

Dragonboat是近期开源的Go实现的多组Raft库,16字节荷载的写可以持续在900万次每秒,9:1高读写比下可以持续在超千万次每秒。
详细的benchmark信息可参考github项目首页,同时也烦请大家点Star鼓励:
github.com/lni/dragonb…Dragonboat的性能是持续优化改进的结果,它从2017年年中时候的每秒10万次写,一路走来,经过数十项优化以后最终成为当前开源版本所能具备的1000万次写每秒的性能。对于同样的吞吐需求,更高效的实现意味着库本身消耗的资源将更少,能为用户应用留出的资源更多。Dragonboat在2.8GHz志强上,对于16字节荷载,平均每个CPU核心能承担超过每秒40万次写,且在测试中线性伸展至22核每秒900万次写,属于当前最高效多组Raft实现。
这里从Raft协议的实现优化角度展开,从数十项已应用的优化中,介绍几个写请求的处理中的性能优化实例。
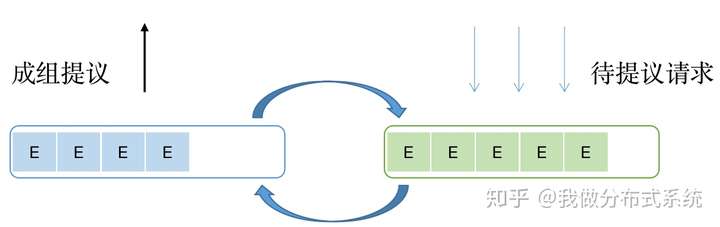
待提议的请求
当用户提交一个写请求(称为Propose,即提议)后,从性能考虑一般它并不是被立刻处理,而需要暂存。Go实现中,首先想到的多半是用channel来暂存,并通过channel将待提议的请求传递给负责处理的部分。etcd的实现正是如此:
case m := <-propc:
m.From = r.id
r.Step(m)
这样做的性能问题显而易见,每次只能从channel中取出一个请求后逐一处理。而channel是个功能丰富的内建类型,比如协程的特性决定对channel的操作甚至可以带来协程的调度。
在Dragonboat中,在处理单个请求的地方,均避免使用channel做任何数据的传递。在处理待提议请求上,使用的是由两个slice来回切换而构成的一个可以整体访问的queue,每次取出当前slice中的所有待提议请求,一次合并(batching)地完成提议。
上述是写请求,读请求的暂存也是同样的问题同样的处理。
Raft Log Entry的磁盘保存
Raft要求被commit的entry至少在过半数的机器上完成了落盘的保存,这确保只要quorum存活,磁盘上必然有所有已commit的entry。当每秒面对千万规模的Log Entry的写入,因为基数巨大,任何冗余的数据的写入都浪费磁盘空间与带宽,进而拖累延迟与吞吐性能。
以使用RocksDB等Key-Value store库来存储Raft的Log Entry库为例,对于某个Raft组而言,通常每个log entry被作为一条记录存储,它的key和value可按照如下方式决定:
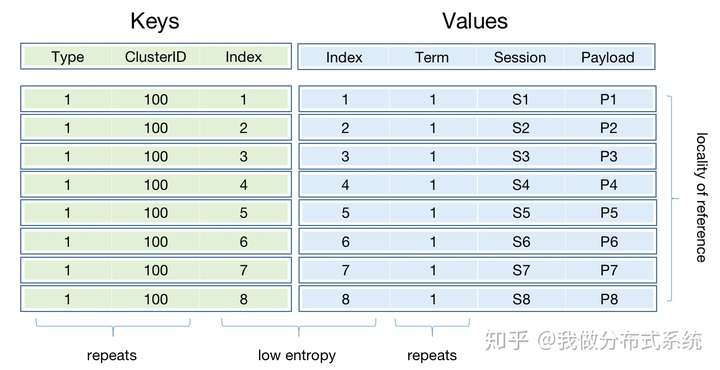
这样的简单设计的问题在于:
- Key和Value里存在大量的重复值,如上述的ClusterID和Term字段
- Key和Value里均含有大量低信息量的值,如上述Index字段,正常情况下它应该是连续递增的
- 每个 entry被设定为一个Key-Value store的记录,可被独立地读写访问。但对共识库而言,磁盘上entry的访问具有很强的访问局部性,某entry被读写以后,它下一条Log Entry很可能是接着马上要被访问。
对上述简单的设计,试想一下如需每秒1000万次写,则每秒需添加1000万条记录,内含1000万个值完全重复的ClusterID与Term记录,这必然是低效的。
以etcd为例,其WAL包负责Rafty Log Entry的保存,虽没有使用Key-Value Store,且因为单组而无需保存ClusterID,但上述三个问题etcd依然都具备。
Dragonboat中,Log Entry的存储避免上述归纳的三个问题。在Leader不变,从而Term不变Index连续递增的通常情况下,Log Entry被安排为如下形式后保存,大幅降低了空间的浪费和写入带宽的需求,对延迟的改善也很明显。

Raft Log Entry的模型
上一部分介绍了磁盘上存储Raft Log Entry,与内存内存放的Log Entry一起,根据具体哪些Log Entry被存放在内存那,哪些被存放在磁盘上,这样一个划分方法构成了Log Entry的具体存储模型。
通常的实现,比如etcd,是简单将所有Log Entry分为已落盘保存和仅在内存内两部分,如下图:
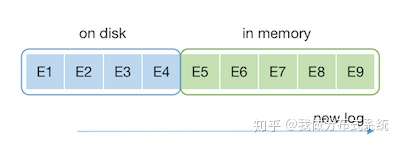
这种简单的划分最主要是根据Raft协议对Log Entry存储方式的要求,也就是Entry被多数节点保存至磁盘以后才可以被Commit并后续被执行。在这种简单设计中,一个Entry的存储方式随时间和状态的变迁如下:

问题也很明显:Entry被执行的时候,已经不在内存中了,需要从磁盘上读取,从而大幅度影响效率。etcd的用户,比如CockroachDB特地为此增加了一个LRU的cache层,以试图减小这样的读盘开销。但随之带来的,是庞大的维护这个LRU cache的性能成本支出。
Dragonboat不采用etcd式的两级Log Entry模型,而是采用一个三级的设计,确保近期马上会使用的Entry始终在内存里,且无需额外维护一个cache层,甚至无需额外的内存拷贝。
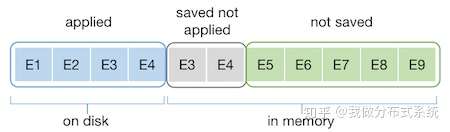
同时,如果需要,通过简单的限制最大允许内存使用量,便可避免因内存中存有太多Log Entry而使得内存使用过量的问题。待提议请求与收到的复制Log Entry的消息根据异步网络假设,均可随意丢弃,以确保限制内存用量。
数据序列化
因为是Go语言的实现,Dragonboat最初使用Google全家桶来做很多组件的实现。比如节点间通讯最初用gRPC,而数据序列化则顺理成章的使用Protobuf。显而易见的,这种选择必定是和高性能无缘了。
先从表面上看,Protobuf是一种特别慢的序列化方案,gogo protobuf在它的基础上有所改良,但依旧是很慢的。Dragonboat目前采用的是Protobuf加Colfer的混合方案,对性能敏感的类型,比如Raft的Log Entry,使用Colfer做序列化以取得更好的性能。详细的性能对比,可以参考这里。
Protobuf同时是一种allocation不友善的序列化库,其Go实现中,在Unmarshal一个含有Log Entry slice的结构体的时候,会因为slice反复扩容而反复对已Unmarshal的Log Entry做额外的拷贝搬运。针对这个问题,Dragonboat也给予了优化。
然后,上述序列化的表面问题,归根结底依旧是技术实现细节。真正的优化,必须贴合协议、算法,从原理上考虑。在一个Raft库里,序列化的最大问题是反复多次的序列化:
- Leader上的Log Entry在落盘写的时候被序列化一次,在网络发送的时候,至少被序列化一次,甚至因为发送目标的不同,而被序列化多次。
- Follower收到Leader发来的已经序列化了的Log Entry的内容,首先是将它们反序列化操作,然后落盘写的时候却又再次序列化它们。
Dragonboat将在下一阶段优化这一问题。
更多分享即将到来
下面的知乎回答包含了Dragonboat开发优化中所遇到的所有golang语言、runtime相关的性能问题。近期将对所列出的问题详细展开,逐一分析成因与解决办法。
你遇到过哪些高质量的 Go 语言面试题?版权信息
在不修改本文内容的前提下,欢迎完整转载。
本文标题图片是英国Bloodhound Car,图片版权为BBC所有。
