rotation_range:整数,数据提升时图片随机转动的角度 width_shift_range:浮点数,图片宽度的某个比例,数据提升时图片水平偏移的幅度 height_shift_range:浮点数,图片高度的某个比例,数据提升时图片竖直偏移的幅度 rescale: 重放缩因子,默认为None. 如果为None或0则不进行放缩,否则会将该数值乘到数据上(在应用其他变换之前) shear_range:浮点数,剪切强度(逆时针方向的剪切变换角度) zoom_range:浮点数或形如[lower,upper]的列表,随机缩放的幅度,若为浮点数,则相当于[lower,upper] = [1 - zoom_range, 1+zoom_range] fill_mode:‘constant’‘nearest’,‘reflect’或‘wrap’之一,当进行变换时超出边界的点将根据本参数给定的方法进行处理 cval:浮点数或整数,当fill_mode=constant时,指定要向超出边界的点填充的值 channel_shift_range: Float. Range for random channel shifts. horizontal_flip:布尔值,进行随机水平翻转 vertical_flip:布尔值,进行随机竖直翻转 rescale: 重放缩因子,默认为None. 如果为None或0则不进行放缩,否则会将该数值乘到数据上(在应用其他变换之前
2)flow_from_directory
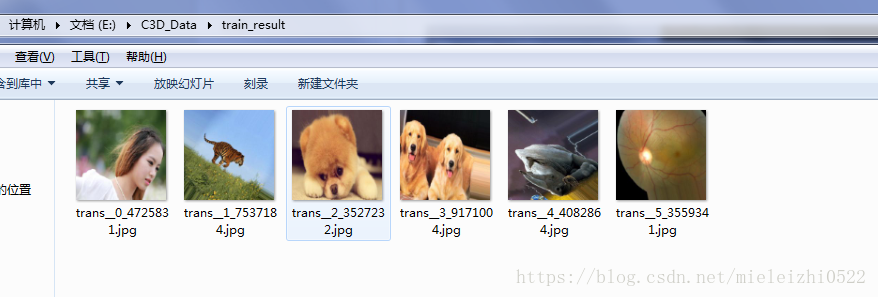
gen = datagen.flow_from_directory( path, target_size=(224, 224), batch_size=15, save_to_dir=dst_path,#生成后的图像保存路径 save_prefix='xx', save_format='jpg')
for i in range(6): gen.next() """ path:文件读入的路径,必须是子文件夹的上一级(这里是个坑,不过试一哈就懂了) target_size:图片resize成的尺寸,不设置会默认设置为(256.256) batch_size:每次输入的图片的数量,例如batch_size=32,一次进行增强的数量为32, 个人经验:batch_size的大小最好是应该和文件的数量是可以整除的关系 save_to_dir:增强后图片的保存位置 save_prefix:文件名加前缀,方便查看 save_format:保存图片的数据格式 产生的图片总数:batch_size*6(即range中的数字) """
完整代码
from keras.preprocessing.image import ImageDataGenerator