

未经允许,请勿私自转载
前言
我的前言都是良心话,还是姑且看一下吧:
别人一看这个标题,心想,“怎么又是一个老到掉牙的需求,网上一搜一大堆解决方案啦!”。没错!这个需求实在老土得不能再老土了,我真不想写这样一种需求的文章,无奈!无奈!
现实的情况是我想这么旧的需求网上资料一大把一大把,虽然我知道网上资料可能有坑,但是我总不信找不到一篇好的全面的资料的。然而现实又是一次啪啪的打脸,我是没找到,而且很多资料都是一个拷贝一个,质量参差不齐,想必很多找资料的人也深有体会
为了让别人不再走我的老路,特此写了此篇文章和大家分享
我不能说我写的文章质量杠杠滴。但是我会在这里,客观地指出我方案的缺点,不忽悠别人。
写该文章的目的只有两个:
- 让缺乏这方面经验的人能够信手拈来一个较为全面的方案,对自己对公司相对负责,别qa提很多bug啦(我也是这么过来,纯粹想帮助小白)
- 让更有能力的人,补充完善我的方案,或者借鉴我的经验,造出更强更全面的方案,当然,我也希望能让我学习一下就最好了。
目录
需求
还是说一下这到底是个什么需求吧。想必大家都试过在一个网页上,按下“ctrl + F”,然后输入关键词来找到页面上匹配的。
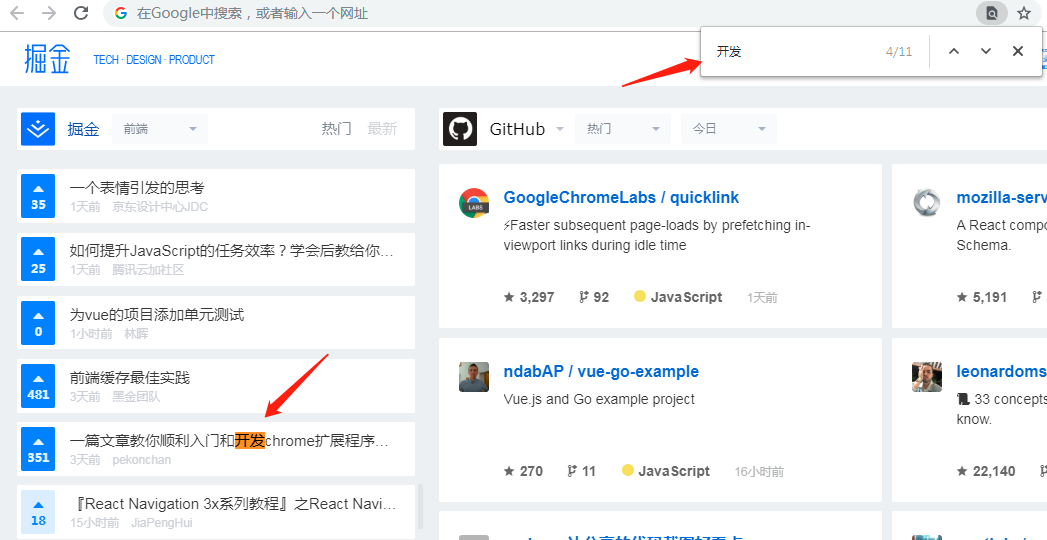
没错,就是这么一种类似的简单的需求。但是这么一个简单的需求,却暗藏杀机。这种需求(非就是这种形式)用文字明确描述一下:
页面上有一个按钮,或者一个输入框,进行操作时,针对某些关键词(任意字符串都可以,除换行符),在页面上进行高亮显示,注意此页面内容是有任何可能的网页
描述很抽象?那我就干脆定一个明确的需求:
实现一个插件,在任何别人的网页上高亮想要的关键词。
这里不说实现插件的本身,只描述高亮的方案。
接下来我将循序渐进地从一个个简单的需求到复杂的需求,告诉你这里边到底需要考虑什么。
一个最简单的方案
第一反应,想必大家都觉得用字符串来处理了吧,在字符串里找到匹配的文字,然后用一个html元素包围着,加上类名,css高亮!对吧,一切都感觉如此自然顺利~
我先不说这方案的鸡肋之处,光说落实到实际处理的时候,需要做些什么。
超简单处理
// js
var keyword = '关键词1'; // 假设这里的关键词为“关键词1”
var bodyContent = document.body.innerHTMl; // 获取页面内容
var contentArray = bodyContent.split(keyword);
document.body.innerHTMl = contentArray.join('<span>' + keyword + '</span>');
// css
.highlight {
background: yellow;
color: red;
}
简单处理二
这里相对上面还没那么简单,至于为啥我说这个方案的原因是,在后面讲的复杂方案里,需要用到这些知识。
关键词的处理
上面说需求的时候讲过,是针对任意关键词(除换行符)进行的高亮,如果更简单点,说只针对英文或中文,那么可以直接匹配了,如str.match('keyword');。但是我们是要做一个通用的功能的话,还是要特别针对一些转义字符做处理的,不然如关键词为?keyword',用'?keyword'.match('?keyword');,会报错。
我找了各种特殊字符进行了测试,最终形成了以下方法针对各种特殊字符进行了处理。
// string为原本要进行匹配的关键词
// 结果transformString为进行处理后的要用来进行匹配的关键词
var transformString = string.replace(/[.[*?+^$|()/]|\]|\\/g, '\\$&');
看不懂?想深究,可以看一下这边文章: 这是一篇男女老少入门精通咸宜的正则笔记
反正这里的意思就是把各种转义字符变成普通字符,以便可以匹配出来。
匹配高亮
// js部分
var bodyContent = document.body.innerHTMl; // 获取页面内容
var pattern = new RegExp(transformString, 'g'); // 生成正则表达式
// 匹配关键词并替换
document.body.innerHTMl = bodyContent.replace(pattern, '<span class="highlight">$&</span>');
// css
.highlight {
background: yellow;
color: red;
}
缺点
把页面的内容当成一个字符串来处理,存在很多预想不到的情况。
- script标签内有匹配文本,添加高亮html元素后,导致脚本报错。
- 标签属性(特别是自定义属性,如dats-*)存在匹配文本,添加高亮后,破坏原有功能
- 刚好匹配文本跟某内联样式文本匹配上,如
<div style="width: 300px;"></div>,关键词刚好为width,这时候就尴尬了,替换结果为<div style="<span class="highlight">width</span>: 300px;"><div。这样就破坏了原本的样式了。 - 还有一种情况,如
<div>右</div>,关键词为>右,这时候替换结果为<div<span class="highlight">>右</span></div>,同样破坏了结构。 - 以及还有很多很多情况,以上仅是我罗列的一些,未知的情况实在太多了
利用DOM节点高亮(基础版)
既然字符串的方法太多弊端了,那只能舍弃掉了,另寻他法。 这节内容就考大家的基础知识扎不扎实了
页面的内容有一个DOM树构成,其中有一种节点叫文本节点,就是我们页面上所能看到的文字(大部分,图片等除外),那么我们只要在这些文本节点里找到是否有我们匹配的关键词,匹配上的就对该文本节点做改造就好了。
封装一个函数做上述处理(注释中一个个解释), ①内容为上述讲过:
// ①
// string为原本要进行匹配的关键词
// 结果transformString为进行处理后的要用来进行匹配的关键词
var transformString = string.replace(/[.[*?+^$|()/]|\]|\\/g, '\\$&');
var pattern = new RegExp(transformString, 'i'); // 这里不区分大小写
/**
* ② 高亮关键字
* @param node - 节点
* @param pattern - 用于匹配的正则表达式,就是把上面的pattern传进来
*/
function highlightKeyword(node, pattern) {
// nodeType等于3表示是文本节点
if (node.nodeType === 3) {
// node.data为文本节点的文本内容
var matchResult = node.data.match(pattern);
// 有匹配上的话
if (matchResult) {
// 创建一个span节点,用来包裹住匹配到的关键词内容
var highlightEl = document.createElement('span');
// 不用类名来控制高亮,用自定义属性data-*来标识,
// 比用类名更减少概率与原本内容重名,避免样式覆盖
highlightEl.dataset.highlight = 'yes';
// splitText相关知识下面再说,可以先去理解了再回来这里看
// 从匹配到的初始位置开始截断到原本节点末尾,产生新的文本节点
var matchNode = node.splitText(matchResult.index);
// 从新的文本节点中再次截断,按照匹配到的关键词的长度开始截断,
// 此时0-length之间的文本作为matchNode的文本内容
matchNode.splitText(matchResult[0].length);
// 对matchNode这个文本节点的内容(即匹配到的关键词内容)创建出一个新的文本节点出来
var highlightTextNode = document.createTextNode(matchNode.data);
// 插入到创建的span节点中
highlightEl.appendChild(highlightTextNode);
// 把原本matchNode这个节点替换成用于标记高亮的span节点
matchNode.parentNode.replaceChild(highlightEl, matchNode);
}
}
// 如果是元素节点 且 不是script、style元素 且 不是已经标记过高亮的元素
// 至于要区分什么元素里的内容不是你想要高亮的,可自己补充,这里的script和style是最基础的了
// 不是已经标记过高亮的元素作为条件之一的理由是,避免进入死循环,一直往里套span标签
else if ((node.nodeType === 1) && !(/script|style/.test(node.tagName.toLowerCase())) && (node.dataset.highlight !== 'yes')) {
// 遍历该节点的所有子孙节点,找出文本节点进行高亮标记
var childNodes = node.childNodes;
for (var i = 0; i < childNodes.length; i++) {
highlightKeyword(childNodes[i], pattern);
}
}
}
注意这里的pattern参数,就是上述关键词处理后的正则表达式
/** css高亮样式设置 **/
[data-highlight=yes] {
display: inline-block;
background: #32a1ff;
}
这里用的是属性选择器
splitText
这个方法针对文本节点使用,IE8+都能使用。它的作用是能把文本节点按照指定位置分离出另一个文本节点,作为其兄弟节点,即它们是同父同母哦~ 看图理解更清楚:
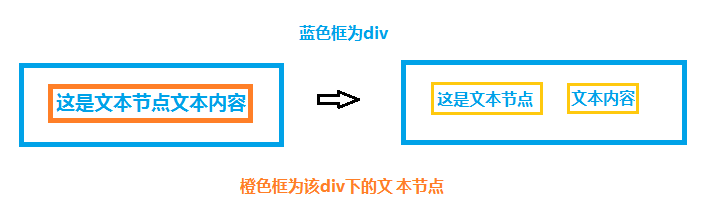
虽然这个div原本是只有一个文本节点,后来变成了两个,但是对实际页面效果,看起来还是一样的。
语法
/**
* @param offset 指定的偏移量,值为从0开始到字符串长度的整数
* @returns replacementNode - 截出的新文本节点,含offset处文本
*/
replacementNode = textnode.splitText(offset)
例子
<body>
<p id="p">example</p>
<script type="text/javascript">
var p = document.getElementById('p');
var textnode = p.firstChild;
// 将原文本节点分割成为内容分别为exa和mple的两个文本节点
var replacementNode = textnode.splitText(3);
// 创建一个包含了内容为' new span '的文本节点的span元素
var span = document.createElement('span');
span.appendChild(document.createTextNode(' new span '));
// 将span元素插入到后一个文本节点('bar')的前面
p.insertBefore(span, replacementNode);
// 现在的HTML结构成了<p id="p">exa<span>new span</span>mple</p>
</script>
</body>
例子中的最后一个插入span节点的作用,就是让大家看清楚,实际上原本一个文本节点“example”的确变成了两个“exa”“mple”,不然加入的span节点不会处于二者中间了。
缺点
一个基础版的高亮方案已经形成了,解决了上述用字符串方案遇到的问题。然而,这里也存在还需额外处理或考虑的事情。
- 这里的方案一次性高亮是没问题的,但是需要多次不同关键词高亮呢?
- 别人的网页无法预测,如果网页上有一些隐藏文本是通过颜色来隐藏的,例如白色的背景,文本颜色也是白色的这种情况,高亮了可能把隐藏的信息也给弄出来。(这个我也无能为力了)
多次高亮(单关键词高亮完成版)
实现多高亮,就是实现第二次高亮的时候,把上一次的高亮痕迹给抹掉,这里会有两个思路:
- 每一次高亮只对原始数据进行处理。
- 需要一个关闭旧的高亮,然后重新对新关键词高亮
只对原始数据处理
这个想法其实很好,因为感觉处理起来会很简单,每次都用基础版的高亮方案做一次就好了,也不存在什么污染DOM的问题(这里说的是在已经污染DOM的基础上再处理高亮)。主要处理手段:
// 刚进入别人页面时就要保存原始DOM信息了
const originalDom = document.querySelector('body').innerHTML;
// 高亮逻辑开始...
let bodyNode = document.querySelector('body');
// 把原始DOM信息重新赋予body
bodyNode.innerHTML = originalDom
// 把原始DOM信息再次转化为节点对象
let bodyChildren = bodyNode.childNodes;
// 针对内容进行高亮处理
for (var i = 0; i < bodyChildren.length; i++) {
// 这里的pattern就是上述经过处理后的关键词生成的正则,不再赘述了
highlightKeyword(bodyChildren[i], pattern);
}
这里就是做一次高亮的主要逻辑,如果要多次高亮,重复运行这里的逻辑,把关键词改变一下就好了。还有这里需要理解的是,因为高亮的函数是针对节点对象来处理的,所以一定要把保存起来的DOM信息(此时为字符串)再转化为节点对象。
此方案的确很简单,看似很完美,但是这里还是有些问题不得不考虑一下:
- 我一向不倾向这种把对象转为字符串再转化为对象的做法,因为我不得知转化里头会是否完全把信息给搞过来还是会丢失一些信息,正如大家常用的深拷贝一个方法
JSON.parse(JSON.stringify())的弊端一样。我们永远不知道别人的网站是如何生成的,会不会根据一些刚好转化时丢失的信息来生成,这些我们都无法保证。因此我不太建议使用这种方法。在这次我这里简单做了个小测试,发现还是有些信息会丢失,test的信息不见了。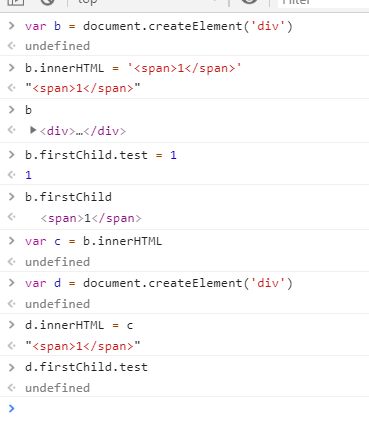
- 在实际应用上,存在局限性,例如有一个场景使用该方法不是个好主意:chrome extension是作为iframe嵌入到别人的网页的。使用该方法的话,由于body直接通过innerHTML重新赋值了,页面的内容会重新刷了一遍(浏览器性能不好的话可能还会看到一瞬间的闪烁),而这个插件iframe也不例外,这样的话,原本插件上的未保存内容或操作内容都会刷新成初始情况了,反正就是把插件iframe的情况也改了就不好了。
关闭旧高亮开启新高亮
除了上述方法,还有这里的一个方法。大家肯定想,关闭不就是设置高亮样式没了嘛,对的,是这样的,但是总的想法归总的想法,落实到实践,要考虑的地方却往往不像想象中那么easy。总体思路很简单,找到已经高亮的节点(dataset.highlight = 'yes'),然后去掉这层包裹层就好了。
// 记住这个函数名,下面不赘述,直接调用
function closeHighlight() {
let highlightNodeList = document.querySelectorAll('[data-highlight=yes]');
for (let n = 0; n < highlightNodeList.length; n++) {
let parentNode = highlightNodeList[n].parentNode;
// 把高亮包裹层里面的文本生成一个新的文本节点
let textNode = document.createTextNode(highlightNodeList[n].innerText);
// 用新的文本节点替换高亮的节点
parentNode.replaceChild(textNode, highlightNodeList[n]);
// 把相邻的文本节点合成一个文本节点
parentNode.normalize();
}
}
然后针对新的关键词高亮,再运行上述封装的高亮函数。
关于normalize的解释,详见:
这里的意思就是把相邻的文本节点合成一个文本节点,避免把文本给截断了,之后高亮其他关键词不管用了。如:
<div>hello大家好</div>
第一个关键词“hello”,高亮后关闭,原本的div只有只有一个文本子节点,现在变成了两个了,分别为“hello”“大家好”。那么在此匹配“o大”这个关键词时,就匹配不了。因为不在一个节点上了。
小结
至此,一个关于能过多次使用的单个关键词高亮的方案已经落幕了。有个选择: 只对原始数据处理 和 关闭旧高亮开启新高亮 。各有优缺点,大家根据自己实际项目需求取舍,甚至要求更低的,直接采用最上面的各个简单方案。
多个关键词同时高亮
这里的及以下的方案,都是基于DOM高亮—关闭旧高亮开启新高亮方案下处理的。其实有了以上的基础,接下来的需求都是锦上添花,不会过于复杂。
首先对关键词的处理上:
// 要进行匹配的多个关键词
let keywords = ['Hello', 'pekonChan'];
let wordMatchString = ''; // 用来形成最终多个关键词特殊字符处理后的结果
keywords.forEach(item => {
// 每个关键词都要做特殊字符处理
let transformString = item.replace(/[.[*?+^$|()/]|\]|\\/g, '\\$&');
// 用'|'来表示或,正则的意义
wordMatchString += `|(${transformString})`;
});
wordMatchString = wordMatchString.substring(1);
// 形成匹配多个关键词的正则表达式,用于开启高亮
let pattern = new RegExp(wordMatchString, 'i');
// 形成匹配多个关键词的正则表达式(无包含关系),用于关闭高亮
let wholePattern = new RegExp(`^${wordMatchString}$`, 'i');
之后的操作跟上述的“关闭旧高亮开启新高亮方案”的流程是一样的,只是对关键词的处理不同而已。
缺点
高亮存在先后顺序。什么意思?举例子说明,如有一组关键词['证件照', '照换'],在下面的一个元素里要高亮:
<div>证件照换背景颜色</div>
用上述方法高亮后结果为:
<div><span data-highlight="yes">证件照<span>换背景颜色</div>
结果看到,只有“证件照”产生了高亮,是因为在生成匹配的正则时,“证件照”在前的。假设换个顺序['照换', '证件照'],那么结果就是:
<div>证件<span data-highlight="yes">照换<span>背景颜色</div>
这种问题,说实在的,我现在也无能为力解决,如果大家有更好的方案,请告诉我学习一下~
分组情况下的多个关键词的高亮
这里的需求我用例子来阐述,如图
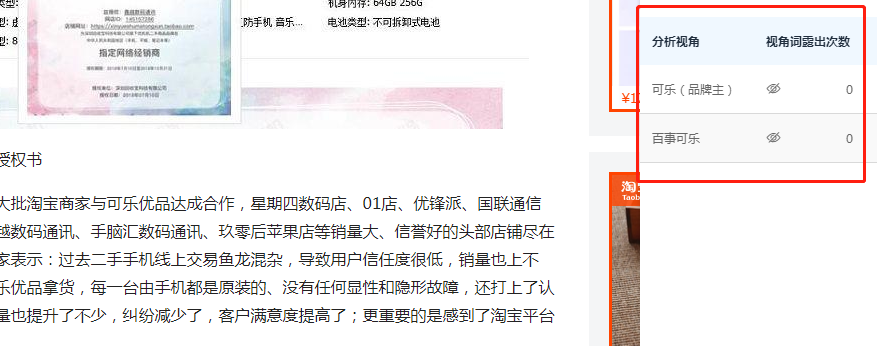
红框部分是一个chrome扩展,左边部分为任意的别人的网页(高亮的页面对象),扩展里有一个表格,
- 其中每行都会有一组关键词,
- 视角词露出次数列上有个眼睛的图标,点一下就开启该行下的关键词高亮,再点一下就关闭高亮。
- 每行之间的高亮操作可以同时高亮,都是独立操作的
我们先看一下我们已有的方案(在多个关键词同时高亮方案的基础上)在满足以上需求的不足之处:
例如第一组关键词高亮了,设置为yes,第二组关键词需要高亮的文本恰恰在第一组高亮文本内,是被包含关系。由于第一组关键词高亮文本已经设为yes了,所以第二组关键词开启高亮模式的时候不会对第一组的已经高亮的节点继续遍历下去。不幸的是,这就造成了当第一组关键词关闭高亮模式后,第二组虽然开始显示为开启高亮模式,但是由于刚刚没有遍历,所以原本应该在第一组高亮词内高亮的文本,却没有高亮
文字不好理解?看例子,第一组关键词(假设都为单个)为“可口可乐”,第二组为“可乐”
表格第一行开启高亮模式,结果:
<div>
<span data-highlight="yes" data-highlightMatch="Hello">可口可乐</span>
</div>
接着,第二行也开启高亮模式,执行highlightKeyword函数的else if这里,由于可口可乐外层的span已经设为yes了,所以不再往下遍历了。
function highlightKeyword(node, pattern) {
if (node.nodeType === 3) {
...
} else if ((node.nodeType === 1) && !(/script|style/.test(node.tagName.toLowerCase())) && (node.dataset.highlight !== 'yes')) {
...
}
}
此时结果仍为:
<div>
<span data-highlight="yes" data-highlightMatch="Hello">可口可乐</span>
</div>
然而,当关闭第一行的高亮模式时,此时结果为:
<div>可口可乐</div>
但是我只关了第一行的高亮,第二行还是显示这高亮模式,然而第二行的“可乐”关键词却没有高亮。这就是弊端了!
设置分组
要解决上述问题,需要也为高亮的节点设置分组。highlightKeyword函数需要做点小改造,加个index参数,并绑定在dataset里,else if的判断条件也需要作出一些改变,都见注释部分:
/**
* 高亮关键字
* @param node 节点
* @param pattern 匹配的正则表达式
* @param index - 表示第几组关键词
*/
function highlightKeyword(node, pattern, index) {
if (node.nodeType === 3) {
let matchResult = node.data.match(pattern);
if (matchResult) {
let highlightEl = document.createElement('span');
highlightEl.dataset.highlight = 'yes';
// 把匹配结果的文本存储在dataset里,用于关闭高亮,详解见下面
highlightEl.dataset.highlightMatch = matchResult[0];
// 记录第几组关键词
highlightEl.dataset.highlightIndex = index;
let matchNode = node.splitText(matchResult.index);
...
}
} else if ((node.nodeType === 1) && !(/script|style/.test(node.tagName.toLowerCase()))) {
// 如果该节点为插件的iframe,不做高亮处理
if (node.className === 'extension-iframe') {
return;
}
// 如果该节点标记为yes的同时,又是该组关键词的,那么就不做处理
if (node.dataset.highlight === 'yes') {
if (node.dataset.highlightIndex === index.toString()) {
return;
}
}
let childNodes = node.childNodes;
for (let i = 0; i < childNodes.length; i++) {
highlightKeyword(childNodes[i], pattern, index);
}
}
}
这样的话,包含在第一组关键词里的别组关键词也可以继续标为高亮了。
有没有留意到,上述添加了这么一句代码highlightEl.dataset.highlightMatch = matchResult[0];
这句用意是,用于下面说的分组关闭高亮的。根据这个信息来区分,我要关闭哪些符合内容的高亮节点,不能统一依据highlignth=yes来处理。例如,这个高亮节点匹配的是“Hello”,那么highlightEl.dataset.highlightMatch就是“Hello”,要关闭这个因为“Hello”产生的高亮节点,就要判断highlightEl.dataset.highlightMatch == 'Hello'
为什么我这里会选择用dataset的形式存关键词内容,可能大家会觉得直接判断元素里面的innerText或者firstChid文本节点不就好了吗,实际上,这种情况就不好使了:
<div>
<span data-highlight="yes" data-highlight-index="1">Hel<span data-highlight="yes" data-highlight-index="2">lo</span></span>
, I'm pekonChan
</div>
当里面的hello被拆成了几个节点后,用innerText或者firstChid都不好使。
关闭高亮也要分组关闭
改造原本的关闭高亮函数closeHighlight,不能像之前那样统一关闭了,在分组前,先对之前改造匹配关键词的地方,再做一些补充:
// string为原本要进行匹配的关键词
let transformString = string.replace(/[.[*?+^$|()/]|\]|\\/g, '\\$&');
// 这里有区分,变成头尾都要匹配,用于分组关闭高亮
let wholePattern = new RegExp(`^${transformString}$`, 'i');
// 用于高亮匹配
let pattern = new RegExp(transformString, 'i');
为什么pattern跟之前的会有区分,因为要完全符合(不能是包含关系)关键词的时候才能设置节点高亮关闭。如要关闭关键词为“Hello”的高亮,在下面元素里是不应该关闭的,要完全符合“Hello”才行
<div data-highlight="no" data-highlightMatch="showHello"></div>
接下来是改造原本的关闭高亮函数:
function closeHighlight(wholePattern, index) {
let highlightNodeList = document.querySelectorAll('[data-highlight=yes]');
for (let n = 0; n < highlightNodeList.length; n++) {
const dataset = highlightNodeList[n].dataset;
// 如果不需要分组或分组了组别不对,则不需要取消
if (index == null || dataset.highlightIndex !== index.toString()) {
return;
}
// 这里的wholePattern就是上述的完全匹配关键词正则表达式
if (wholePattern.test(highlightNodeList[n].dataset.highlightMatch)) {
// 记录要关闭的高亮节点的父节点
let parentNode = highlightNodeList[n].parentNode;
// 记录要关闭的高亮节点的子节点
let childNodes = highlightNodeList[n].childNodes;
let childNodesLen = childNodes.length;
// 记录要关闭的高亮节点的下个兄弟节点
let nextSibling = highlightNodeList[n].nextSibling;
// 把高亮节点的子节点移动到兄弟节点前面
for (let k = 0; k < childNodesLen; k++) {
parentNode.insertBefore(childNodes[0], nextSibling);
}
// 创建空白文本节点并替换原本的高亮节点
let flagNode = document.createTextNode('');
parentNode.replaceChild(flagNode, highlightNodeList[n]);
// 合并邻近文本节点
parentNode.normalize();
}
}
}
大家明显看到,之前的只有innerText实现替换高亮节点的方式已经没了,因为不管用了,因为有可能出现这种情况:
<h1>
<span data-highlight="yes" data-highlightIndex="1" data-highlight-match="证件照">
证件照
<span data-highlight="yes" data-highlightIndex="2">lo</span>
</span>
, I'm pekonChan
</h1>
如果还是用原本的方式那么里面那层第二组的高亮也没了:
<h1>
证件照, I'm pekonChan
</h1>
因为要把高亮节点的所有子节点,都要保留下来,我们只是移除个包裹层而已。
注意里面的一个for循环,由于每移动一次,childNodes就会变化一次,因为insertBefore方法是如果原本没有要插入的节点,就新增插入,如果已经存在,就会剪切移动插入,移动后旧节点就会没了。因此childNodes会变化,所以我们只利用childNodes一开始的长度,每次插入childNodes的第一个节点(因为原本的第一个节点被移走了,第二个就会变成第一个)
缺点
其实这里的缺点,跟上节的多个关键词高亮是一样的 传送门
能返回匹配个数的高亮方案
看到上面的那个需求,表格视角词露出次数列眼睛图标旁边还有个数字,这个其实就是能高亮的关键词个数。那么这里也是做点小改造就能顺带计算出个数了(改动在注释部分):
/**
* 高亮关键字
* @param node 节点
* @param pattern 匹配的正则表达式
* @param index - 表示第几组关键词
* @returns exposeCount - 露出次数
*/
function highlightKeyword(node, pattern, index) {
let exposeCount = 0; // 露出次数变量
if (node.nodeType === 3) {
let matchResult = node.data.match(pattern);
if (matchResult) {
let highlightEl = document.createElement('span');
highlightEl.dataset.highlight = 'yes';
highlightEl.dataset.highlightMatch = matchResult[0];
highlightEl.dataset.highlightIndex = index;
let matchNode = node.splitText(matchResult.index);
matchNode.splitText(matchResult[0].length);
let highlightTextNode = document.createTextNode(matchNode.data);
highlightEl.appendChild(highlightTextNode);
matchNode.parentNode.replaceChild(highlightEl, matchNode);
exposeCount++; // 每高亮一次,露出次数加一次
}
} else if ((node.nodeType === 1) && !(/script|style/.test(node.tagName.toLowerCase()))) {
if (node.className === 'eod-extension-iframe') {
return;
}
if (node.dataset.highlight === 'yes') {
if (node.dataset.highlightIndex === index.toString()) {
return;
}
}
let childNodes = node.childNodes;
for (let i = 0; i < childNodes.length; i++) {
highlightKeyword(childNodes[i], pattern, index);
}
}
return exposeCount; // 返回露出次数
}
缺点
因为统计露出次数是跟着实际高亮一起统计的,而正如前面所说的,这种高亮方案存在 高亮存在先后顺序 的问题,因此统计的个数也会不会准确。
如果你不在乎高亮个数和统计个数一定要一致的话,想要很精准的统计个数的话,我可以提供两个思路,但由于篇幅问题,我就不写出来了,看了这篇文章的都对我提的思路不会觉得很难,就是繁琐而已:
- 运用上述的 只对原始数据处理 方案,针对每个关键词,都“假”做一遍高亮处理,个数跟着高亮次数而计算,但是要注意,这里只为了统计个数,不要真的对页面进行高亮(如果你不要这种高亮处理的话),就可以统计准确了。
- 不使用“只对原始数据处理”方案,在原本这个方案里,可以在
data-highlight="yes"又是同组关键词下,判断被包含的视角词是否存在,存在就露出次数加1,但是目前我还不知道该怎么实现。
总结
感觉写了很多很多,我觉得我应该讲得比较清楚吧,哪种方案由哪种弊端。但我要明确的是,这里没有说哪种方案更好!只有恰好合适的满足需求的方案才是好方案,如果你只是用来削苹果的,不拿水果刀,却拿了把杀猪刀,是可以削啊,还能削很多东西呢。但是你觉得,这样好吗?
这里也正是这个意思,我为什么不直接写个最全面的方案出来,大家直接复制粘贴拿走不送就好了,还要啰啰嗦嗦那么多,为的就是让大家自个儿根据自身需求找到更合适自己的方式就好了!
本文最后提供一个暂且最全面的方案,以方便真的着急做项目而没空详细阅读我文章或不想考虑那么多的人儿。
若本文对您有帮助,请点个赞,未经允许,请勿转载,写文章不易呐,都是花宝贵时间写的~
于发文后,修改了一次,修改于2018/12/28 12:16
暂且最全方案
高亮函数
/**
* 高亮关键字
* @param node 节点
* @param pattern 匹配的正则表达式
* @param index - 可选。本项目中特定的需求,表示第几组关键词
* @returns exposeCount - 露出次数
*/
function highlightKeyword(node, pattern, index) {
var exposeCount = 0;
if (node.nodeType === 3) {
var matchResult = node.data.match(pattern);
if (matchResult) {
var highlightEl = document.createElement('span');
highlightEl.dataset.highlight = 'yes';
highlightEl.dataset.highlightMatch = matchResult[0];
(index == null) || highlightEl.dataset.highlightIndex = index;
var matchNode = node.splitText(matchResult.index);
matchNode.splitText(matchResult[0].length);
var highlightTextNode = document.createTextNode(matchNode.data);
highlightEl.appendChild(highlightTextNode);
matchNode.parentNode.replaceChild(highlightEl, matchNode);
exposeCount++;
}
}
// 具体条件自己加,这里是基础条件
else if ((node.nodeType === 1) && !(/script|style/.test(node.tagName.toLowerCase()))) {
if (node.dataset.highlight === 'yes') {
if (index == null) {
return;
}
if (node.dataset.highlightIndex === index.toString()) {
return;
}
}
let childNodes = node.childNodes;
for (var i = 0; i < childNodes.length; i++) {
highlightKeyword(childNodes[i], pattern, index);
}
}
return exposeCount;
}
对关键词进行处理(特殊字符转义),形成匹配的正则表达式
/**
* @param {String | Array} keywords - 要高亮的关键词或关键词数组
* @returns {Array}
*/
function hanldeKeyword(keywords) {
var wordMatchString = '';
var words = [].concat(keywords);
words.forEach(item => {
let transformString = item.replace(/[.[*?+^$|()/]|\]|\\/g, '\\$&');
wordMatchString += `|(${transformString})`;
});
wordMatchString = wordMatchString.substring(1);
// 用于再次高亮与关闭的关键字作为一个整体的匹配正则
var wholePattern = new RegExp(`^${wordMatchString}$`, 'i');
// 用于第一次高亮的关键字匹配正则
var pattern = new RegExp(wordMatchString, 'i');
return [pattern, wholePattern];
}
关闭高亮函数
/**
* @param pattern 匹配的正则表达式
* @param index 关键词的组别,即第几组关键词
*/
function closeHighlight(pattern, index) {
var highlightNodeList = document.querySelectorAll('[data-highlight=yes]');
for (var n = 0; n < highlightNodeList.length; n++) {
const dataset = highlightNodeList[n].dataset;
// 如果不需要分组或分组了组别不对,则不需要取消
if (index == null || dataset.highlightIndex !== index.toString()) {
return;
}
if (pattern.test(dataset.highlightMatch)) {
var parentNode = highlightNodeList[n].parentNode;
var childNodes = highlightNodeList[n].childNodes;
var childNodesLen = childNodes.length;
var nextSibling = highlightNodeList[n].nextSibling;
for (var k = 0; k < childNodesLen; k++) {
parentNode.insertBefore(childNodes[0], nextSibling);
}
var flagNode = document.createTextNode('');
parentNode.replaceChild(flagNode, highlightNodeList[n]);
parentNode.normalize();
}
}
}
基础应用
// 只高亮一次
// 要匹配的关键词
var keywords = 'Hello';
var patterns = hanldeKeyword(keywords);
// 针对body内容进行高亮
var bodyChildren = window.document.body.childNodes;
for (var i = 0; i < bodyChildren.length; i++) {
highlightKeyword(bodyChildren[i], pattern[0]);
}
// 接着高亮其他关键词
// 可能需要先抹掉不需要之前不需要高亮的
keywords = 'World'; // 新关键词
closeHighlight(patterns[1]);
patterns = hanldeKeyword(keywords);
// 针对新关键词高亮
for (var i = 0; i < bodyChildren.length; i++) {
highlightKeyword(bodyChildren[i], pattern[0]);
}
// css
.highlight {
background: yellow;
color: red;
}
未经允许,请勿私自转载
