

引子
年初的时候,我给老板做了个承诺,今年会是我们团队的收获之年。幸不辱命,做了点微小的贡献,可以来写点总结。之所以敢夸下海口,基于三个背景:
- 随着在业务和算法上积累,以及同业界同行的交流,对未来的技术规划有了清晰的认知:Wide --> Wide & Deep --> All Deep
- 项目组成员、合作团队,大家共事很多年,互相信任,渴望做点有意思的事情,主动突破的意愿很强。老板也比较支持我们,短期KPI不是重点。
- Wide项目的超预期结果,个人的影响力在公司达到一个新的高度,很多事情的推动上很顺利。反而是自己比较克制的对待大家的信任,没有一下子把摊子铺的很大。
回到正题,年底在应老板要求,给大家做了一次关于深度学习在排序应用的一些关键性问题总结,整理下发出来。
有些内容在专栏里面已经有几篇文章谈到一些,比如训练数据量级的影响、模型结构的演化以及Tensorflow实践踩的坑等,本文将尝试谈一些自己的理解,希望不是陈词滥调,和大家探讨一二,水平有限,如有错误还望指出。
本文将由三部分组成:
1. 一些典型问题的理解
2. 未来
3. 总结
一些典型问题的理解
Embedding在学什么
万物皆可Embedding,一般我们基于用户行为日志训练Embedding,可以理解成是学习用户兴趣的表达。在这篇文章[1]有更详细的讨论。
再进一步,阿里在DIN中提到可以把Embedding向量的每个dim理解成用户不同的兴趣点,那么我们最需要关心的是Deep网络对不同兴趣点的交叉关系学习的如何。
不止一篇论文提到过Deep在cross的能力上不一定比FM之类的强,google在Latent Cross: Making Use of Context in Recurrent Recommender Systems[2] 这篇论文中,特地对比了Deep和SVD的效果,发现Deep在low rank的data上fit效率不高。
但我们实践中发现Embedding直接应用效果还是不错的,很自然的就会考虑将二者融合一把,比如DeepFM、NFM、DCN等网络。目前看起来,还是比较有希望拿到进一步收益。
神经网络需不需要特征工程
神经网络理论上号称能够拟合任意函数,但现实很残酷,我们最常用的优化算法SGD只能表示很无奈。关于这个点,大家可以参考[3]这个问题下的回答,理论和实践存在很大的gap。
可以说,CV领域是因为找到了卷积这个非常好的特征抽取器,通过加深Deep来提升感受野,使得CNN面对图像的场景在特征抽取上比人显著提高了效率。而NLP就没有这么幸运,至今还没有媲美卷积的特征抽取器,因而在应用效果上差了一截。
在搜索、推荐领域,特征工程的重要性毋庸置疑。那么深度学习有没有能力直接从原始数据中学习呢?先给结论,是可以的,但会有不少困难。首先对比CV或NLP,这边的输入数据不完整,依靠人类经验再加工补充信息给模型很有必要。
其次,这篇文章[4]提到SGD类算法的困难点,变态曲率以及收敛速度和最小的特征值有关等理论知识。我们可以不严谨的推广下,人类加入的先验特征工程,可以有效的减少Loss函数中变态曲率的case,从而更容易优化。
并且应用深度学习后,构建feature的思路不一致,建议从更high level的层面去思考特征构建,可以少做一些math类的特征trick。
为何说Deep比Wide更容易泛化
google在W&D的论文中提出,Wide更重memory而Deep更具有generation。Wide部分由于使用了大量的id类特征,其memory特性容易理解。Deep的generation特性一般都是基于它做了很多embedding,构建hidden层来学习信息,即学到了很多共享信息,更具有泛化性。
现在,让我们尝试从Deep的参数训练更新的角度来理解下。大家应该有经验,Deep对input数据的scale特别敏感,必须做好归一化。由于反向传播的梯度更新机制,不同scale的input带来的梯度变化,很容易被放大或缩小,即大家常说的gradient explosion和gradient vanish。
再进一步,除了归一化外,我们还应该关心输入数据的Smoothing。机器学习中有一个广泛使用的隐式先验,平滑先验(smoothness prior)或者局部不变性先验(local constancy prior)。这个先验表明我们学习的函数不应该在小区域内发生很大的变化。从直觉上理解,当两个样本离得近,大概率是比较像的,即small weight change cause small output change,f(x) 约等于f(x+delta)。其中KNN就是一个极端的例子。
这个先验要求我们的函数最好是smoothness的。因此,所谓的泛化(generation)特性,也可以理解成在input发生微小的变化时,output不会发生剧烈变化。我们在实践中发现,Deep模型output的score,对比Wide模型在分布上要平滑很多,线上效果也会更好。
为何塔结构这么流行
如果没有在工业界工作过的同学,大概很难想象为何类似DSSM这样的双塔结构,会这么流行。其中DSSM的原始结构如下:
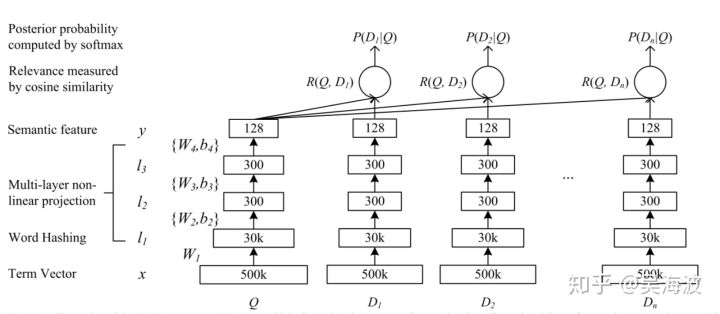
大部分公司会改成双塔,分离计算。一个塔线上计算,一个塔离线计算。
其中关键点在于计算量的考虑,召回的质量是排序效果的天花板,因此大部分公司都会让尽可能多的候选集参与召回计算。因此,召回部分的计算可能会涉及到百万级或千万级的候选集计算,无法在低延迟的线上服务做实时计算。真实场景中通过ANN的方案去融合使用,比如facebook开源的faiss方案。
当然还有很多其他解法,关键点在于保障用户表达和物料表达是在一个空间中。比如模型训练好,只用物料侧的embedding向量,用户侧的用行为数据中的物料去模拟,比如求平均,我们实践过,效果也还可以。
也有基于Youtube的做法,在召回模型中变成一个多分类问题,将最后一层的softmax层的参数理解成物料侧的embedding,转化对物料侧空间的矩阵分解:m = u * v,其中u是最后一个hidden层,v是softmax连接层的参数。更多细节参考这篇文章[5]
但总体看,双塔结构清晰,以cosine的距离loss来保障在用户和物料在同一空间,容易上手。
No Free Lunch
本人非常认同No Free Lunch法则,并不存在某个算法在任何场景下比另外一个好。假设给更多的资源往Wide上堆,大概率不会输给Deep,但从公司的角度,ROI不行。我们选择技术路线,一个是从问题出发,一个是从ROI出发,二者要通盘考虑。
那为何不直接进入Deep领域呢?个人反对在基线不强的时候,直接进入复杂模型的领域。倒不是说复杂模型难以掌握,而是团队对业务面对的具体问题的理解需要实战积累。而初期简单的模型,更容易暴露出问题是什么,将问题定义清楚,整个结果solid。
比如我们在做Deep时候,还同时在做FM,让二者PK,自然就开始思考Deep和FM的关系,查阅相关的资料发现二者可以融合且make sense,再一步步实践;
再比如我们分析了Wide和Deep的output score分布,Deep更平衡,做了模型用户切片分析,发现Deep除了在热门用户上有较好的表现外,在一部分多浏览少点击的用户上效果更显著等等。
我们在实际工作中,最怕的是不知道问题是什么,而不是怎么做方案。在我们没有做到那个点之前,对问题的定义大多是有问题的,随着越做越深,对问题的理解也会越来越深。 大概就是人们常说的经验吧,没有办法一口吃成胖子。
未来
接下来谈谈现在还没有结果,以及未来要做到一些事情。
Mutil-task
机器学习的应用,从业务角度,基本不存在单一目标场景,但多目标优化在经济学上是一个帕累托均衡问题,很难。以电商为例,我们也是同时关心ctr、cvr、客单价、用户留存、商品动销率等等。
在实际中,ctr和cvr也不是强正相关的,且cvr的样本比ctr小好几个量级,平衡二者并不容易。阿里提出了ESMM来解决ctr、cvr联合训练的问题。我们在实践中,还未达到文章中的效果,但用ctr的做为pretrain的model,有微弱的收益。
长期来看,公司业务会越来越复杂,不同目标直接的平衡问题始终是如鲠在喉,不吐不快。针对单一目标优化的思路,追求的更多是短期收益,而长期收益才是业务的立身之本。在mutil-task的探索,任重而道远。
Context-Rank
我们面对的问题,本质是个排序问题,而不是一个ctr预估问题。以前的learning to rank,就有pointwise、pairwise和listwise之分。从业务理解,一个商品的表现,和其所在位置的前后商品关系很大。
但我们目前的排序模型是不考虑的。只是在业务层做了点打散、去重之类的规则逻辑。后面我们第一步应该会增加一层context rank,加入更多的业务逻辑,比如一屏内商品价格近一些,色彩搭配一致一些等。从技术上讲,可能基于RL的Seq2Seq,是这个问题一个比较好的解法。
信息茧房
也就是人们常说的,越被推荐,看到的东西越窄。针对这个问题,我的理解和大家有一点点不同。这个问题是存在的,但不是存在于活跃用户中。由于很多推荐系统做的都是相关性,并不是相似性,只要用户有持续的反馈数据进来,相关性的推荐会让你发现很多不同的信息。
但活跃忠诚的用户毕竟是少的,更多的时候是,系统给用户推荐了一批毕竟类似的结果,用户觉得被伤害了,直接没有后续反馈了,也就是说信息茧房是存在的,但不是出不来,而是用户是懒惰的,不和你玩了。
这个问题的解法,大家第一反应应该是做E&E。但E&E的效果是一件很难评估的事情,有的时候反而会有伤害。举个例子,一个有潜力的新品,在正常的个性化逻辑下,其分发策略是有个性化的,即有偏,如果context之类的特征做的好,个性化定向准,其初始表现可能会不错。
但在E&E下,其初始分发是无偏的,可能在E&E下其表现还不如不参加E&E,即由于人群定位不准,效果被低估了。对于这个新品来讲,参加E&E反而受损了,本质是流量不是无限的,只能在一定的条件下做探索。
因此,E&E本身不只是一个算法问题,还是一个产品机制问题。举个极端的例子,如果所有的新品都要走E&E,上诉的问题就不存在了。另一个方案是做更多content类的特征、cross domain的特征,比如做一些基于知识图谱的意图识别,尝试和用户有更多的交互来缓解它。
总结
2018年对我们团队来讲意义非凡,取得的那些收益到不重要,我们现在在深度学习这个领域,还是停留在很初级的阶段。关键是锻炼了团队,踩了很多坑,大家都成长了很多。
这一年在知乎写了很多篇文章,回头去看以前的一些文章,有些观点是错误的,有些认知是不足的,但不会去修改了,当做成长的记录吧。希望2019年能再接再厉,输出更多有价值的内容。
参考
[1] https://zhuanlan.zhihu.com/p/49537461
[2] Latent Cross: Making Use of Context in Recurrent Recommender Systems:https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/46488.pdf
[3] https://www.zhihu.com/question/268384579/answer/540721803
