

树的遍历是当且仅当访问树中每个节点一次的过程。遍历可以解释为把所有的节点放在一条线上,或者将树线性化。
遍历的定义只指定了一个条件:每个节点仅访问一次,没有指定这些节点的访问顺序。因此,节点有多少种排列方式,就有多少种遍历方法。对于有n个节点的树,共有n!个不同的遍历方式。然而大多数遍历方式是混乱的,很难从中找到规律,因此实现这样的遍历缺乏普遍性。经过前人总结,这里介绍两种遍历方式,即广度优先遍历与深度优先遍历。
- 广度优先遍历
广度优先遍历是从根节点开始,向下逐层访问每个节点。当使用队列时,这种遍历方式的实现相当直接。假设从上到下、从左到右进行广度优先遍历。在访问了一个节点之后,它的子节点就放到队列的末尾,然后访问队列头部的节点。对于层次为n的节点,它的子节点位于第n+1层,如果将该节点的所有子节点都放到队列的末尾,那么,这些节点将在第n层的所有节点都访问之后再访问。
代码实现如下:
//广度优先遍历
void breadthFirst(Node* &bt){
queue<Node*> que;
Node* BT = bt;
que.push(BT);
while (!que.empty()){
BT = que.front();
que.pop();
printf("%c", BT->data);
if (BT->lchild)
que.push(BT->lchild);
if (BT->rchild)
que.push(BT->rchild);
}
}广度优先遍历的逻辑比较简单,这里就不过多介绍了。
- 深度优先遍历
树的深度优先遍历相当有趣。深度优先遍历将尽可能的向下进行,在遇到第一个转折点时,向左或向右一步,然后再尽可能的向下发展。这一过程一直重复,直至访问了所有节点为止。然而,这一定义并没有清楚的指明什么时候访问节点:在沿着树向下进行之前还是在折返之后呢?因此,深度优先遍历有着几种变种。
假如现在有个简单的二叉树:
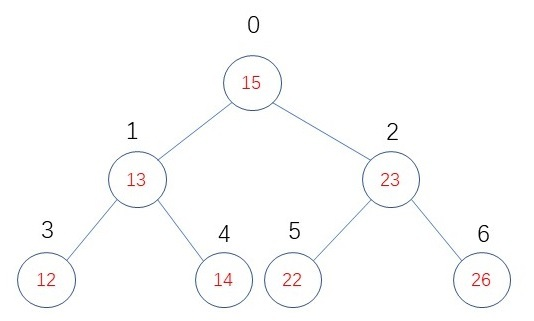
我们从左到右进行深度优先遍历:
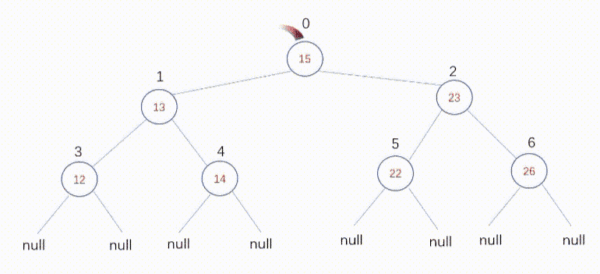
你会发现其实每个节点遍历到了3次:

红色的是第一次遍历到的次序,蓝色的是第二次遍历到的次序,黑色的是第三次遍历到的次序。这其实就是二叉树从左到右的前序、中序、后序遍历,从右到左也有三种遍历,和上面遍历的类似。前辈们对这三种遍历方式进一步总结,将深度遍历分解成3个任务:
- V-访问节点
- L-遍历左子树
- R-遍历右子树
前序遍历其实是VLR,中序遍历是LVR,后序遍历是LRV
我们来讨论深度遍历的实现方法,毫无疑问,递归是非常简单并且容易理解的方式,代码如下:
//从左向右前中后递归遍历
void leftPreOrder(Node *bt)
{
if (bt){
printf("%c", bt->data);
leftPreOrder(bt->lchild);
leftPreOrder(bt->rchild);
}
}
void leftInOrder(Node *bt)
{
if (bt){
leftInOrder(bt->lchild);
printf("%c", bt->data);
leftInOrder(bt->rchild);
}
}
void leftPostOrder(Node *bt)
{
if (bt){
leftPostOrder(bt->lchild);
leftPostOrder(bt->rchild);
printf("%c", bt->data);
}
}可以看到三种遍历方式的实现代码差别很小,其实差别就是V、L、R的顺序不同,递归方式没啥难点,这里就不多讲了。重点在于下面的非递归实现方式。
递归代码是有缺陷的,毫无疑问会给运行时栈带来沉重的负担,因为每次递归(调用函数)都会在运行时栈上开辟新的函数栈空间,如果二叉树的高度比较大,程序运行可能直接爆掉栈空间,这是不能容忍的。因此,我们要实现非递归方式的二叉树深度遍历。
寻常的非递归遍历方式实质上就是模拟上面动态图中箭头的转移过程,在三种遍历方式中前序遍历是最简单的,无论是哪一种遍历方式,都需要借助栈来实现。因为在深度遍历中会有回溯的过程,这就要求程序可以记住以往遍历过的节点,只有满足这一点才能回溯成功,这就需要借助栈来保存遍历节点的次序。下面是非递归遍历方式的代码:
节点定义:
typedef struct BiNode{
int data;
struct BiNode * lchild;
struct BiNode * rchild;
}BiNode,*BiTree;
前序遍历:
void preOrderBiTree(BiNode * root){
if(root == NULL)
return;
BiNode * node = root;
stack<BiNode*> nodes;
while(node || !nodes.empty()){
while(node != NULL){
nodes.push(node);
printf("%d",node->data);
node = node -> lchild;
}
node = nodes.top();//回溯到父节点
nodes.pop();
node = node -> rchild;
}
}可以看到,在将节点入栈之前已经访问过节点,栈在这里的作用只有回溯。
中序遍历代码如下:
void inOrderBinaryTree(BiNode * root){
if(root == NULL)
return;
BiNode * node = root;
stack<BiNode*> nodes;
while(node || !nodes.empty()){
while(node != NULL){
nodes.push(node);
node = node ->lchild;
}
node = nodes.top();
printf("%d ",node ->data);
nodes.pop();
node = node ->rchild;
}
}中序遍历中访问节点发生在出栈之前,栈在这里的作用不仅仅是回溯,出栈还代表着第二次遍历到该节点。后序遍历更是需要程序实现V之前L和R操作已经完成,这就需要程序具有记忆功能。
后序遍历代码如下:
void PostOrderS(Node *root) {
Node *p = root, *r = NULL;
stack<Node*> s;
while (p!=NULL || !s.empty()) {
if (p!=NULL) {//走到最左边
s.push(p);
p = p->left;
}
else {
p = s.top();
if (p->right!=NULL && p->right != r)//右子树存在,未被访问
p = p->right;
else {
s.pop();
visit(p->val);
r = p;//记录最近访问过的节点
p = NULL;//节点访问完后,重置p指针
}
}//else
}//while
}后序遍历中最重要的逻辑是保证节点的左右子树访问之后再访问该节点,程序中使用变量保存了上次访问的节点。如果节点i存在右子树,并且上个访问的节点是右子树的根节点,才能访问i节点。
毫无疑问,以上通过程序模拟前中后三种遍历过程,就是我们常说的过程式代码,如果你在面试中遇到这类问题,情急之下不一定能写的出来。究其原因在于思想不统一,前中后遍历的三种代码实现方式是割裂开的。怎么办?笔者探究了一种实现方式,从思想上统一前中后三种遍历过程。
首先用自然语言描述实现逻辑:
假如有以下二叉树:
我们来实现后序遍历,后序遍历的逻辑是LRV,也就是说,对于一颗二叉树,我们希望首先遍历左子树,然后是右子树,最后是根节点,放到栈里就是这样的:
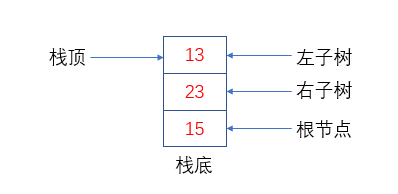
注意这里,这里看似只是压入了三个节点,实质上已经将整棵树压入到栈里了。因为13在这里代表的不是一个节点,而是整棵左子树,23也是代表着整棵右子树。这里就有疑问了,以这样的方式入栈有个锤子用处,你告诉我怎么访问13这颗左子树?如何解决这个矛盾点才是核心逻辑。我们可以继续分解左子树,就像这样:
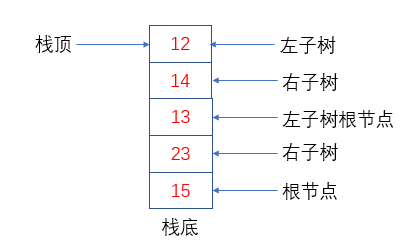
可以看到,13代表的左子树以LRV的方式分解成3部分。这时栈中存在两个节点三颗树,程序的下一步继续弹出栈顶节点,如果是树就继续分解,如果是节点就代表着该节点是第一个可以访问到的节点。
使用这种方式来遍历二叉树,前中后三种遍历的差别只有一点,就是如何分解树。前序是VLR,中序是LVR,后序是LRV,程序的其他部分没有差别。
完整逻辑如下:
首先将根节点压入栈,随后弹出栈顶节点,发现是棵树,分解该树,按照指定的方式将左子树、右子树、根节点压入栈中。随后弹出栈顶节点,如果是棵树就继续分解,如果是节点就访问该节点。程序的结束标志是栈为空,代表整棵树的节点都已经访问完毕。
这种遍历方式笔者称之为分解遍历,因为核心逻辑是如何分解栈中代表树的节点。分解遍历使得前中后非递归遍历以统一的逻辑来处理。
分解遍历要求栈中节点保存额外的属性,即该节点是树还是结点,就是说我们需要一种方式知道弹出节点是树还是结点。方法有很多,可以修改节点定义,添加一个额外的成员变量,或者栈中存储字典,key是节点,value代表该节点是树还是结点,或者修改栈,为每个节点保存额外的属性。笔者使用的方法是修改栈,为栈中每个节点保存额外属性。
参考代码如下:
/*二叉树节点*/
typedef struct node
{
char data;
struct node *lchild, *rchild;
}Node;
/*二叉树栈*/
typedef struct
{
int top;//指向二叉树节点指针的指针
struct node* data[MAX];
bool isNode[MAX];
}SqStack;
void push(SqStack *&s, Node *bt, bool isNode = true)
{
if (s == NULL)
return;
if (s->top == MAX - 1)
{
printf("栈满,不能再入栈");
}
else
{
s->top++;
s->data[s->top] = bt;
s->isNode[s->top] = isNode;
}
}
Node* pop(SqStack *&s)
{
if (s->top == -1)
{
printf("栈空,不能出栈");
}
else
{
Node* temp;
temp = s->data[s->top];
s->top--;
return temp;
}
}
bool topIsNode(SqStack *&s){
if (s->top != -1)
return s->isNode[s->top];
return false;
}
//从左向右前中后非递归遍历
void leftPreOrder(Node *bt)
{
Node *BT = bt;
bool isNode = false;
push(s, BT, isNode);
while (!EmptyStack(s)){
isNode = topIsNode(s);
BT = pop(s);
if (isNode){
printf("%c", BT->data);
}
else{
if (BT->rchild != NULL)
push(s, BT->rchild, false);
if (BT->lchild != NULL)
push(s, BT->lchild, false);
push(s, BT, true);
}
}
}
void leftSimPreOrder(Node *bt)
{
Node *BT = bt;
push(s, BT);
while (!EmptyStack(s)){
BT = pop(s);
printf("%c", BT->data);
if (BT->rchild != NULL)
push(s, BT->rchild);
if (BT->lchild != NULL)
push(s, BT->lchild);
}
}
void leftInOrder(Node *bt)
{
Node *BT = bt;
bool isNode = false;
push(s, BT, isNode);
while (!EmptyStack(s)){
isNode = topIsNode(s);
BT = pop(s);
if (isNode){
printf("%c", BT->data);
}
else{
if (BT->rchild != NULL)
push(s, BT->rchild, false);
push(s, BT, true);
if (BT->lchild != NULL)
push(s, BT->lchild, false);
}
}
}
void leftPostOrder(Node *bt)
{
Node *BT = bt;
bool isNode = false;
push(s, BT, isNode);
while (!EmptyStack(s)){
isNode = topIsNode(s);
BT = pop(s);
if (isNode){
printf("%c", BT->data);
}
else{
push(s, BT, true);
if (BT->rchild != NULL)
push(s, BT->rchild, false);
if (BT->lchild != NULL)
push(s, BT->lchild, false);
}
}
}参考代码中前中后非递归遍历的逻辑几乎一致,差别在于分解树之后,以怎样的方式入栈。而且对于前序遍历,笔者进行了简化。因为前序遍历中,树以VLR的方式分解,入栈之后,栈顶总是结点,因此可以省去判断栈顶是树还是结点的逻辑。
使用栈的二叉树遍历到此已经探究完毕,更多内容请看下一章节。
