

ESLint 可谓是现代前端开发过程中必备的工具了。其用法简单,作用却很大,使用过程中不知曾帮我减少过多少次可能的 bug。其实仔细想想前端开发过程中的必备工具似乎也没有那么多,ESLint 做为必备之一,值得深挖,理解其工作原理。
在正式讨论原理之前,我们还是先来聊聊为什么要使用 ESLint。
为什么要使用 ESLint
ESLint 其实早在 2013年 7月就发布了,不过我首次使用,是不到三年前的一个下午(清楚的记得那时候使用的编辑器主要还是 sublime text3 )。我在一个项目中尝试了 ESLint ,输入 eslint init 后按照提示最终选择了非常出名的 airbnb 的代码风格,结果整个项目几乎所有文件都被标红,尝试使用 --fix 却无法全部修复,内心十分沮丧。
现在想想,那时候的我对 ESLint 的认知是不完整的,在那时候的我看来 ESLint 就是辅助我们保持代码风格一致的工具,airbnb 的 js 风格备受大家推崇。
那时候的我知道保持代码风格的一致性能增加可读性,更便于团队合作。不过一致没有去深想,为什么大家会推崇某特定的风格,这背后肯定是有着特殊的意义。
保持一致就意味着要对我们编写的代码增加一定的约束,ESLint 就是这么一个通过各种规则(rule)对我们的代码添加约束的工具。JS 做为一种动态语言,写起来可以随心所欲,bug 遍野,但是通过合适的规则来约束,能让我们的代码更健壮,工程更可靠。
在官方文档 ESLint - rules 一节中,我们可以看到官方提供的了大量的规则,有推荐使用的("eslint:recommended"),也有默认不启用的,还有一些废弃的。
这和现实生活是一致的,现实生活中,我们也在不自觉中遵守和构建着各种不同的规则。新的规则被构建是因为我们在某方面有了更多的经验总结,将其转变为规则可能是希望以后少踩坑,也能共享一套最佳实践,提高我们的工作效率。 就像我们提交代码时,把希望大家共同遵守的约定转变为 MR 模板,希望所有人都能遵守。
在我看来 ESLint 的核心可能就是其中包含的各种规则,这些规则大多为众多开发者经验的结晶:
之前看过一张图能很好的描述 ESLint 的作用:
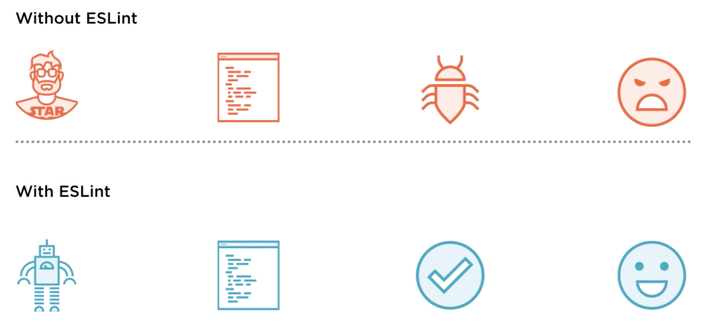
- 如果你不使用 ESLint ,你的代码只能靠人工来检查,格式乱七八糟,运行起来 bug 丛生,你的合作者或用户会怒气冲冲😡;
- 如果你使用了 ESLint ,你的代码有可靠的机器进行检查,格式规则,运行起来问题会少很多,大家都会很满意。
总得来说,ESLint 允许我们通过自由拓展,组合的一套代码应当遵循的规则,可以让我们的代码更为健壮,其功能不仅在于帮我们的代码风格保持统一,还能帮我们用上社区的最佳实践,减少错误。
ESLint 竟然这么重要,下面我们来看看 ESLint 的用法及这些用法是怎么生效的。
从使用方法到 ESLint 的工作原理
可能大家都已经很熟悉,ESLint 的用法包括两部分: 通过配置文件配置 lint 规则; 通过命令行执行 lint,找出不符合规范的地方(当然有些不符合的规则也可以尝试修复);
配合编辑器插件,ESLint 也能很好的起作用,实际上,很多人可能更习惯这种用法。
配置 ESLint
通过 eslint --init 随后做各种选择是生成 eslint 配置文件的一种常见方式,如下:
$ eslint --init zhangwang@zhangwangdeMacBook-Pro-2
? How would you like to configure ESLint? Use a popular style guide
? Which style guide do you want to follow? Airbnb (https://github.com/airbnb/javascript)
? Do you use React? No
? What format do you want your config file to be in? JavaScript
通过上述选择,ESLint 自动为我们生成来配置文件 .eslintrc.js,其内容如下:
/** .eslintrc.js */
module.exports = {
"extends": "airbnb"
};
不要小看上述简单的配置, extends 中包含了 ESLint 的共享机制,让我们已非常低的成本就能用上最好的社区实践。可能每个前端开发者都听过说 airbnb javascript style(Github Star 近 80000)。那么问题来了,这里的一句 "extends": "airbnb" 怎么就让我们可以用上这种规则还挺多的代码风格的呢?
实际上这里的airbnb 是 eslint-config-airbnb 的简写。我们查一下其源码,可以发现如下内容:
module.exports = {
extends: [
'eslint-config-airbnb-base',
'eslint-config-airbnb-base/rules/strict',
'./rules/react',
'./rules/react-a11y',
].map(require.resolve),
rules: {}
};
我们自己配置中的"extends": "airbnb" 相当于告诉 ESLint ,把 eslint-config-airbnb 的规则做为拓展引用到我们自己的项目中来。
如果你想知道 ESLint 源码中是怎么解析配置文件中的extends关键字的,可以参照下述链接指向的源码:
config-file.js - applyExtends
extends 可以是一个字符串,也可以是一个数组。其中可以包含以下内容: 已 eslint: 开头的字符串,如 eslint:recommended,这样写意味着使用 ESLint 的推荐配置,在这里可以查看其具体有哪些规则; 已 plugin: 开头的字符串,如 "plugin:react/recommended",这些写意味着应用第三方插件,eslint-plugin-react 的所有推荐规则,关于
plugin 后文中我们还会讨论; 已 eslint-config-开头的包,这其实是第三方规则的集合,由于 eslint 中添加了额外的处理,我们也可以省略 eslint-config-,如上面的 eslint-config-airbnb-base也可以写作airbnb-base; 一个本地路径,指向本地的 ESLint 配置,如 ./rules/react;
extents 中的每一项内容最终都指向了一个和 ESLint 本身配置规则相同的对象。
如果我们在 npm 中搜索 eslint-config- 可以发现大量的 ESLint 拓展配置模块,我们可以直接通过这些模块在 ESLint 中使用上流行的风格,也可以把自己的配置结果封装为一个模块,供之后复用。
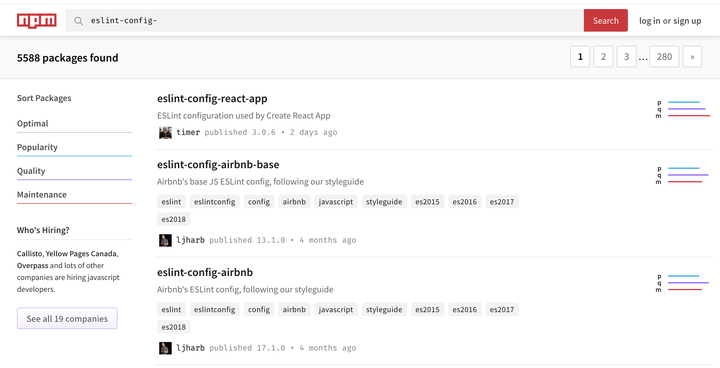
现在我们明白了什么是 extends,不过我们好像还是不知道 ESLint 是怎么工作的?怎么办呢?我们来拆一下上面eslint-config-airbnb 的 extends 中用到的 eslint-config-airbnb-base,其主文件内容如下:
module.exports = {
extends: [
'./rules/best-practices',
'./rules/errors',
'./rules/node',
'./rules/style',
'./rules/variables',
'./rules/es6',
'./rules/imports',
].map(require.resolve),
parserOptions: {
ecmaVersion: 2018,
sourceType: 'module',
},
rules: {
strict: 'error',
},
};
除了 extends,配置文件中出现了 parserOptions 和 rules 。 通过 parserOptions 我们可以告知 ESLint 我们想要支持什么版本的 JS 语法(ecmaVersion),源码类型sourceType,以及是否启用其它一些语法相关的特性(如 jsx), parserOptions 的配置比较简单,可以参考官方文档中的相关。
rules 我们后文中将重点讲解,这里先卖个关子。
再来看一下我们熟悉的 extends ,如果你对官方文档中 rules 那一节有印象,可能会发现 extends 中的项,除了 ./rules/imports 其它项与官方文档 rule 的类别一一对应,这就有趣了,我们先看看 ./rules/best-practices 中的内容,这有利于我们理解 rule。
rules
./rules/best-practices 中的内容如下:
module.exports = {
rules: {
// enforces getter/setter pairs in objects
'accessor-pairs': 'off',
// enforces return statements in callbacks of array's methods
// https://eslint.org/docs/rules/array-callback-return
'array-callback-return': ['error', { allowImplicit: true }],
// treat var statements as if they were block scoped
'block-scoped-var': 'error',
// disallow the use of alert, confirm, and prompt
'no-alert': 'warn',
...
}
}
./rules/best-practices 其实也是一个 ESLint 配置文件,但它比较纯粹,其中只有 rules 一项。
前文我们提到过,ESLint 的核心是由各种 rule 组成的集合,这个配置文件的展开,让我们靠近 ESLint 核心近了很多。我第一次看到这个配置文件时,心生多个疑问: 1. 这个文件中,我们只针对单条 rule 添加了简单的配置,error,warn,off,最多也就再加了一个 option ,ESLint 是怎么依据这些配置起作用的呢? 2. 在以往的工作过程中,我们曾通过注释,如// eslint-disable-next-line no-console 或 /*eslint no-console: ["error", { allow: ["warn"] }] */ 来屏蔽或者启用某条规则,这又是怎么生效的? 3. 多条 rule 又是如何配合工作的?
Lint 是基于静态代码进行的分析,对于 ESLint 来说,我们的输入的核心就说 rule 及其配置以及需要进行 Lint 分析的源码。rule 是我们自己规定的,当然可以满足一定的规则,但是需要进行 Lint 的源码则各不相同了,做为开发者,我们都明白抽象的重要性,如果我们能抽象出 JS 源码的共性,再对源码进行分析也许就容易多了,而对代码的抽象被称作 AST(Abstract Syntax Tree(抽象语法树))。
聊聊 AST
在我学习前端的这几年里,我在很多地方遇到过 AST。
- 《你不知道的 JavaScript 》上卷,第一章提到过 AST;
- 查看浏览器的如何解析 Html ,JS 的时候遇到过 AST;
- Babel,Webpack ,UglifyJS 其它前端工具中也提到过 AST;
AST 本身并不是一个新鲜的话题,可能在任何涉及到编译原理的地方都会涉及到它。
ESLint 使用 espree 来解析我们的 JS 语句,来生成抽象语法树,具体源码是在这里。
AST explorer 是一个非常酷的 AST 工具网站,可以帮我们方便的查看,一段代码被解析成 AST 后的样子。
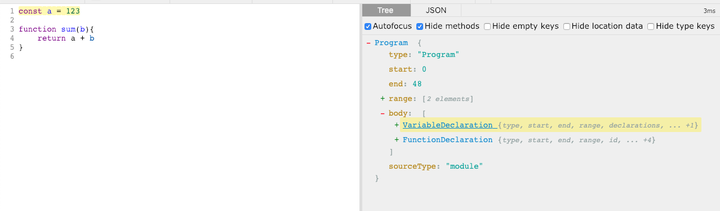
从上面的截图中,也许你也发现了如果我鼠标在右侧选中某一个值时,左侧也有对应的区域被高亮展示。实际上,我们确实可以通过 AST 方便的找到代码中的特定内容。右侧被选中的项,叫做 AST selectors ,熟悉 CSS selectors 的我们,应该能很容易理解。
就像 CSS 选择器一样,AST 选择器也有多种规则让我们可以更方便的选中特定的代码片段,具体规则可以参考
- Selectors - ESLint - Pluggable JavaScript linter
- GitHub - estools/esquery: ECMAScript AST query library. 。
通过 AST selectors 我们可以方便的找到静态代码中的内容,这样理解 rule 是怎么生效的就有了一定的基础了,我们继续上面提出的问题。
单条 rule 是怎么工作的?
关于如何写一条 rule,官方文档中 Working with Rules 一节中已经有了详细的阐述,这里只做简单的描述。
上文我们提到过 ESLint 的核心就是规则(rule),每条规则都是独立的,且都可以被设置为禁止off🈲️,警告warn⚠️,或者报错error❌。
我们选择"no-debugger": "error" 来看看 rule 是如何工作的。源码如下:
module.exports = {
meta: {
type: "problem",
docs: {
description: "disallow the use of `debugger`",
category: "Possible Errors",
recommended: true,
url: "https://eslint.org/docs/rules/no-debugger"
},
fixable: null,
schema: [],
messages: {
unexpected: "Unexpected 'debugger' statement."
}
},
create(context) {
return {
DebuggerStatement(node) {
context.report({
node,
messageId: "unexpected"
});
}
};
}
};
一条 rule 就是一个 node 模块,其主要由 meta 和 create 两部分组成,其中
meta代表了这条规则的元数据,如其类别,文档,可接收的参数的schema等等,官方文档对其有详细的描述,这里不做赘述。create:如果说 meta 表达了我们想做什么,那么create则用表达了这条 rule 具体会怎么分析代码;
Create 返回的是一个对象,其中最常见的键的名字可以是上面我们提到的选择器,在该选择器中,我们可以获取对应选中的内容,随后我们可以针对选中的内容作一定的判断,看是否满足我们的规则,如果不满足,可用 context.report()抛出问题,ESLint
会利用我们的配置对抛出的内容做不同的展示。
上面的代码实际上表明在匹配到 debugger 语句时,会抛出 "Unexpected 'debugger' statement." 。
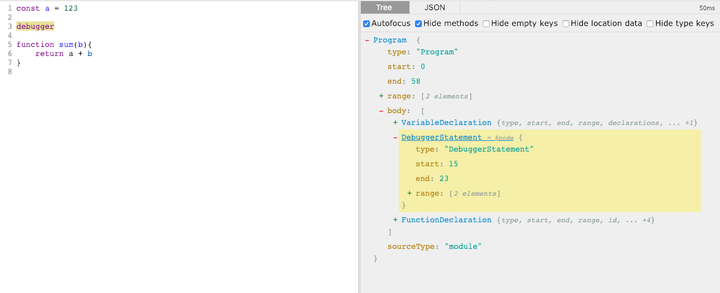
到这里,好像我们对 rule 的理解已经深入很多了。通过上面这类静态的匹配分析确实可以帮我们避免很多问题,不过 ESLint 好像也能帮我们找到永远不会执行的语句。仅仅通过上面的匹配似乎还不足以做到这一点,这就引入了 rule 匹配的另一个要点,code path analysis。
code path analysis
我们的程序中免不了有各种条件语句,循环语句,这让我们程序中的代码不一定是顺序执行,也不一定只执行一次。code path 指的是程序的执行路径。程序可以由若干 code path 表达,一个 code path 可能包括两种类型的对象 CodePath 和 CodePathSegment。
上面是一段好枯燥的描述,那么究竟什么是 code path。我们举例来说:
if (a && b) {
foo();
}
bar();
我们分析一下上述代码的可能执行路径。
- 如果 a 为真 - 检测 b 是否为 真
- 如果 b 为真 — 执行
foo()— 执行bar() - 如果 b 非真 — 执行
bar() - 如果 a 非真,执行
bar()
转换为 AST 的表达方式,可能会更清晰,如下图所示:
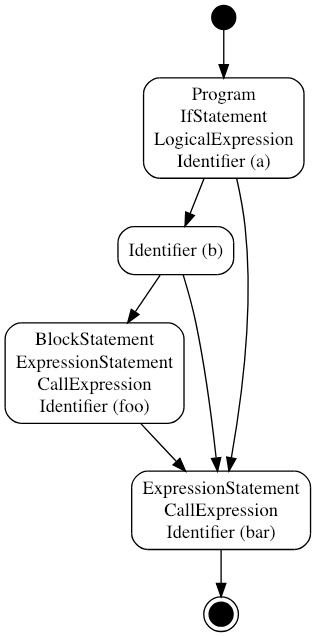
在这里上述这个整体可以看作一个 CodePath,而所谓 CodePathSegment 则是上述分支中的一部分,一个 code path 由多个 CodePathSegment 组成,ESLint 将 code path 抽象为 5 个事件。
onCodePathStart:onCodePathEndonCodePathSegmentStartonCodePathSegmentEndonCodePathSegmentLoop
如果你感兴趣 ESLint 是如何抽象出这五个事件的,可参考源码 code-path-analyzer.js,官方文档中 Code Path Analysis Details 中对 JS 中的 code path 也有很详细的描述,可以参考。
有了这些事件,我们在静态代码分析过程就能有效的控制检测的范围了。如规则 no-fallthrough 中,用以辅助避免执行多条 case 语句
const lodash = require("lodash");
const DEFAULT_FALLTHROUGH_COMMENT = /falls?\s?through/i;
function hasFallthroughComment(node, context, fallthroughCommentPattern) {
const sourceCode = context.getSourceCode();
const comment = lodash.last(sourceCode.getCommentsBefore(node));
return Boolean(comment && fallthroughCommentPattern.test(comment.value));
}
function isReachable(segment) {
return segment.reachable;
}
function hasBlankLinesBetween(node, token) {
return token.loc.start.line > node.loc.end.line + 1;
}
module.exports = {
meta: {...},
create(context) {
const options = context.options[0] || {};
let currentCodePath = null;
const sourceCode = context.getSourceCode();
let fallthroughCase = null;
let fallthroughCommentPattern = null;
if (options.commentPattern) {
fallthroughCommentPattern = new RegExp(options.commentPattern);
} else {
fallthroughCommentPattern = DEFAULT_FALLTHROUGH_COMMENT;
}
return {
onCodePathStart(codePath) {
currentCodePath = codePath;
},
onCodePathEnd() {
currentCodePath = currentCodePath.upper;
},
SwitchCase(node) {
if (fallthroughCase && !hasFallthroughComment(node, context, fallthroughCommentPattern)){
context.report({
message: "Expected a 'break' statement before '{{type}}'.",
data: { type: node.test ? "case" : "default" },
node
});
}
fallthroughCase = null;
},
"SwitchCase:exit"(node) {
const nextToken = sourceCode.getTokenAfter(node);
if (currentCodePath.currentSegments.some(isReachable) &&
(node.consequent.length > 0 || hasBlankLinesBetween(node, nextToken)) &&
lodash.last(node.parent.cases) !== node) {
fallthroughCase = node;
}
}
};
}
};
上面这条规则中就用到了 onCodePathStart 和 onCodePathEnd 来控制 currentCodePath的值。总体想做的事情也比较简单,在SwitchCase 的时候判断是不是 fallthrough 了,如果 fallthrough 并且没有相关评论声明这里是有意 fallthrough,则抛出错误。
不过这里又有一个问题,SwitchCase:exit 是啥?要理解 :exit 我们就需要知道 ESLint 是如何对待一段代码的了。我们回到源码中找答案。
我们节录了 eslint/lib/util/traverser.js 中的部分代码
traverse(node, options) {
this._current = null;
this._parents = [];
this._skipped = false;
this._broken = false;
this._visitorKeys = options.visitorKeys || vk.KEYS;
this._enter = options.enter || noop;
this._leave = options.leave || noop;
this._traverse(node, null);
}
_traverse(node, parent) {
if (!isNode(node)) {
return;
}
this._current = node;
this._skipped = false;
this._enter(node, parent);
if (!this._skipped && !this._broken) {
const keys = getVisitorKeys(this._visitorKeys, node);
if (keys.length >= 1) {
this._parents.push(node);
for (let i = 0; i < keys.length && !this._broken; ++i) {
const child = node[keys[i]];
if (Array.isArray(child)) {
for (let j = 0; j < child.length && !this._broken; ++j) {
this._traverse(child[j], node);
}
} else {
this._traverse(child, node);
}
}
this._parents.pop();
}
}
if (!this._broken) {
this._leave(node, parent);
}
this._current = parent;
}
观看上述代码,我们会发现,对 AST 的遍历,用到了递归,其实是存在一个由外向内再向外的过程的。:exit 其实相当于添加了一重额外的回调,让我们对静态代码有了更多的控制。
好啦,我们总结一下,selector,selector:exit,code path event 其实可以看作对代码 AST 遍历的不同阶段,让我们对一段静态代码的分析有了充分的控制。
至此,我们对如何写一条 rule 已经有了充分的了解。继续上面提出的其它问题,
- rule 是怎么组合起来的
- 多条 rule 是怎么生效的
ESLint 是怎么看待我们传入的 rule 的
现在我们已经知道,我们可以通过多种途径传入 rule。我们先看这些 rule 是怎么组合的
最后生效的 rule 主要有两个来源: 1. 配置文件中涉及到的 rule ,对于这部分 rule 的处理,主要位于源码中的 lib/rule.js 中; 2. 评论中的 rule ,对这部分 rule ,被称作 directive rule 的处理,ESLint 对其的处理位于 getDirectiveComments 函数中;
这里有点像以前在学校使用游标卡尺,配置文件中的 rule 用作粗调,文件内部的 rule 用作精调。
最终的 rule 是这两部分的组合,被称作 configuredRules 的对象,其中每一项的内容类似于 'accessor-pairs': 'off'。
获取到所有的需要对某个文件应用的规则后,接下来的应用则是一个典型的多重遍历过程,源码位于 runRules 中 ,节选部分内容放在下面:
function runRules(sourceCode, configuredRules, ruleMapper, parserOptions, parserName, settings, filename) {
const emitter = createEmitter();
const nodeQueue = [];
let currentNode = sourceCode.ast;
Traverser.traverse(sourceCode.ast, {
enter(node, parent) {
node.parent = parent;
nodeQueue.push({ isEntering: true, node });
},
leave(node) {
nodeQueue.push({ isEntering: false, node });
},
visitorKeys: sourceCode.visitorKeys
});
const lintingProblems = [];
Object.keys(configuredRules).forEach(ruleId => {
const severity = ConfigOps.getRuleSeverity(configuredRules[ruleId]);
if (severity === 0) {
return;
}
const rule = ruleMapper(ruleId);
const messageIds = rule.meta && rule.meta.messages;
let reportTranslator = null;
const ruleContext = Object.freeze(
Object.assign(
Object.create(sharedTraversalContext),
{
id: ruleId,
options: getRuleOptions(configuredRules[ruleId]),
report(...args) {
if (reportTranslator === null) {...}
const problem = reportTranslator(...args);
if (problem.fix && rule.meta && !rule.meta.fixable) {
throw new Error("Fixable rules should export a `meta.fixable` property.");
}
lintingProblems.push(problem);
}
}
)
);
const ruleListeners = createRuleListeners(rule, ruleContext);
// add all the selectors from the rule as listeners
Object.keys(ruleListeners).forEach(selector => {
emitter.on();
});
});
const eventGenerator = new CodePathAnalyzer(new NodeEventGenerator(emitter));
nodeQueue.forEach(traversalInfo => {
currentNode = traversalInfo.node;
if (traversalInfo.isEntering) {
eventGenerator.enterNode(currentNode);
} else {
eventGenerator.leaveNode(currentNode);
}
});
return lintingProblems;
}
- 遍历依据源码生成的 AST ,将每一个 node 传入 nodeQueue 队列中,每个会被传入两次;
- 遍历所有将被应用的规则,为规则中所有的选择器添加监听事件,在触发时执行,将问题 push 到
lintingProblems中; - 遍历第一步获取到的 nodeQueue,触发其中包含的事件
- 返回 lintingProblems
这里有些细节,我们没有讨论到,不过大致就是这样一个过程了,都说 node 的事件驱动机制是其特色之一,这里在 ESLint 中应用rule 是一个事件驱动的好范例。
至此我们已经理解了 ESLint 的核心,不过还有一些内容没有涉及到。我们继续拆解 eslint-config-airbnb 中出现的 './rules/react'
module.exports = {
plugins: [
'react',
],
parserOptions: {
ecmaFeatures: {
jsx: true,
},
},
rules: {
'jsx-quotes': ['error', 'prefer-double'],
...
},
settings: {
'import/resolver': {
node: {
extensions: ['.js', '.jsx', '.json']
}
},
...
}
}
这里又出现了两个我们至今还未讨论过的配置,这里又出现了两个我们至今还未见过的配置plugin 和 settings。settings 用来传输一些共享的配置,比较简单,使用可参考官方文档,这里不再赘述。不过
plugin 也是 ESLint 的重点之一,指的我们再讨论一下。
plugin
plugin 有两重概念;
- 一是 ESLint 配置项中的字段,如上面的
plugins: ['react',],; - 二是社区封装的 ESLint plugin,在 npm 上搜索
eslint-plugin-就能发现很多,比较出名的有 eslint-plugin-react ,eslint-plugin-import
plugin 其实可以看作是第三方规则的集合,ESLint 本身规则只会去支持标准的 ECMAScript 语法,但是如果我们想在 React 中也使用 ESLint 则需要自己去定义一些规则,这就有了 eslint-plugin-react 。
plugin 的配置和 ESLint 配置文件的配置很相似,在此不再赘述。如果你感兴趣,可以参考官方文档 - working-with-plugins。
不过我们这里可以提一下 plugin 的两种用法:
- 在
extends中使用, plugin 具有自己的命名空间,可通过”extends": ["plugin:myPlugin/myConfig"]引用 plugin 中的某类规则(可能是全部,也可能是推荐); - 在
plugin中使用,如添加配置plugins: ['react',],可声明自己想要引用的eslint-plugin-react提供的规则,但是具体用哪些,怎么用,还是需要在 rules 中配置;
对 plugin 的支持让 ESLint 更开放,增加了其本身的使用范围。
不过还有另外一个问题,JS 发展这么快,如果我们想对一些非标准 JS 语法添加 Lint 怎么办呢?有办法,ESLint 还支持我们自定义 parser。
自定义 parser
只需要满足 ESLint 的规定,ESLint 支持自定义 parser,实际上社区在这方面也做了很多工作。比如
- babel-eslint,A wrapper for Babel's parser used for ESLint
- typescript-eslint-parser,让我们可以 lint TS 代码
自定义的 parser 使用方法如下:
{
"parser": "./path/to/awesome-custom-parser.js"
}
通过自定义 parser ,ESLint 的使用场景又被大大拓展。
其它配置项
我们再去 Configuring ESLint 看看 ESLint 支持的所有配置,看看还有哪些是我们比较陌生的。
global,env: 不可避免的我们会使用到一些全局变量,而使用全局变量和一些规则的使用是有冲突的,通过global配置我们可以声明想用的全局变量,而 env 则是对全局变量的一重封装,让我们可以直接使用,让我们可以直接使用一些常见的库暴露出来的全局变量,可以查看 eslint/environments.js 查看其实现细节。- overrides,外侧配置的 rule 一般都是全局生效,通过 overrides ,我们可以针对一些文件覆盖一些规则。
- settings,通过 setting 我们可以像每条 rule 传入一些自定义的配置内容
后记
还有一些 ESLint 相关的内容在本文没有提到,比如说 formatters,ESLint 毕竟最终是要给人看的,好的输出很重要,关于 formatters 很多库都会有涉及到,也是一个很有意思的话题,可以很大的话题,还有就是 ESLint 的层叠机制, 忽略机制等等。
另外就是每条 rule 的使用都有其背后的原因,很多 rule 我都没有仔细去看其添加的初衷,不过在下次用之前,也许我会提醒一下自己为什么要用这条 rule,感觉会很有意思,你也可以看看。
ESLint 就说到这里了,用了很久的 ESLint ,但是这次尝试把 ESLint 说清楚真的是花了很久,所以还有些别的想聊一下。
当我们在学习一个工具时,我们在学什么?
我想,当我们学习一个工具时 首先我们应当了解其想要解决的问题,知道了具体想解决的问题就可以对症下药,就不容易导致分不清 prettier 和 ESLint 的区别了; 其次,我们应当去了解其基本用法; 再次,如果这个工具足够常用,可能我们应当深入去了解其实现用到的一些基础,比如说这次我们了解了 AST,也许下次去理解 Babel 是怎么工作的,就会简单很多,而不会把它又当作一个全新的东西。
第二个想聊的问题是,如果遇到自己无法理解的问题怎么办? 我想,慢慢的,我们已经逐渐养成了阅读官方文档的习惯,随后,希望也能逐步养成阅读源码的习惯,读源码能解决很多自己看文档无法理解的问题。
如果能看到这里,不妨点个赞吧。哈哈哈
推荐资料
关于 ESLint 的使用:
- Better Code Quality with ESLint | Pluralsight Pluralsight 是一个付费订阅网站,价格不便宜,但是这个课确实很好;
- 前端工具考 - ESLint 篇,可以大致了解一下 Lint 工具在前端中的发展史
关于 AST:
- Parser API,可以了解一下 estree AST 的约定
- AST in Modern JavaScript - 知乎 ,ESLint 在前端中的应用
