

一. 生产端的可靠性投递
1. 保障消息的成功发出
2. 保障MQ节点的成功接收
3. 发送端收到MQ节点(broker)确认应答
4. 完善的消息补偿机制
在实际生产中,很难保障前三点的完全可靠,比如在极端的环境中,生产者发送消息失败了,发送端在接受确认应答时突然发生网络闪断等等情况,很难保障可靠性投递,所以就需要有第四点完善的消息补偿机制。
二、互联网大厂的解决方案
第一种:消息落库,对消息状态进行达标。具体来说就是将消息持久化到数据库并设置状态值,收到消费端的应答就改变当前记录的状态。再用轮询去重新发送没接收到应答的消息,注意这里要设置重试次数。
第二种:消息的延迟投递,做二次确认,回调检查。
三、消息落库,对消息状态进行打标
消息落库的流程图
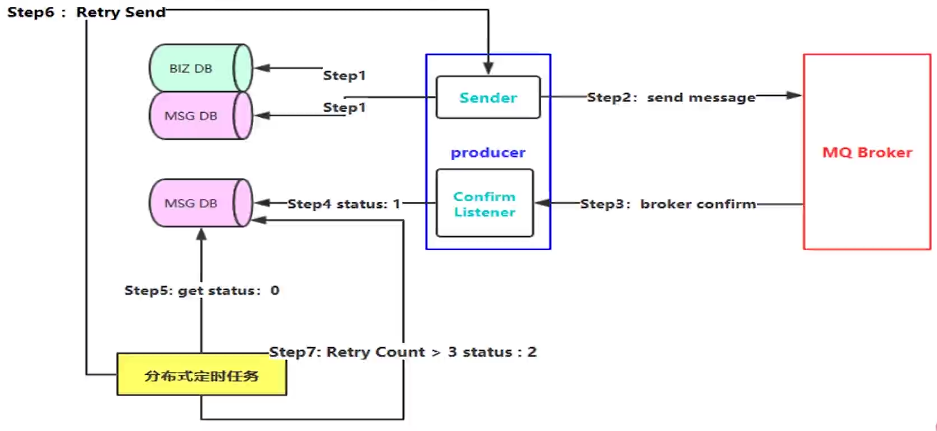
对业务数据和消息入库完毕就进入 setp2,发送消息到 MQ 服务上,按照正常的流程就是消费者监听到该消息,就根据唯一 id 修改该消息的状态为已消费,并给一个确认应答 ack 到 Listener。如果出现意外情况,消费者未接收到或者 Listener 接收确认时发生网络闪断,接收不到,这时候就需要用到我们的分布式定时任务来从 msg 数据库抓取那些超时了还未被消费的消息,重新发送一遍。重试机制里面要设置重试次数限制,因为一些外部的原因导致一直发送失败的,不能重试太多次,要不然会拖垮整个服务。例如重试三次还是失败的,就把消息的 status 设置成 2,然后通过补偿机制,人工去处理。实际生产中,这种情况还是比较少的,但是你不能没有这个补偿机制,要不然就做不到可靠性了。
要看代码实现的可以去看看我的这个系列:www.jianshu.com/c/c1785aa6c…
四、延迟投递,做二次确认,回调检查。
回想第一种方案,生产端既要对业务数据入库,又要对消息数据入库,这种设计在高并发场景下,真的合适吗?在核心链路上,每一次持久化都是需要很精心考量的,持久化一次就花费 100 - 200 毫秒,这在高并发场景下是忍受不了的。这时候需要我们的第二种方案了,流程图如下。
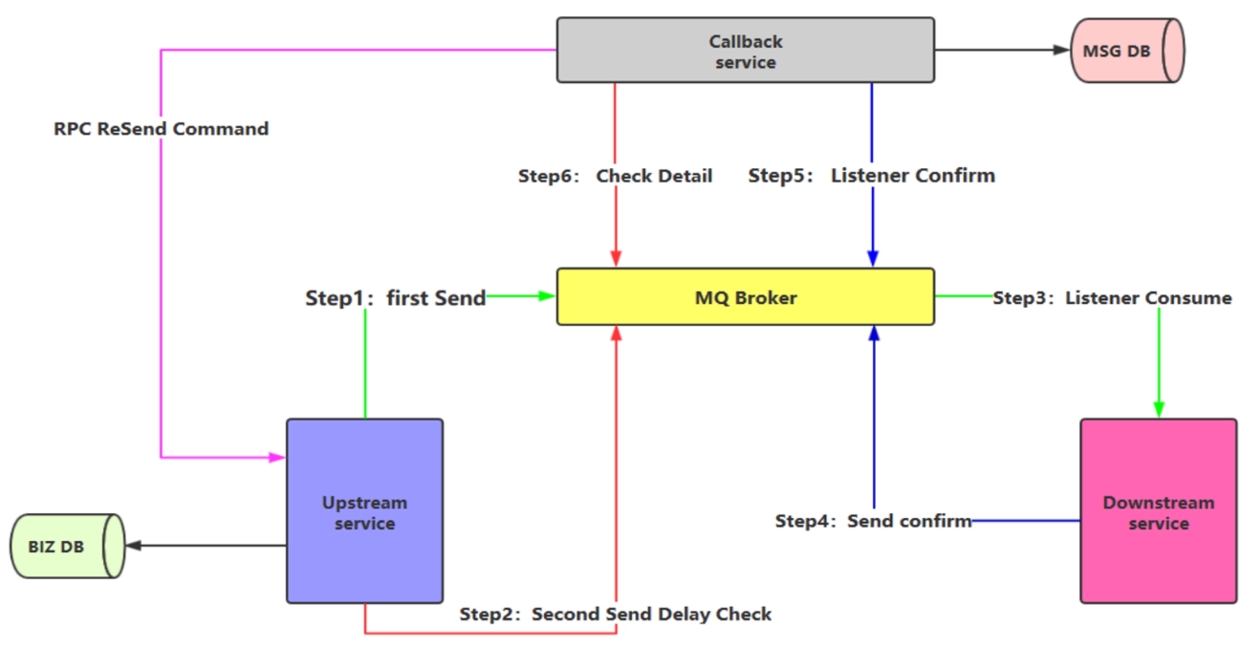
upstream Server 就是我们的上游服务,也就是生产者,生产者将业务数据入库成功后,生成两条消息,一条是立即发送出去给到下游服务 downstream Server的,一条是延迟消息给到 补偿服务 callback Server的。
正常情况下,下游服务监听到这个即时的消息,会发送一条消息给到 callback Server,注意这里不是采用第一种方案里面的返回 ack 方式,而是发送了一条消息给回去。
callback Server 监听到这个消息,知道了刚才有一条消息消费成功了,然后把这个持久化到数据库中,当上游服务发送的延迟消息到达 callback Server 时,callback Server 就会去数据库查询,刚才下游服务是否有处理过这个对应的消息,如果其 msg DB 里面有这个记录就说明这条消息是已经被消费了,如果不存在这个记录,那么 callback Server 就会发起一个 RPC 请求给到上游服务,告诉上游服务,你刚才这个消息没发送成功,需要重新发送一遍,上游服务就重新发送即时和延迟的两条消息出去,按照之前的流程继续走一遍。
虽然第二种方案也是无法做到 100% 的可靠传递,在特别极端的情况,还是需要定时任务和补偿机制进行辅助的。但是第二种方案的核心是减少数据库操作,这个点很重要!
在高并发场景下,我考虑的不是百分百的可靠性了,而是考虑可用性,性能能否扛得住这个流量,所以我能减少一次数据库操作就减少一次。我上游服务减少了一次数据库操作,我的服务性能相对而言就提高了一些,而且又能把异步 callback Server 补偿服务解耦出来。
五、结论
这两种方案都是可行的,需要根据实际业务来进行选择,大型的超高并发的场景会选择第二种方案,普通的就采用第一种即可。
