

全篇思想:
递归的本质是栈的读取
以下都是基于10000条子节点数据作对比
先看效果对比:
递归组件实现tree:渲染速度 13.75s -1.56s = 12.19s递归版tree,渲染速度: 12.19s,点击节点处理速度: 9.52s
优化版tree,渲染速度: 0.49s,点击节点处理速度: 0.18s
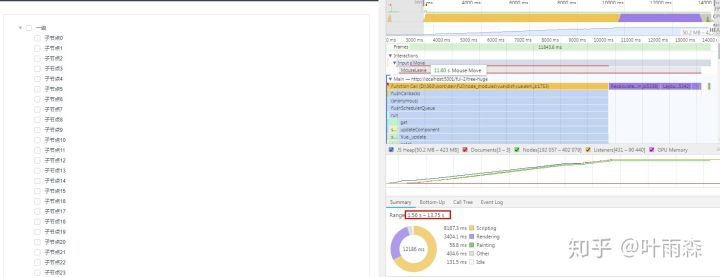
递归组件版tree性能图-1
递归组件版tree点击节点性能分析图:点击节点处理速度: 9.64s - 0.117s = 9.523s ≈ 9.52s
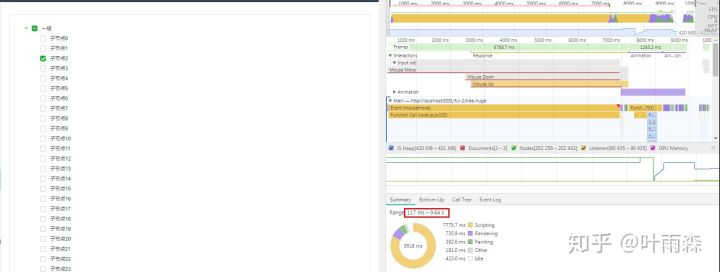
优化版tree: 渲染速度2.54s - 2.05s = 0.49s
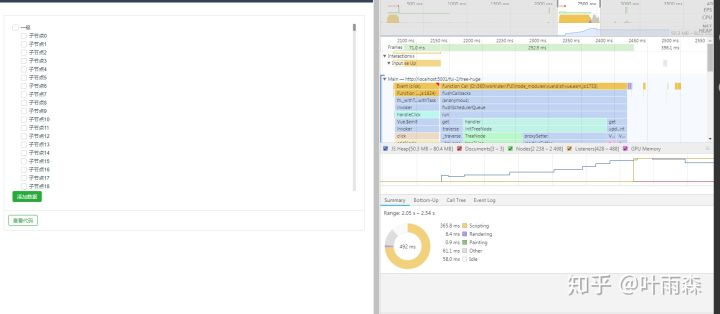
优化版tree点击节点性能分析图:点击节点处理速度2.53s - 2.35s = 0.18s
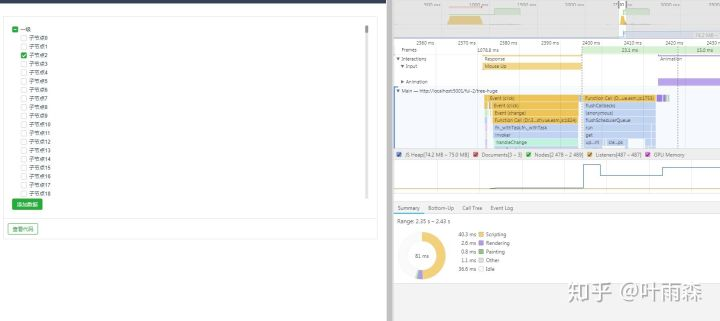
最终对比是:
递归版tree,渲染速度: 12.19s,点击节点处理速度: 9.52s
优化版tree,渲染速度: 0.49s,点击节点处理速度: 0.18s
分析问题
我们可以借助performance分析一下递归组件的耗时点所在,上递归组件渲染的性能分析:
1、script耗时分析:
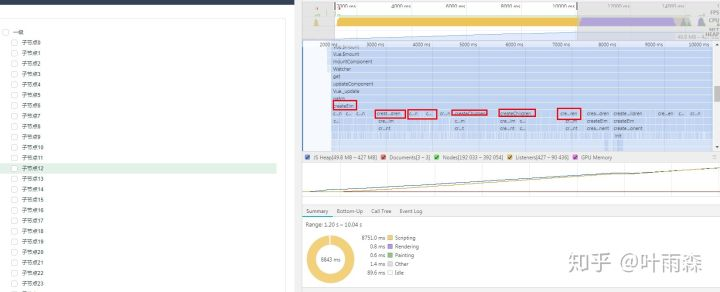
通过图-1性能瀑布可以清晰的看到script执行占了8.9s的时间,通过上图即图-5可以看到script的的调用栈主要集中在创建vue实例时的createChildren上面。
2、render耗时分析:
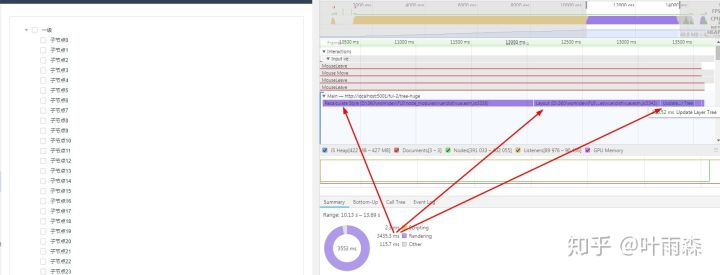
通过上图即图-6可以清晰的看到render耗时主要集中在Recalculate Style、Layout上面。我们知道Recalculate Style、Layout主要是样式计算,因此查看代码:
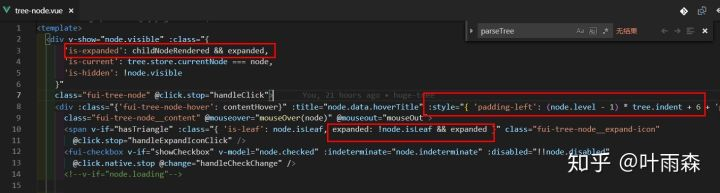
发现在递归的tree-node组件里面有很多样式的计算,10000条子节点就需要计算10000次。
3、DOM结构分析:
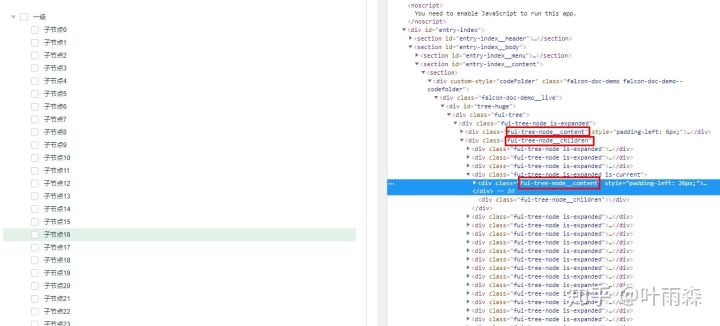
由上图即图-8我们可以看出递归组件生成的DOM结构也相应是嵌套的结构,因此DOM不仅有纵向的结构也同时有嵌套层次的结构,因此这时控制DOM的数量很难。
由上面的script、render、DOM结构的分析,可以看出问题症结所在:创建vue实例过多!
因此我们如果要优化,那么只要减少vue实例的创建,那么问题就得到了解决,因此接下来来看是如何实现的。
实现思想
来看我们的开篇思想:
递归的本质是栈的读取
在算法中我们会遇到很多递归实现的案例,所有的递归都可以转换成非递归实现,其中转换的本质是:递归是解析器(引擎)来帮我们做了栈的存取,非递归是手动创建栈来模拟栈的存取过程。
万物都是相通的,递归组件也可以转换成扁平数组来实现:
1、更改DOM结构成平级结构,点击节点以及节点的视觉样式通过操作总的list数据去实现
2、然后使用虚拟长列表来控制vue子组件实例创建的数量。
优化版实现
主要分为两部分功能:
1、tree数据和DOM结构的扁平化
2、虚拟长列表控制DOM渲染数量
1、tree数据和DOM结构的扁平化
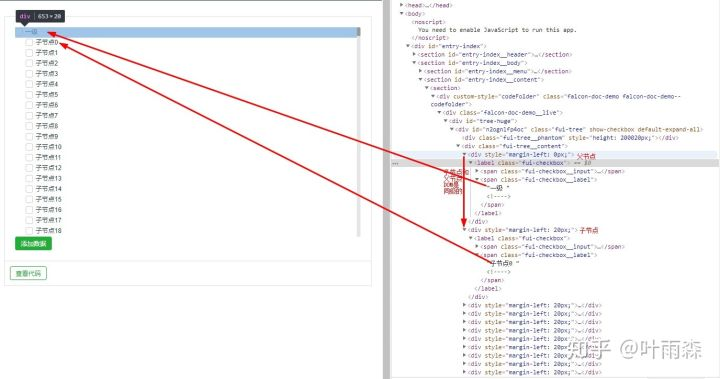
由上图我们可以看到经过改造之后的tree的DOM结构,父节点和子节点是平级的,在操作子节点时去操作内存中的listData数据来改变相关联节点的状态。
我们再看下listData数据的结构,:
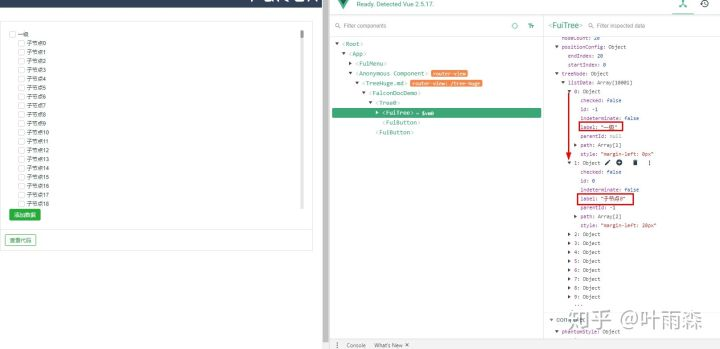
上图即图-10结合图-9的DOM结构可以对整个功能的实现逻辑一目了然:
listData中的每一项的style、checked、path等信息来描述节点的样式位置和状态,操作一个节点时通过listData更改相关节点的状态样式等信息。
因此最终来写我们的代码:
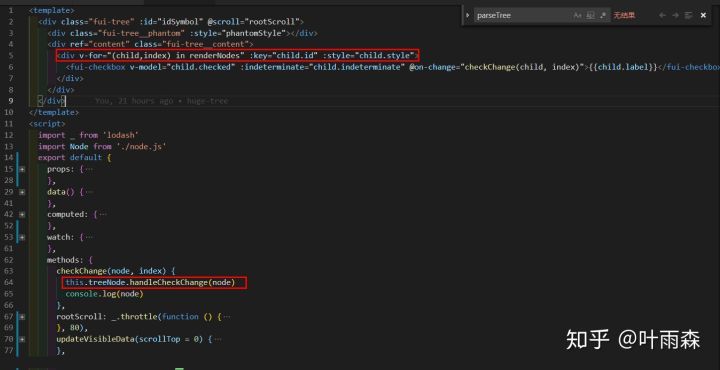
我们再看下handleCheckChange的做了什么:
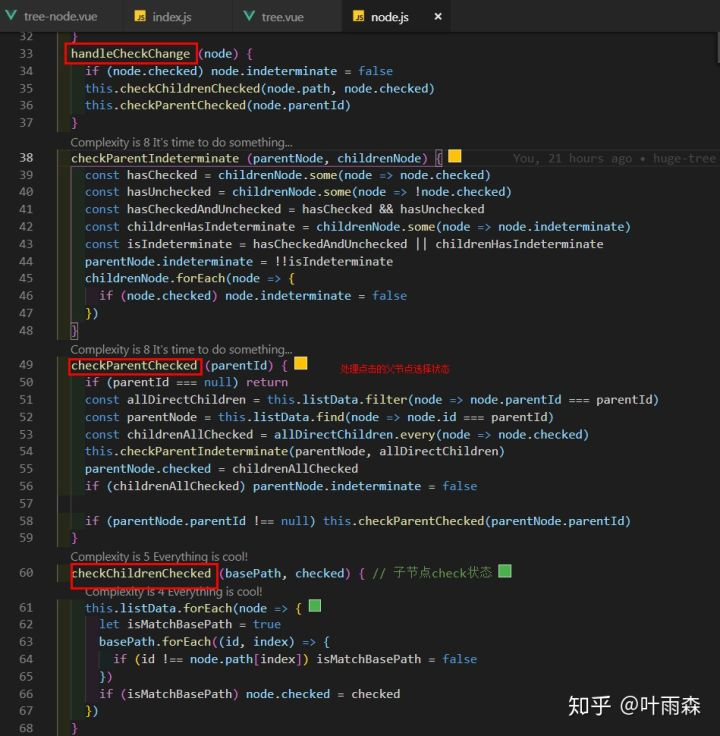
handleCheckChange 处理了父节点和子节点的check和半选状态,一切都是操作的listData中的数据。
现在我们是把所有listData都通过循环渲染出来,其实我们可以只渲染可视区的节点数据。
listData数据的扁平化及DOM的扁平化为接下来我们接入虚拟长列表的功能提供了可能。
2、虚拟长列表控制DOM渲染数量
实现思路:
根节点DOM分成两个子节点:fui-tree__phantom 和 fui-tree__content
两个子节点都是绝对定位,为了在滚动时避免数据的更改回头触发滚动事件
根节点解两个子节点css:
.fui-tree {
height: 400px;
overflow: auto;
position: relative;
}
.fui-tree__phantom {
position: absolute;
left: 0;
top: 0;
right: 0;
z-index: -1;
}
.fui-tree__content {
left: 0;
right: 0;
top: 0;
position: absolute;
}
然后我们通过滚动条的位置来计算我们应该要取哪些数据。
主要代码:
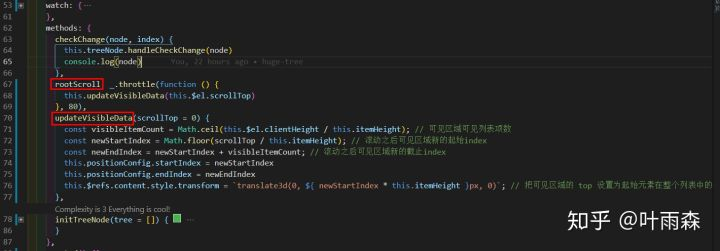
通过startIndex、endIndex可以取出我们需要循环的数据列表renderNodes:
computed: {
renderNodes() {
if (!this.treeNode) return []
return this.treeNode.listData.slice(this.positionConfig.startIndex, this.positionConfig.endIndex)
},
phantomStyle() {
return {
height: this.allListLen * 20 + 'px'
}
}
}
结合图-11的v-for,这样我们在渲染时的dom数量是固定的条数,如下图:
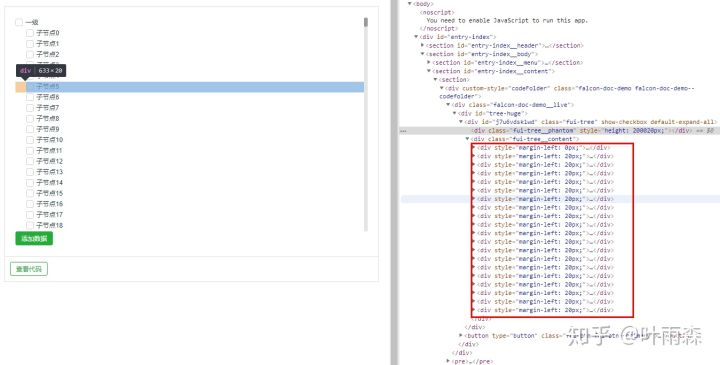
虚拟列表的接入可以让即使再多数据量也能渲染固定的DOM数量,这样就可以支撑更大数据的渲染和功能。
以上我们实现了业务需求的大数据渲染,目前测试可支撑到20w条节点,点击子节点时会有肉眼可见的延迟,主要是图-12中handleCheckChange的数据查找和处理,这块还有一定的优化空间:使用字典树存储节点相关信息,字典树和扁平数组listData的每一个元素指向同一个内存地址,在handleCheckChange中通过操作字典树来达到操作listData的元素的效果,经典的空间换时间的案例。
欢迎关注叶雨森的知乎专栏:zhuanlan.zhihu.com/p/55528376
参考:
