

前言
Redis 集群,顾名思义就是使用多个 Redis 节点构成的集群,从而满足在数据量和并发数大的业务需求。
在单个 Redis 的节点实例下,存储的数据量大和高并发的情况下,内存很容易就暴涨。同时,一个 Redis 的节点,内存也是受限的,两个原因,一个是内存过大,在进行数据同步的时候,全量同步的时候会导致时间过长,会增加同步失败的风险;另一个原因就是一般的 Redis 都是部署在云服务器上的,这个也会受到CPU的使用率的影响。
所以,在面对着大数据量的时候,就会 Redis 集群的方案来管理,同时也是把这么多 Redis 实例的CPU计算能力汇集到一起,从而完成关于大数据和高并发量的的读写操作。
目录
Redis集群的方案有哪些?优缺点分别是什么?Codis集群的分片原理是怎么样的?Codis集群的迁移方式和工具有哪些?Codis为什么很多命令行不支持?- 如果
Codis集群正在迁移中,怎么处理发送过来的读写请求?
正文
Redis 集群方案有哪些
Redis 的集群解决方案有社区的,也有官方的,社区的解决方案有 Codis 和Twemproxy,Codis是由我国的豌豆荚团队开源的,Twemproxy是Twitter团队的开源的;官方的集群解决方案就是 Redis Cluster,这是由 Redis 官方团队来实现的。下面的列表可以很明显地表达出三者的不同点。
| - | Codis | Twemproxy | Redis Cluster |
|---|---|---|---|
| resharding without restarting cluster | Yes | No | Yes |
| pipeline | Yes | Yes | No |
| hash tags for multi-key operations | Yes | Yes | Yes |
| multi-key operations while resharding | Yes | No(details) | |
| Redis clients supporting | Any clients | Any clients | Clients have to support cluster protocol |
Codis 集群
Codis 是一个代理中间件,用的是 GO 语言开发的,如下图,Codis 在系统的位置是这样的。
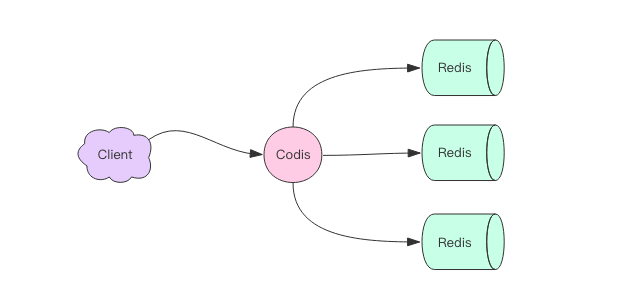
Codis分为四个部分,分别是Codis Proxy (codis-proxy)、Codis Dashboard (codis-config)、Codis Redis (codis-server)和ZooKeeper/Etcd.
Codis就是起着一个中间代理的作用,能够把所有的Redis实例当成一个来使用,在客户端操作着SDK的时候和操作Redis的时候是一样的,没有差别。
因为Codis是一个无状态的,所以可以增加多个Codis来提升QPS,同时也可以起着容灾的作用。
Codis 分片原理
在Codis中,Codis会把所有的key分成1024个槽,这1024个槽对应着的就是Redis的集群,这个在Codis中是会在内存中维护着这1024个槽与Redis实例的映射关系。这个槽是可以配置,可以设置成 2048 或者是4096个。看你的Redis的节点数量有多少,偏多的话,可以设置槽多一些。
Codis中key的分配算法,先是把key进行CRC32 后,得到一个32位的数字,然后再hash%1024后得到一个余数,这个值就是这个key对应着的槽,这槽后面对应着的就是redis的实例。(可以思考一下,为什么Codis很多命令行不支持,例如KEYS操作)
CRC32:CRC本身是“冗余校验码”的意思,CRC32则表示会产生一个32bit(8位十六进制数)的校验值。由于CRC32产生校验值时源数据块的每一个bit(位)都参与了计算,所以数据块中即使只有一位发生了变化,也会得到不同的CRC32值。
Codis中Key的算法代码如下
//Codis中Key的算法
hash = crc32(command.key)
slot_index = hash % 1024
redis = slots[slot_index].redis
redis.do(command)
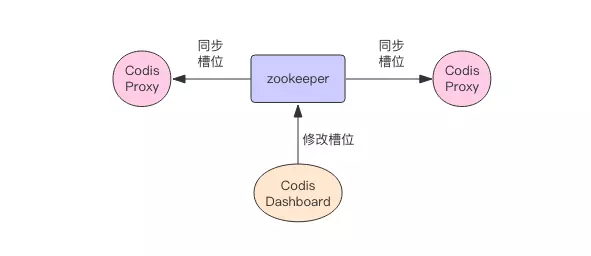
Codis之间的槽位同步
思考一个问题:如果这个
Codis节点只在自己的内存里面维护着槽位与实例的关系,那么它的槽位信息怎么在多个实例间同步呢?
Codis把这个工作交给了ZooKeeper来管理,当Codis的Codis Dashbord 改变槽位的信息的时候,其他的Codis节点会监听到ZooKeeper的槽位变化,会及时同步过来。如图:
Codis中的扩容
思考一个问题:在
Codis中增加了Redis节点后,槽位的信息怎么变化,原来的key怎么迁移和分配?如果在扩容的时候,这个时候有新的key进来,Codis的处理策略是怎么样的?
因为Codis是一个代理中间件,所以这个当需要扩容Redis实例的时候,可以直接增加redis节点。在槽位分配的时候,可以手动指定Codis Dashbord来为新增的节点来分配特定的槽位。
在Codis中实现了自定义的扫描指令SLOTSSCAN,可以扫描指定的slot下的所有的key,将这些key迁移到新的Redis的节点中(话外语:这个是Codis定制化的其中一个好处)。
首先,在迁移的时候,会在原来的Redis节点和新的Redis里都保存着迁移的槽位信息,在迁移的过程中,如果有key打进将要迁移或者正在迁移的旧槽位的时候,这个时候Codis的处理机制是,先是将这个key强制迁移到新的Redis节点中,然后再告诉Codis,下次如果有新的key的打在这个槽位中的话,那么转发到新的节点。代码策略如下:
slot_index = crc32(command.key) % 1024
if slot_index in migrating_slots:
do_migrate_key(command.key) # 强制执行迁移
redis = slots[slot_index].new_redis
else:
redis = slots[slot_index].redis
redis.do(command)
自动均衡策略
面对着上面讲的迁移策略,如果有成千上万个节点新增进来,都需要我们手动去迁移吗?那岂不是得累死啊。当然,Codis也是考虑到了这一点,所以提供了自动均衡策略。自动均衡策略是这样的,Codis 会在机器空闲的时候,观察Redis中的实例对应着的slot数,如果不平衡的话就会自动进行迁移。
Codis的牺牲
因为Codis在Redis的基础上的改造,所以在Codis上是不支持事务的,同时也会有一些命令行不支持,在官方的文档上有(Codis不支持的命令)
官方的建议是单个集合的总容量不要超过1M,否则在迁移的时候会有卡顿感。在Codis中,增加了proxy来当中转层,所以在网络开销上,是会比单个的Redis节点的性能有所下降的,所以这部分会有些的性能消耗。可以增加proxy的数量来避免掉这块的性能损耗。
MGET的过程
思考一个问题:如果熟悉
Redis中的MGET、MSET和MSETNX命令的话,就会知道这三个命令都是原子性的命令。但是,为什么Codis支持MGET和MSET,却不支持MSETNX命令呢?
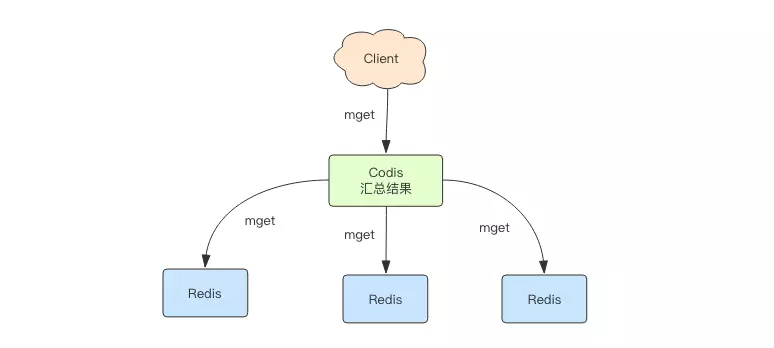
原因如下:
在Codis中的MGET命令的原理是这样的,先是在Redis中的各个实例里获取到符合的key,然后再汇总到Codis中,如果是MSETNX的话,因为key可能存在在多个Redis的实例中,如果某个实例的设值成功,而另一个实例的设值不成功,从本质上讲这是不成功的,但是分布在多个实例中的Redis是没有回滚机制的,所以会产生脏数据,所以MSETNX就是不能支持了。
Codis集群总结
Codis是一个代理中间件,通过内存保存着槽位和实例节点之间的映射关系,槽位间的信息同步交给ZooKeeper来管理。- 不支持事务和官方的某些命令,原因就是分布多个的
Redis实例没有回滚机制和WAL,所以是不支持的.
本文参考资料:
推荐一篇大规模的Codis集群治理文章
更多干货,欢迎也可以关注我的公众号:spacedong

