

你是否有过这样的经历,文件在别人电脑上看着好好的,但是拷贝到自己的电脑上就发现乱码了。或者作为程序员的你,打开别人的代码时,发现中文注释乱码了,而代码缺一点毛病都没有。我曾经也被这些问题困扰许久,虽然很多时候转换一下字符编码问题就解决了,但是背后的原因却一直缕不顺。因此,想借这篇文章,尽可能把这件事情给说清楚。
字符编码的起源-ASCII码
计算机存储数据都是以二进制的形式进行存储的,但是二进制形式人类是无法直接解读的。因此,对于保存在计算机上的文本数据,需要一张映射表实现二进制与文字之间的相互转换。比如,可以约定0000 0001代表字母A,0000 0002代表字母B,因此当你保存一段文本ABA时,实际上计算机存储的是0000 0001 0000 0002 0000 0001。相应的,当你打开这个文件时,本质读取的二进制数据,但是编辑器会将这段二进制码查表转换成ABA。
计算机问世的早期,有这样一张映射表被建立作为编解码的标准,称为ASCII码。
百花齐放-多字符集
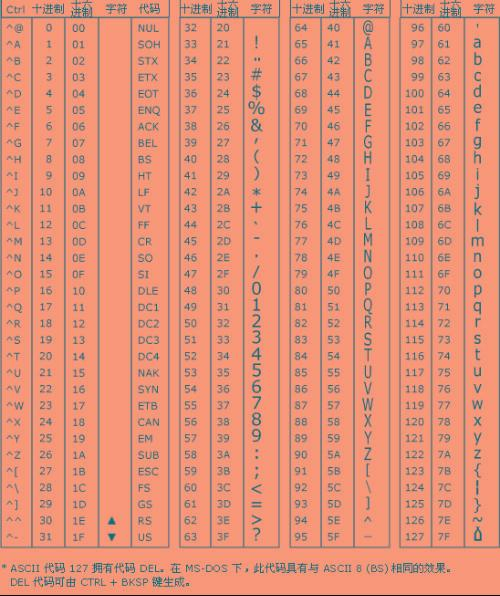
对于拉丁语系国家而言,他们可以扩展ASCII码的第8个bit位来满足本国的编码需求,但是对于非拉丁语系的国家而言,单字符集(只用了一个字节完成编码的称为单字符集,对应的就是多个字节编码的成为多字符集)无法满足编码本国语言的需求,因此他们用多个字节来表示一个文字。例如,我们国家就是使用的双字节字符编码,使用最为广泛的就是GB2312编码。但是GB2312只能编码简体中文,因此出现了GBK编码,GBK编码除了支持简体中文,还支持繁体中文以及日语、韩语等的编码,是大一统的编码。
GBK的编码规则 GBK编码使用1-2个字节进行编码,GBK编码分为很多个码页,每个码页的范围编码的范围都是一个字节,即0x00-0xFF。GBK编码先通过第一个字节查询第一张表(如下图)。
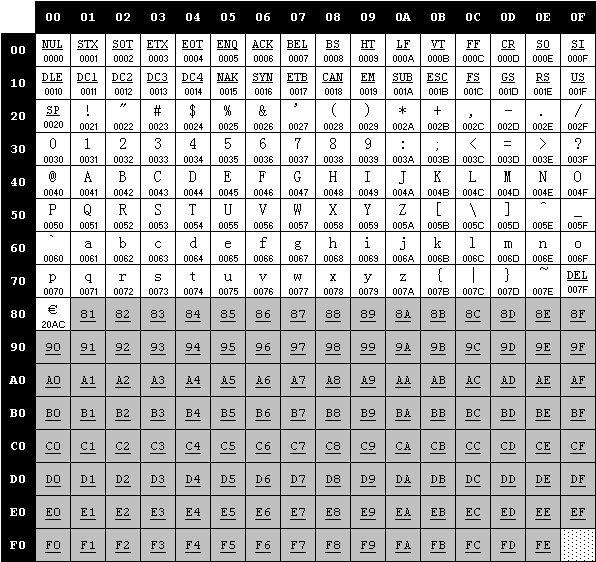
如果第一个字节的首位为0,也就是范围在0x00-0x80之间时,直接从该表中查询得到对应的字符,和传统的ASCII码查询的方式相同。例如百分号%的编码就是0x25。
如果第一个字节的首位为1,也就是范围在0x81-0xFF之间时,先查询该表得到第二个字节需要查询的编码页的页码号。例如汉字丏的编码为8144,第一个字节先查询到要查第0x81编号的页码,然后在0x81编号的页码中查询编码为0x44的对应的文字就是丏。
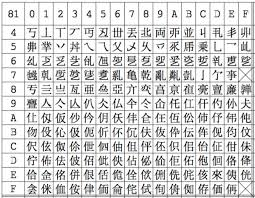
由于各国都有自己的编码,而且编码的方式还很多,规则的不统一导致,文本转化中会很麻烦,因此制定了ANSI标准,各国指定标准的多字符集编码方式,例如我国的标准编码就是GB2312。
全球一统-UNICODE
由于各国都制定了本国的多字节的字符编码,导致全球范围内的字符字符编码集非常多,这会使得各国之间文字转换非常的麻烦。因此大佬们坐下约定了一个全球统一的编码,用一个编码表示全世界所有的文字的,这就是UNICODE编码。UNICODE编码是两个字节,因此可以编码256*256个字符,这基本可以满足全球字符编码的需求了。
我们以汉字的汉为例,其Unicode编码为\u6c49,\u用来标识其为Unicode编码,由0x6c和0x49组成。用两个字节表示,那么就有先后顺序的问题,6c49和496c两种方式都能表示,因此两种不同顺序的编码的编码方式称为大端和小端模式
Unicode实际上还是一个比较广义的概念,在实际编码规则中常见的有UCS-2,UTF-16,UTF-8。接下来我们分别阐述这几种编码的概念。
UCS-2与UTF-16
UCS-2是Unicode编码的标准实现,所有的字符都是按照两个字节编码。两个字节的顺序不同就产生了USC-2大端和USC-2小端两种模式。但是UCS-2只编码了BMP字符,而UTF16则常用变长的方式来兼容其他字符,最短两个字符。BMP字符UTF16和UCS-2是相同的,扩展的部分则用四个字节编码。
UTF-8
终于到了我们最熟悉的UTF-8了。Unicode编码出现后,使用拉丁文的国家发现自己吃了大亏,他们认为拉丁文原本只需要一个字节就可以编码,现在却需要两个字节,因此搞出了变长的UTF-8字符。
UTF-8的编码规则
[1] UTF-8是变长度的,长度为1-6个字节;
[2] 第一个字节的连续的二进制位值为1的个数决定了其编码的位数
[3] 如果第一个字节以0开头说明是单个字节的字符
[4] 对于非单个字节的字符,出首字节外,其余均已10开头
上面的规则用编码表示更加清晰,如下:
| 占用字节 | 首字节大小 | 完整表示 |
|---|---|---|
| 1字节 | 大于0 | 0xxxxxxx |
| 2字节 | 大于0xc0 | 110xxxxx 10xxxxxx |
| 3字节 | 大于0xe0 | 1110xxxx 10xxxxxx 10xxxxxx |
| 4字节 | 大于0xf0 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 5字节 | 大于0xf8 | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 6字节 | 大于0xfc | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
根据这个编码规则,就可以判断出一个字符串是由多少个字符组成,C++代码如下:
inline std::string GetHideName(const std::string& sUtf8Data)
{
std::vector<std::string> vName;
std::string ch;
for (size_t i = 0, len = 0; i != sUtf8Data.length(); i += len)
{
unsigned char byte = (unsigned)sUtf8Data[i];
if (byte >= 0xFC) // lenght 6
len = 6;
else if (byte >= 0xF8)
len = 5;
else if (byte >= 0xF0)
len = 4;
else if (byte >= 0xE0)
len = 3;
else if (byte >= 0xC0)
len = 2;
else
len = 1;
ch = sUtf8Data.substr(i, len);
vName.push_back(ch);
}
std::string sQxName;
if (vName.size() <= 2)
{
sQxName = vName.size() > 0?(vName.front() + "*"):sUtf8Data;
}
else
{
sQxName = vName.front() + "**" + vName.back();
}
return sQxName;
}
问题
[1] GBK与GB2312的区别? GBK是GB2312的超集,你可以简单这样理解,GB2312编码的是简体中文,而GBK在GB2312的基础上增加了繁体字以及日语和韩语。因为GBK是在GB2312的基础上进行扩展的,所以简体中文用这两者是相同的编码。
