

前言
在分布式领域,有一个十分令人头疼的问题,那就是分布式的追踪,日志与监控。因为服务部署在不同的主机上,而实际的业务开发中,服务之间相互调用,尤其是伴随着服务微小化,单位化,微服务架构的趋势下服务数量激增 即便是有着良好的前期规划,但是中大型项目在实际开发中,依然会面临着服务关系错综复杂,问题追踪调试困难的等等问题
现状
各类trace解决方案
那这个令人头疼的问题,是否已经有良好的解决方案了呢?答案是肯定确又是否定的... 目前商用规模的分布式追踪方案主要有以下几类:
- 非OpenTacing标准的分布式追踪系统
- 采用ServiceMesh架构的服务网格治理方案
- envoy
- istio ...
- 基于OpenTraing标准的嵌入式分布式追踪系统
- zipkin
- jaeger
- skywalking ...
第1类是采用非标准化的追踪系统,一般为针对单一业务系统设计实现,不具备广泛通用性和持续维护性
第2类是从架构层考虑使用服务网格治理的方案来进行分布式追踪,优点是功能强大,控制纬度广,追踪精度细,追踪覆盖面大。但是缺点也很明显,目前无论是第一代以envoy为代表的解决方案的ServiceMesh,还是第二代以istio为代表的ServiceMesh,都极为重量,需要专门的架构和运维团队进行细致的前期安排和规划后方能实施,部署成本高昂
第3类是采用OpenTracing标准的分布式追踪系统,OpenTracing是CNCF(大名鼎鼎的Cloud Native Computing Foundation)为了规范业界的分布式跟踪系统产品的统一范式,设计的trace标准,基于该标准,可以解决分布式追踪系统跨平台和兼容通用的问题。目前twitter、uber、apple等知名企业完全遵循该标准设计trace系统。
各大厂商trace系统对比
分布式跟踪系统各类产品,根据设计目标和标准形成综合对比*(资料来源于互联网,非权威)*:
| 产品名称 | 厂商 | 开源 | OpenTracing标准 | 侵入性 | 应用策略 | 时效性 | 决策支持 | 可视化 | 低消耗 | 延展性 |
|---|---|---|---|---|---|---|---|---|---|---|
| jaeger | uber | 开源 | 完全支持 | 部分侵入 | 策略灵活 | 时效性高, UDP协议传输数据(在Uber任意给定的一个Jaeger安装可以很容易地每天处理几十亿spans) | 决策支持较好,并且底层支持metrics指标 | 报表不丰富,UI比较简单 | 消耗低 | jaeger比较复杂,使用框架较多,比如:rpc框架采用thrift协议,不支持pb协议之类。后端存储比较复杂。但经过uber大规模使用,延展性好 |
| zipkin | 开源 | 部分支持 | 侵入性强 | 策略灵活 | 时效性好 | 决策一般(功能单一,监控维度和监控信息不够丰富。没有告警功能) | 丰富的数据报表 | 系统开销小 | 延展性好 | |
| CAT | 大众点评 吴其敏 | 开源 | - | 侵入性强 | 策略灵活 | 时效性较好,rpc框架采用tcp传输数据 | 决策好 | 报表丰富,满足各种需求 | 消耗较低 , 国内很多大厂都在使用 | - |
| Appdash | sourcegraph | 开源 | 完全支持 | 侵入性较弱 | 采样率支持(粒度:不能根据流量采样,只能依赖于请求数量);没有trace开关 | 时效性高 | 决策支持低 | 可视化太弱,无报表分析 | 消耗方面。不支持大规模部署, 因为appdash主要依赖于memory,虽然可以持久化到磁盘,以及内存存储支持hash存储、带有效期的map存储、以及不加限制的内存存储,前者存储量过小、后者单机内存存储无法满足 | 延展性差 |
| MTrace | 美团 | 不开源 | - | - | - | - | - | - | - | - |
| CallGraph | 京东 | 不开源 | - | - | - | - | - | - | - | - |
| Watchman | sina微博 | 不开源 | - | - | - | - | - | - | - | - |
| EagleEye | 淘宝 | 不开源 | - | - | - | - | - | - | - | - |
| skywalking | 华为 吴晟 | 开源 | 完全支持 | 侵入性很低 | 策略灵活 | 时效性较好 | 由于调用链路的更细化, 但是作者在性能和追踪细粒度之间保持了比较好的平衡。决策好 | 丰富的数据报表 | 消耗较低 | 延展性非常好,水平理论上无限扩展 |
综合上分布式追踪系统对比
1. jaeger对于go开发者来说,可能比较合适一些,但是入手比较困难。它的rpc框架采用thrift协议,现在主流grpc并不支持。后端丰富存储,社区正在积极适配
2. appdash对于go开发者想搭建一个小型的trace比较合适,不适合大规模使用
3. zipkin项目,github很活跃,star数量很多,属于java系。很多大厂使用
4. CAT项目也属于java系, github不活跃,已不太更新了。不过很多大厂使用,平安、大众点评、携程...
5. skywalking项目, 也属于java系。目前已成为Apache下的项目了,github活跃,作者也非常活跃,当当、华为正在使用。
6. appdash项目,go语言开发,因为可视化过于简单、且完全内存存储,不太适合大规模项目使用。
以上除了闭源的分布式追踪系统,jaeger和zipkin还有skywalking是开源中不错的选择,但是,可能读者也发现了,以上的分布式追踪系统,对于Java平台的支持都很不错,但是对于其他平台的支持,就都比较有限了,尤其是低侵入代码的自动探针部分。而且,以上所有的分布式追踪系统,无一例外,生产部署(非简单体验)都十分复杂,有些甚至依赖于kubernetes。这让很多想要使用分布式追踪系统来解决实际问题的中小企业望而却步
我很清楚的记得在去年,我疯狂的在寻找一个开箱可生产的分布式追踪系统,于是就有了本文以上部分,最终是以失败告终,很遗憾我没有寻找到任何一款开箱可生产的开源产品。但是,路是人走出来的嘛,既然已经有了OpenTracing的标准,那理论上任何人和任何组织都可以实现一套标准化的分布式追踪系统,因为产生了这个可怕的念头,于是就有了本文的下半部分——我决定造一个轮子,自行实现一套OpenTracing标准的分布式追踪系统,目标是开箱可生产
NodeTracing概览
我希望,可以在上面的表格中插入一行:
| 产品名称 | 厂商 | 开源 | OpenTracing标准 | 侵入性 | 应用策略 | 时效性 | 决策支持 | 可视化 | 低消耗 | 延展性 |
|---|---|---|---|---|---|---|---|---|---|---|
| NodeTracing | cheneyxu | 开源 | 完全支持 | 自动探针,几乎无侵入 | 策略灵活 | 时效性秒级 | 决策较好,且持续升级 | 包括服务拓扑图,跨度甘特图等在内的多种图表,且持续升级 | 消耗极低 | 无状态和关联架构,完全容器化的追踪节点,可轻松简单集群化,采用内存与LevelDB配合的持久化存储,可应对十亿以上量级的span数据 |
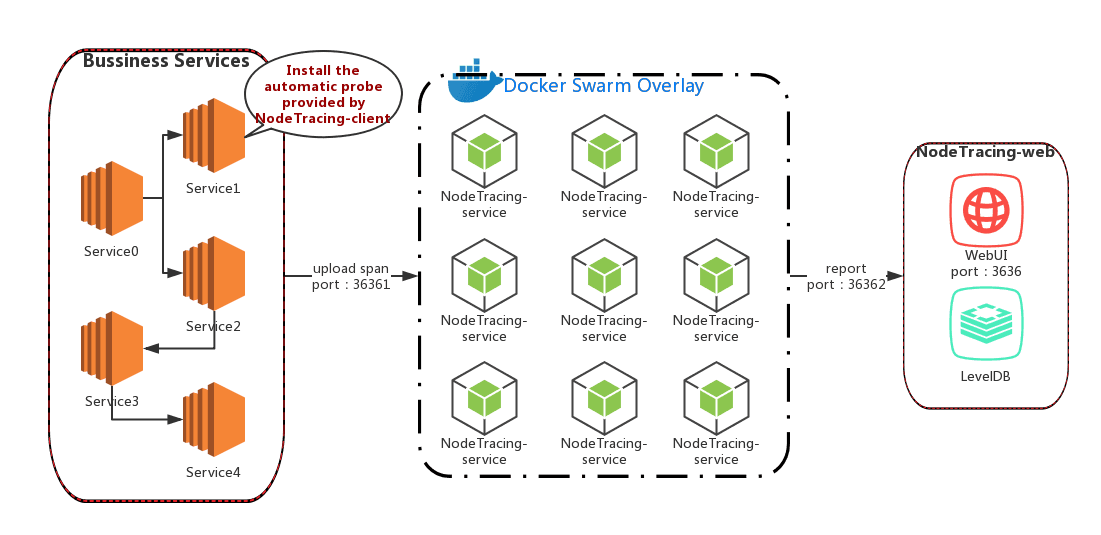
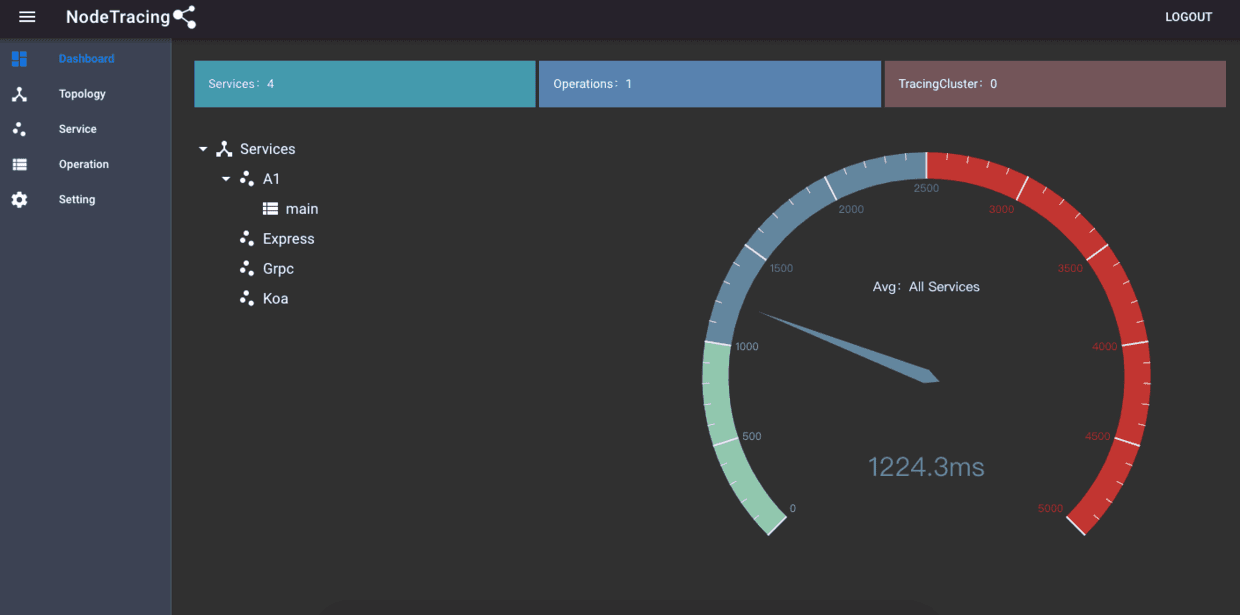
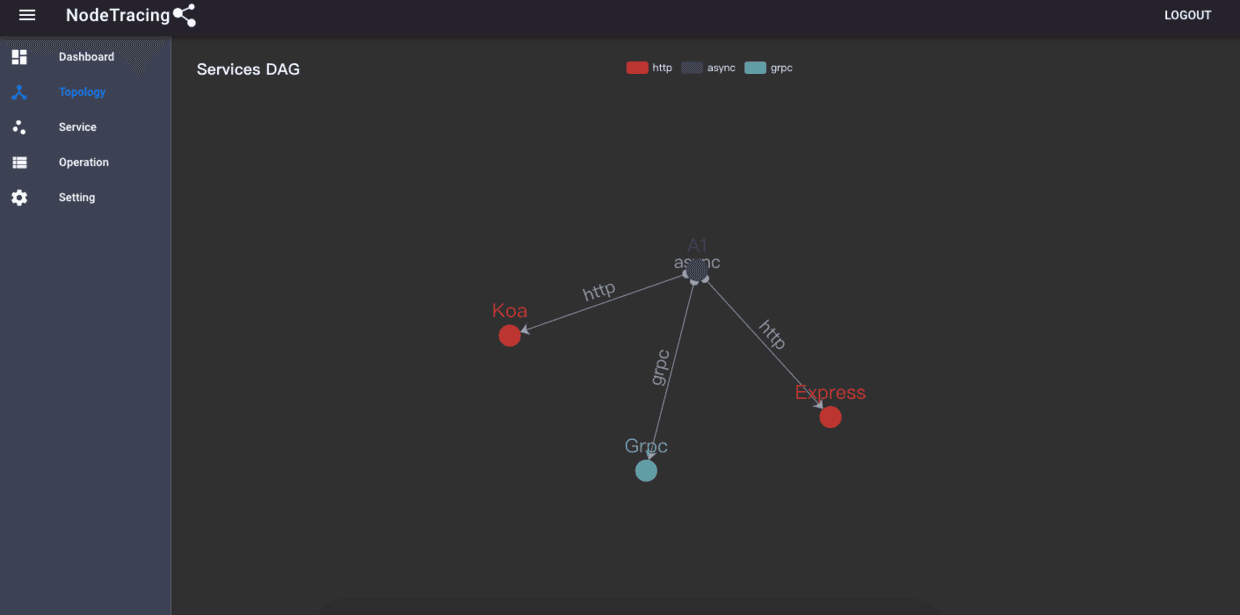
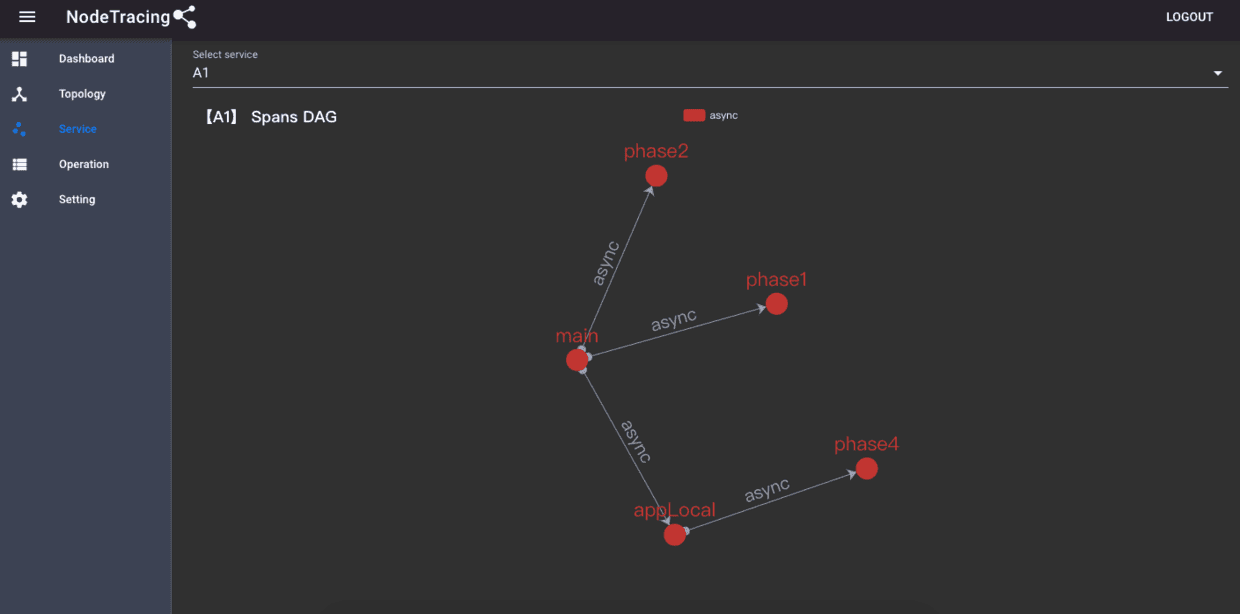
最终,包括构思,架构,开发,测试等等两个多月的时间,终于完成了NodeTracing的初个开箱可生产版本!这是至今为止我个人最满意的作品,同时也期望NodeTracing在以后可以持续进化成为至少是NodeJS领域最好的分布式追踪系统,以下是架构图和演示demo
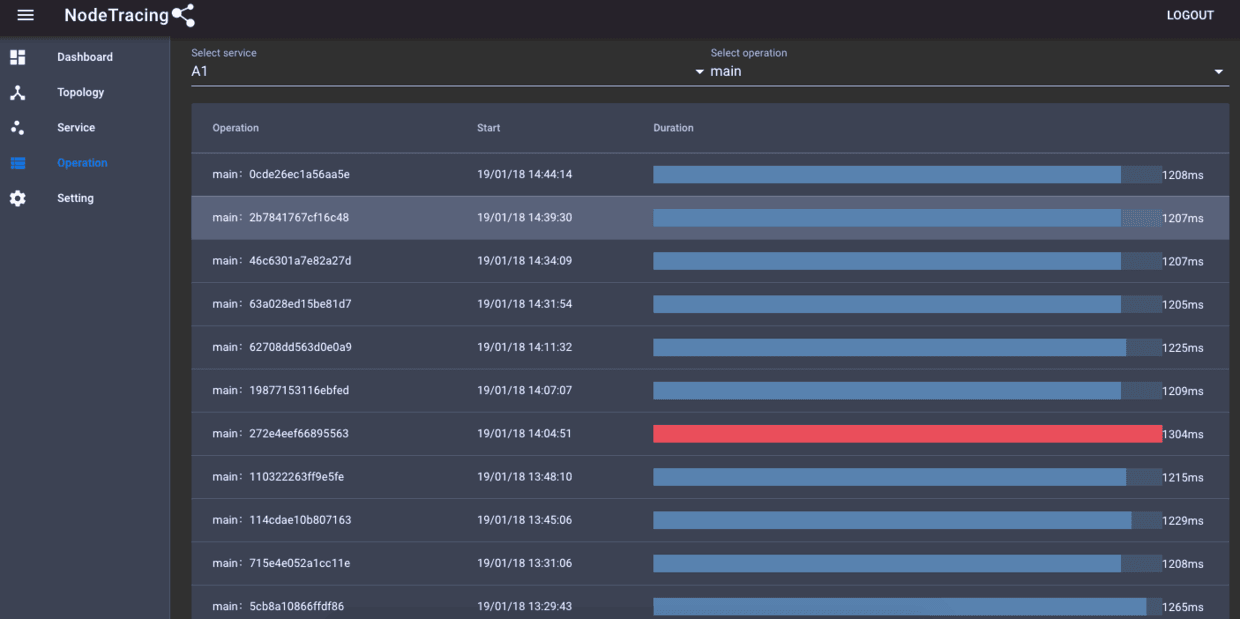
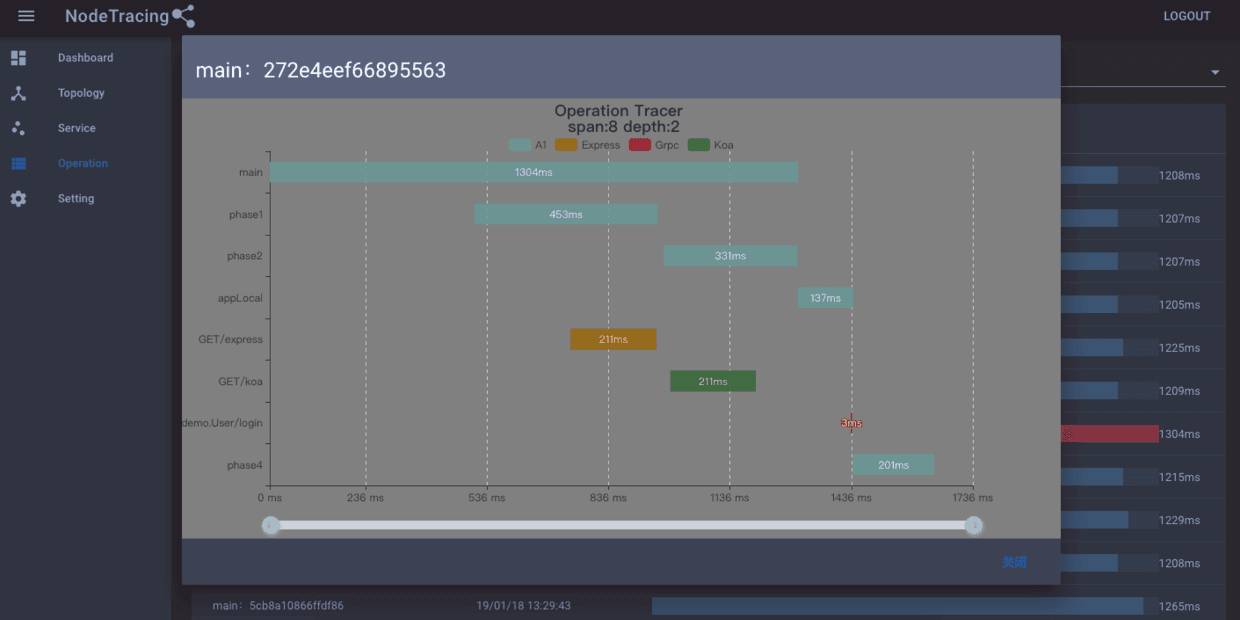
#NodeTracing使用 ##下载
git clone https://github.com/cheneyweb/nodetracing
cd nodetracing && npm i
##快速开始&单例启动
cd server && npm run standalone
##生产部署&集群启动
docker stack deploy --prune -c docker-compose.yml nodetracing
**NodeTracing的部署就是这么简单!**根据需要选择单例启动/集群启动之后,打开浏览器访问: http://localhost:3636/nodetracing/web/index.html 便可以看到系统管理页,默认帐号密码:admin/123456
##安装自动探针
npm i nodetracing
探针初始化(在应用入口首行)
const nodetracing = require('nodetracing')
const tracer = new nodetracing.Tracer({
serviceName: 'S1', // 必须,服务名称
rpcAddress: 'localhost',// 必须,后台追踪收集服务地址
rpcPort: '36361', // 可选,后台追踪收集服务端口,默认:36361
auto: true, // 可选,是否启用自动追踪,默认:false
stackLog: false, // 可选,是否记录详细堆栈信息(包括代码行号位置等,启用内存消耗较大),默认:false
maxDuration: 30000 // 可选,最大函数执行时间(垃圾回收时间间隔),默认:30000
})
由此便完成了nodetracing的加载工作,接下来您可以根据您的服务类型选择以下自动探针/手动探针...
async自动探针(支持async函数)
async function func1(){
...
}
async function func2(){
...
}
func1 = nodetracing.aop(func1)
func2 = nodetracing.aop(func2)
...
http请求自动探针(axios)
axios.interceptors.request.use(nodetracing.axiosMiddleware())
http响应自动探针(koa/express)
//koa
app.use(nodetracing.koaMiddleware())
//express
app.use(nodetracing.expressMiddleware())
grpc-client自动探针(原生)
const grpc = require('grpc')
const Service = grpc.loadPackageDefinition(...)[packageName][serviceName]
new Service("ip:port", grpc.credentials.createInsecure(), { interceptors: [nodetracing.grpcClientMiddleware()] })
grpc-server自动探针(原生)
const grpc = require('grpc')
const interceptors = require('@echo-health/grpc-interceptors')
let server = new grpc.Server()
server = interceptors.serverProxy(this.server)
server.use(nodetracing.grpcClientMiddleware())
grpc-client自动探针(x-grpc框架)
const RPCClient = require('x-grpc').RPCClient
const rpcClient = new RPCClient({
port: 3333,
protosDir: "/grpc/protos/",
implsDir: "/grpc/impls/",
serverAddress: "localhost"
})
rpcClient.use(nodetracing.grpcClientMiddleware())
rpcClient.connect()
let result = await rpcClient.invoke('demo.User.login', { username: 'cheney', password: '123456' } , optionMeta?)
grpc-server自动探针(x-grpc框架)
const RPCServer = require('x-grpc').RPCServer
const rpcServer = new RPCServer({
port: 3333,
protosDir: "/grpc/protos/",
implsDir: "/grpc/impls/",
serverAddress: "localhost"
})
rpcServer.use(nodetracing.grpcServerMiddleware())
rpcServer.listen()
实现思路
简单的使用说明之后,下面重点讲解一下整个系统的实现方案 一个分布式追踪系统,由三大部分组成,分别是探针,追踪服务,可视化服务
- 探针:嵌入与被监控追踪的服务之中,伴随服务启动而运行,需要追踪服务上下文,以及即时上报span给追踪服务
- 追踪服务:独立部署,接收探针上报的span,计算分析处理后提供给可视化服务用作数据展示
- 可视化服务:接收追踪服务的处理计算结果,可视化呈现数据报表,提供最终决策参考
实现难点
这三大部分,其实每一个部分都是难啃的骨头,根据实践下来的经验,每一部分的难点如下:
- 手动探针对代码侵入相当大,几乎很难要求开发人员时刻谨记进行探针埋点,而且手动埋点也容易出错,容易造成结果呈现不正确
- 相对于手动探针,自动探针是更好的选择,但是自动探针实现难度高,且根据实现程度,支持覆盖面有限
- 追踪服务,如何集群化部署是在架构设计时就需要考虑的,尽可能简单的部署是第一优先考虑
- 可视化服务,数据持久化方案如何选择?如何在简单部署和高性能可靠性之间平衡是难点
- 整体方案开发语言选择,高网络性能,高异步性能,低平台依赖,低部署难度是优先考虑,所以毋庸置疑,nodejs是最佳选择
设计&实现详解
NodeJS探针
OpenTracing API
首先针对探针的实现,OpenTracing的标准其实已经给出了接口,目前初版优先考虑目前尚未有成熟分布式追踪系统的nodejs平台。所以第一步需要基于opentracing-javascript实现OpenTracing的API接口 在这一步中,很遗憾OpenTracing给出的官方文档实在有限,想要完整的实现全套API,必须耐下心来阅读OpenTracing的JS源码,没有别的办法
Async Hook
在实现OpenTracing的API之后,也仅仅是完成了手动探针的实现,因为OpenTracing其实只是指定了接口标准与追踪数据标准,并没有提供自动探针的实现思路 所以,其实自动探针的实现其实是依赖于各语言平台自由的特性。不过万变不离其中,任何想要实现自动探针的语言平台,就一定要实现AOP和上下文追踪,否则几乎不可能 因为首选支持nodejs平台,所以在nodejs上实现自动探针主要会依赖两个关键技术:
- async hook
- function merging
其中,async hook是node8.x之后版本推出的异步资源追踪方案,直至今日node11.x,已经初步成熟。利用async hook可以追踪所有异步资源关系,而这正是自动探针的必备条件
不过这里需要注意的是,nodejs目前没有同步资源的追踪方案(我没有找到,如果有读者知道有的,希望能告知,不胜感激),所以,目前在nodejs中,目前仅可以对异步调用进行自动探针追踪。但是其实问题不大,因为nodejs中几乎全是异步资源,而且同步资源其实追踪意义不大
function merging主要是用于在nodejs平台中实现AOP,这里主要需要一些语法技巧来实现,AOP对于自动探针非常关键,有了AOP,才有跨服务追踪的可能
Java探针(规划中...)
追踪服务
追踪服务用于接收探针上传的span,很明显,如果追踪服务的架构设计不好,那这将会整个追踪系统的性能瓶颈。而一个APM监控系统,本身怎么性能瓶颈呢? 所以,追踪服务集群化是必然的。但是集群化一定会面临部署复杂难度高的问题,我不希望每一个使用NodeTracing的人都感概其难以部署,而且开箱可生产是制作NodeTracing的初心。 所以,在这一步的选择上,Docker Swarm是第一优先选择,Docker Swarm的极简优雅性实在令人印象深刻,这一次,我依然决定使用容器集群来解决追踪服务的性能瓶颈问题
- 首先,需求追踪服务可简单平行扩展,那就得要求每个独立服务无状态,彼此之间无关联。在这里采用的是之前自己造好的轮子x-grpc框架。这是一个独立的grpc服务框架,非常适合于这种简单快速高性能的rpc数据吞吐
- 然后,将追踪服务打包制作成镜像
- 最后,我们可以通过简单的一句docker stack命令,部署任意节点的追踪集群
可视化服务
到可视化服务这一步,已经最后的闯关了,这意味着span数据已经收集完毕,我们需要考虑如何将其持久化存储和可视化展示提供决策 在这里最后的一道门槛是持久化存储,因为大规模数据的持久化存储方案一般都是非常复杂的,单点数据库性能有瓶颈,但是如果采用类似于分布式数据库之类的方案,会极大的提高部署难度。本身用户要安装自动探针,安装追踪服务已经要花些时间了,最后还需要部署一个分布式数据库? 很明显这里的平衡取舍是难点。但是所幸最终还是找到了比较完美的解决方案,**那就是——LevelDB。这是一个谷歌实现的能支持十亿级别数据规模的kv数据库,特点是支持极高的写入吞吐。**它的作者是Jeaf Dean和 Sanjay Ghemawat,是谷歌的传奇工程师
LevelDB的发现让我很激动,因为它几乎就是为分布式追踪系统而生的,所有特效都极其符合追踪系统的持久化需求。**作为内嵌型数据库,可以跟随服务启动,无需额外部署,写入吞吐又极高。**在对LevelDB进行了基准测试后,我立马采用了它作为NodeTracing的持久化方案,因为它的性能表现实在太抢眼了
测试
在初版完成后,针对NodeTracing的span吞吐做了一些基准测试:
- 单个节点,双核i5+4G内存的追踪服务,可每秒处理一万个span(测试其实更多是受限于网络速度)
- 平行拓展到10个节点后,系统运行稳定(后续会进行更大规模节点部署测试)
- 大约平均1GB容量可以持久化存储高达四百万个span(会根据实际运行的上下文大小的不同而不同,该值仅供参考)
参考资料
- 当当11·11:高可用移动入口与搜索新架构实践
- 分布式调用跟踪系统调研笔记
- 京东分布式服务跟踪系统-CallGraph
- 全链路监控(一):方案概述与比较
- 各大厂分布式链路跟踪系统架构对比
- skywalking
- opentracing-javascript
后记
感谢你的阅读,如果本文能够给你带来帮助,希望你能在github上为NodeTracing点亮一颗Star:) 本文完成之际,NodeTracing刚刚也通过了OpenTracing的registry注册,可以前往搜索查看 本文篇幅有限,没有办法详细阐述NodeTracing所有配置和实现细节,有兴趣的读者可前往github阅读详情,也欢迎提出问题和见解
- 作者:CheneyXu
- 邮箱:457299596@qq.com
- Github:NodeTracing
- Dockerhub:NodeTracing-Image
