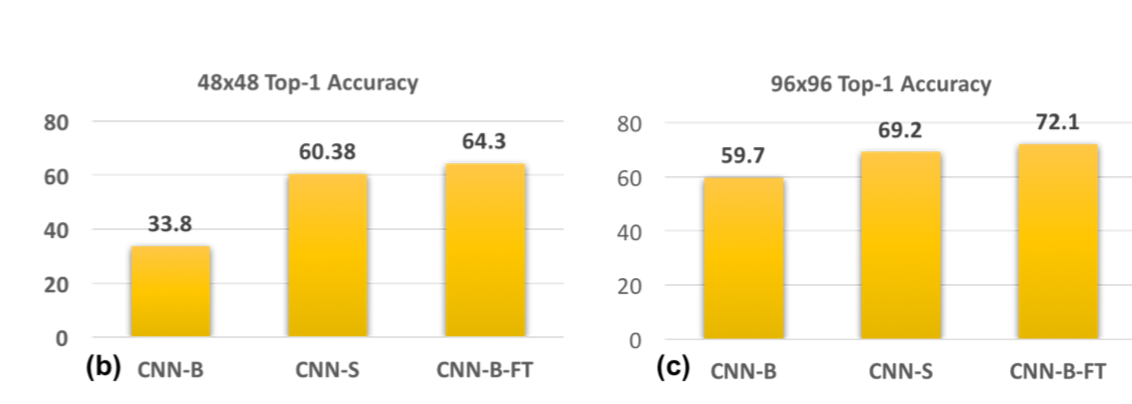
可见CNN-S的结果明显优于CNN-B,由此可得:用低分辨率的图像来训练模型,一次来检测低分辨率的目标是可行的。
实验三:Fine-tuning High-Resolution Classifiers
由放大的低分辨率图像训练得到的CNN-B模型fine-tuning后得到CNN-B-FT模型。
该实验是为了说明基于高分辨率图像训练的模型也可以有效提取低分辨率特征。同时与CNN-S比较可以看出,降低分辨率图像上采样为原先2倍,比将stride缩小一半的方法效果更好。
Data Variation or Correct Scale?

数据集:COCO 基础模型:Deformable-RFCN
这是在目标检测数据集上进行的实验,实验方式与ImageNet上的图像分类实验相似。
用低分辨率(800x1200)的图像训练,用(1400x2000)的图像测试,两种分辨率的图像均由640x480的图像产生。
实验一:Training at different resolutions
用两种分辨率(800x1400,1400x2000)下的所有目标类实体来训练检测器,记作800all和1400all。
由Table1所示,1400all的结果优于800all,这是因为1400all的训练与测试分辨率一致。

然而这种提升并不明显,作者认为,这是因为对于一些中等或大型的目标,经过放大后(640x480 ~ 1400x2000) 过大,导致无法正确区分。
因此,对于小目标检测而言,放大分辨率确实有效,但对于中大型的目标而言效果反而会变差。
实验二:Scale Specific detectors
训练一个分辨率为1400x2000的检测器,同时忽略所有80px以上的中大型目标(验证实验一的猜想),记为1400<80px。
这样得到的结果比800all更差,作者猜测是因为忽略这些中大型目标(约占30%)所带来的数据损失对模型效果影响更大。
实验三:Multi-Scale Training (MST)
用不同尺度的图像来训练检测器,理论上应该会比较不错,但据结果仍然不如800all。
作者表示,这是因为训练时那些尺寸非常大或者非常小的目标会影响训练的效果。
