

写在前面
在看过目录之后,读者可能会问为什么这个教程没有讲一个框架,比如说scrapy或者pyspider。在这里,我认为理解爬虫的原理更加重要,而不是学习一个框架。爬虫说到底就是HTTP请求,与语言无关,与框架也无关。
在本节,我们将用26行代码开发一个简单的并发的(甚至分布式的)爬虫框架。
爬虫的模块
首先,我们先来说一下爬虫的几个模块。
任务产生器——Producer
定义任务,如:爬取什么页面?怎么解析
下载器——Downloader
下载器,接受任务产生器的任务,下载完成后给解析器进行解析。主要是I/O操作,受限于网速。
解析器——Parser
解析器,将下载器下载的内容进行解析,传给输出管道。主要是CPU操作,受限于下载器的下载速度。
输出管道——Pipeline
如何展示爬取的数据,如之前我们一直都在用print,其实也就是一个ConsolePipeline。当然你也可以定义FilePipeline、MysqlPipeline、Sqlite3Pipeline等等。
- ConsolePipeline: 把想要的内容直接输出到控制台。
- FilePipeline: 把想要的内容输出到文件里保存,比如保存一个json文件。
- MongoDBPipeline: 把想要的内容存入MongoDB数据库中。
- 等等......
爬虫框架的结构
上面的四个模块也就构成了四个部分。
- 1 . 首先,会有个初始的任务产生器产生下载任务。
- 2 . 下载器不断从任务队列中取出任务,下载完任务后,放到网页池中。
- 3 . 不同的解析器取出网页进行解析,传给对应的输出管道。期间,解析器也会产生新的下载任务,放入到任务队列中。
- 4 . 输出管道对解析的结果进行存储、显示。

简易的爬虫框架的架构
其实,我们也可以把爬虫不要分的那么细,下载+解析+输出其实都可以归类为一个Worker。
就像下面一样,首先初始的任务产生器会产生一个下载任务,然后系统为下载任务创建几个Worker,Worker对任务进行下载解析输出,同时根据解析的一些链接产生新下载的任务放入任务队列。如此循环,直到没有任务。
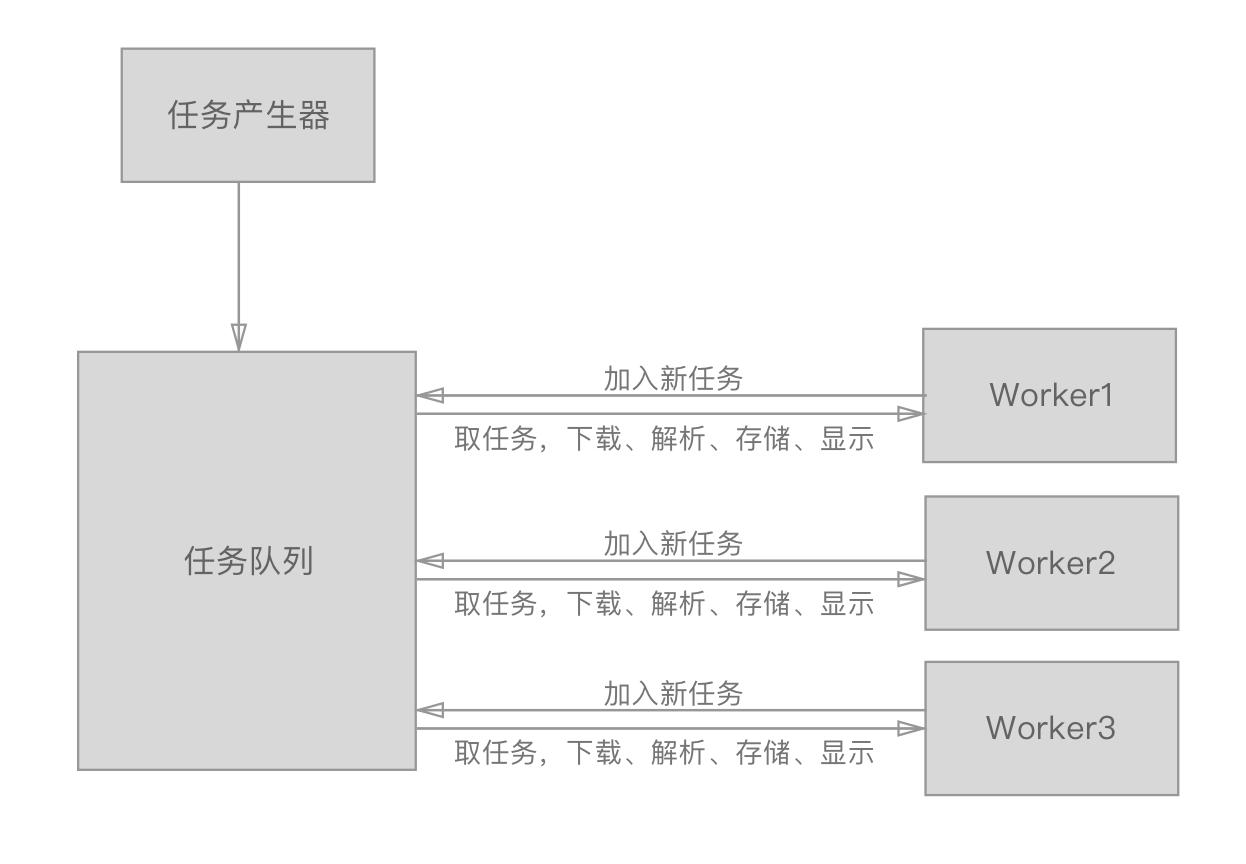
进程间通信
下面,我们说一下进程间通信。
这里我们举一个生产者消费者的例子。假设有两个进程,一个叫生产者,一个叫做消费者。生产者只负责生产一些任务,并把任务放到一个池子里面(任务队列),消费者从任务队列中拿到任务,并对完成任务(把任务消费掉)。
我们这里的任务队列使用multiprocessing的Queue,它可以保证多进程间操作的安全。
from multiprocessing import Process, Queue
import time
def produce(q): # 生产
for i in range(10):
print('Put %d to queue...' % value)
q.put(i)
time.sleep(1)
def consume(q): # 消费
while True:
if not q.empty():
value = q.get(True)
print('Consumer 1, Get %s from queue.' % value)
if __name__ == '__main__':
q = Queue()
producer = Process(target=produce, args=(q,))
consumer = Process(target=consume, args=(q,))
producer.start()
consumer.start()
producer.join() # 等待结束, 死循环使用Ctrl+C退出
consumer.join()
当然,也可以尝试有多个生产者,多个消费者。下面创建了两个生产者和消费者。
from multiprocessing import Process, Queue
import time
def produce(q): # 生产
for i in range(10000):
if i % 2 == 0:
print("Produce ", i)
q.put(i)
time.sleep(1)
def produce2(q): # 生产
for i in range(10000):
if i % 2 == 1:
print "Produce ", i
q.put(i)
time.sleep(1)
def consume(q): # 消费
while True:
if not q.empty():
value = q.get(True)
print 'Consumer 1, Get %s from queue.' % value
def consume2(q): # 消费
while True:
if not q.empty():
value = q.get(True)
print 'Consumer 2, Get %s from queue.' % value
if __name__ == '__main__':
q = Queue(5) # 队列最多放5个任务, 超过5个则会阻塞住
producer = Process(target=produce, args=(q,))
producer2 = Process(target=produce2, args=(q,))
consumer = Process(target=consume, args=(q,))
consumer2 = Process(target=consume2, args=(q,))
producer.start()
producer2.start()
consumer.start()
consumer2.start()
producer.join() # 等待结束, 死循环使用Ctrl+C退出
producer2.join()
consumer.join()
consumer2.join()
这里生产者生产的时间是每秒钟两个,消费者消费时间几乎可以忽略不计,属于“狼多肉少”系列。运行后,可以看到控制台每秒都输出两行。Consumer1和Consumer2的争抢十分激烈。
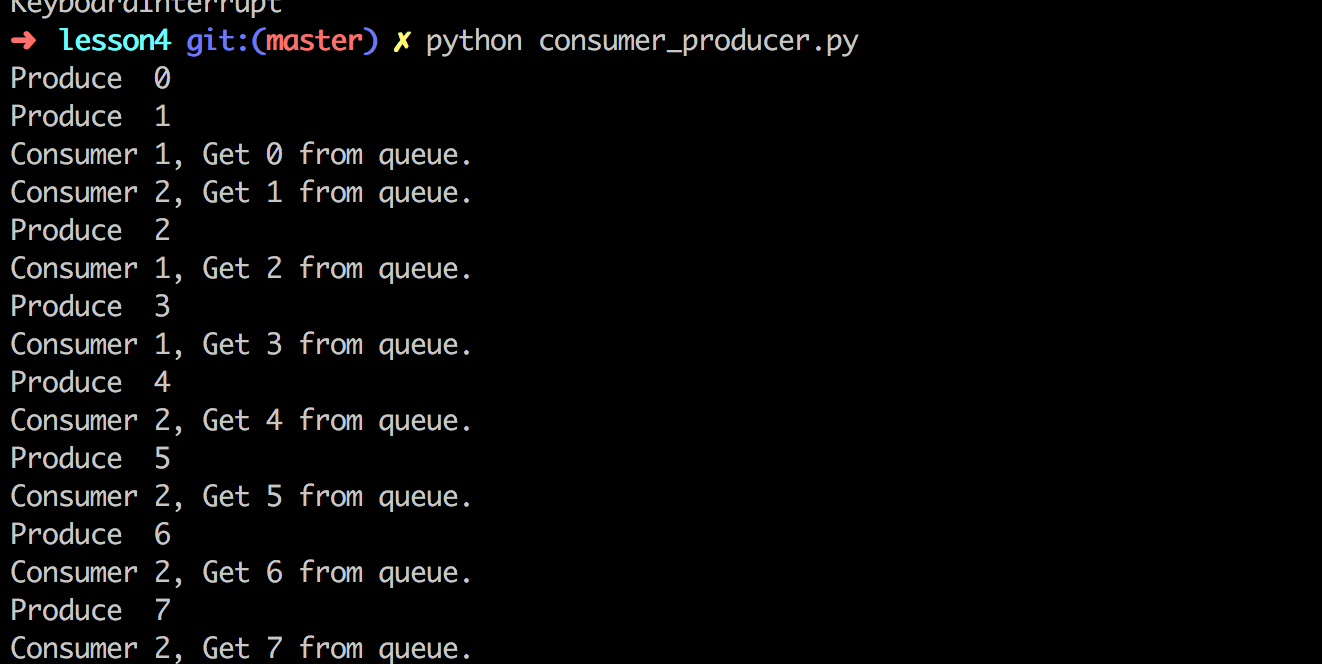
考虑一下“肉多狼少”的情形,代码如下:
from multiprocessing import Process, Queue
import time
def produce(q): # 生产
for i in range(10000):
print("Produce ", i)
q.put(i)
def consume(q): # 消费
while True:
if not q.empty():
value = q.get(True)
print('Consumer 1, Get %s from queue.' % value)
time.sleep(1)
def consume2(q): # 消费
while True:
if not q.empty():
value = q.get(True)
print('Consumer 2, Get %s from queue.' % value)
time.sleep(1)
if __name__ == '__main__':
q = Queue(5) # 队列最多放5个数据, 超过5个则会阻塞住
producer = Process(target=produce, args=(q,))
consumer = Process(target=consume, args=(q,))
consumer2 = Process(target=consume2, args=(q,))
producer.start()
consumer.start()
consumer2.start()
producer.join() # 等待结束, 死循环使用Ctrl+C退出
consumer.join()
consumer2.join()
这里生产者不停的生产,直到把任务队列塞满。而两个消费者每秒钟消费一个,每当有任务被消费掉,生产者又会立马生产出新的任务,把任务队列塞满。
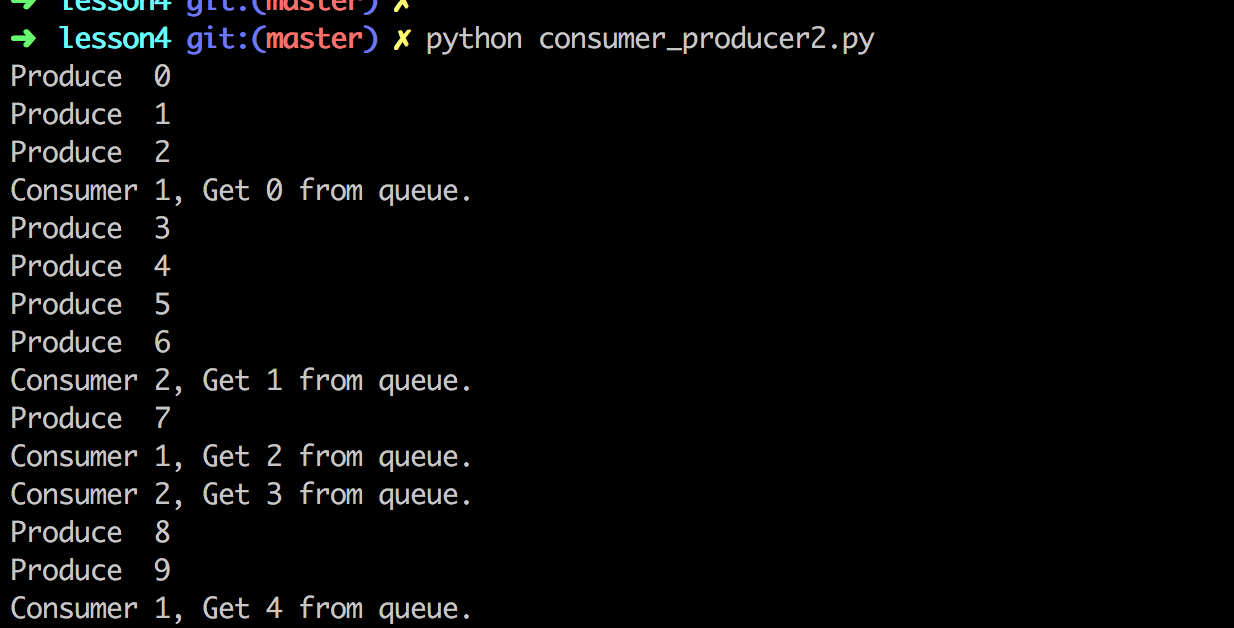
上面的说明,系统整体的运行速度其实受限于速度最慢的那个。像我们爬虫,最耗时的操作就是下载,整体的爬取速度也就受限于网速。
以上的生产和消费者类似爬虫中的Producer和Worker。Producer扮演生产者,生成下载任务,放入任务队列中;Worker扮演消费者,拿到下载任务后,对某个网页进行下载、解析、数据;在此同时,Worker也会扮演生产者,根据解析到的链接生成新的下载任务,并放到任务队列中交给其他的Worker执行。
DIY并发框架
下面我们来看看我们自己的并发爬虫框架,这个爬虫框架的代码很短,只有26行,除去空行的话只有21行代码。
from multiprocessing import Manager, Pool
class SimpleCrawler:
def __init__(self, c_num):
self.task_queue = Manager().Queue() # 任务队列
self.workers = {} # Worker, 字典类型, 存放不同的Worker
self.c_num = c_num # 并发数,开几个进程
def add_task(self, task):
self.task_queue.put(task)
def add_worker(self, identifier, worker):
self.workers[identifier] = worker
def start(self):
pool = Pool(self.c_num)
while True:
task = self.task_queue.get(True)
if task['id'] == "NO": # 结束爬虫
pool.close()
pool.join()
exit(0)
else: # 给worker完成任务
worker = self.workers[task['id']]
pool.apply_async(worker, args=(self.task_queue, task))
这个类中一共就有四个方法:构造方法、添加初始任务方法、设置worker方法、开始爬取方法。
__init__方法:
在构造方法中,我们创建了一个任务队列,(这里注意使用了Manager.Queue(),因为后面我们要用到进程池,所以要用Manager类),workers字典,以及并发数配置。
crawler = SimpleCrawler(5) # 并发数为5
add_task方法:
负责添加初始任务方法,task的形式为一个字典。有id、url等字段。id负责分配给不同的worker。如下:
crawler.add_task({
"id": "worker",
"url": "http://nladuo.cn/scce_site/",
"page": 1
})
add_worker方法:
负责配置worker,以id作为键存放在workers变量中,其中worker可以定义为一个抽象类或者一个函数。这里为了简单起见,我们直接弄一个函数。
def worker(queue, task):
url = task["url"]
resp = requests.get(url)
# ......,爬取解析网页
queue.put(new_task) # 可能还会添加新的task
# ......
crawler.add_worker("worker", worker)
start方法:
start方法就是启动爬虫,这里看上面的代码,创建了一个进程池用来实现并发。然后不断的从queue中取出任务,根据任务的id分配给对应id的worker。我们这里规定当id为“NO”时,我们则停止爬虫。
crawler.start()
爬取两级页面
下面,我们来使用这个简单的爬虫框架,来实现一个两级页面的爬虫。
首先看第一级页面:nladuo.cn/scce_site/。其实就是之前的新闻列表页。我们可以爬到新闻的标题,以及该标题对应的网页链接。
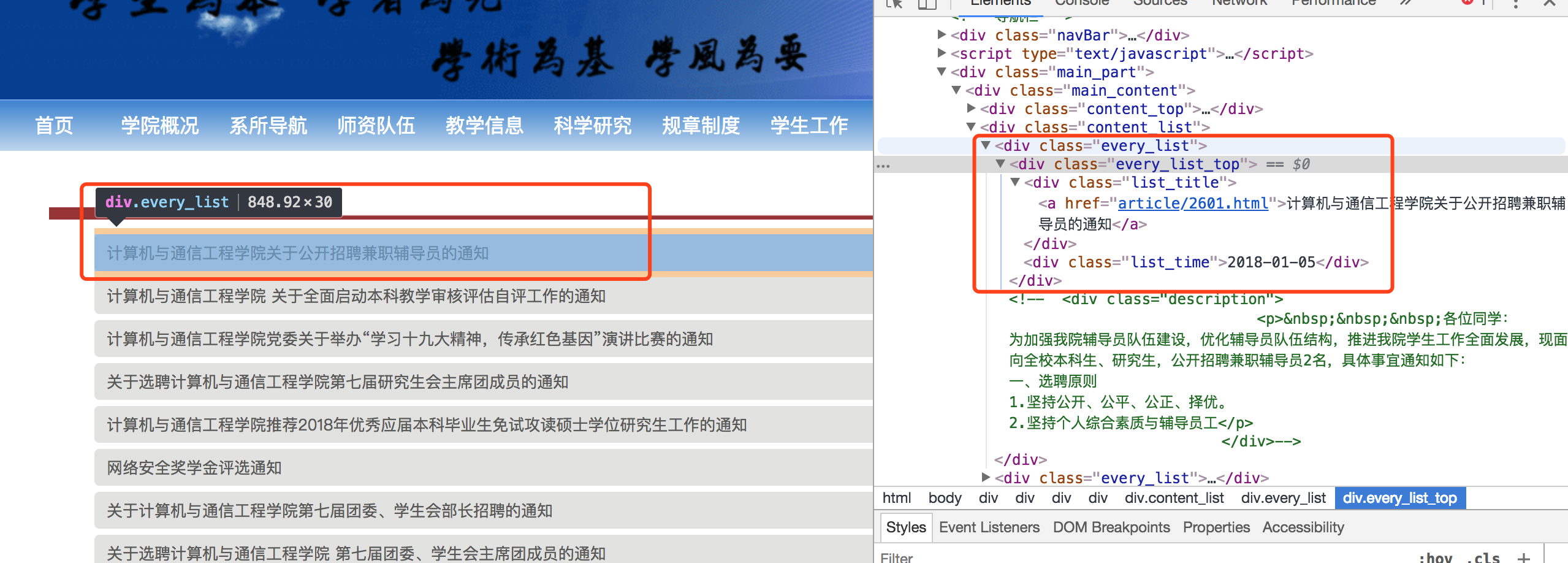
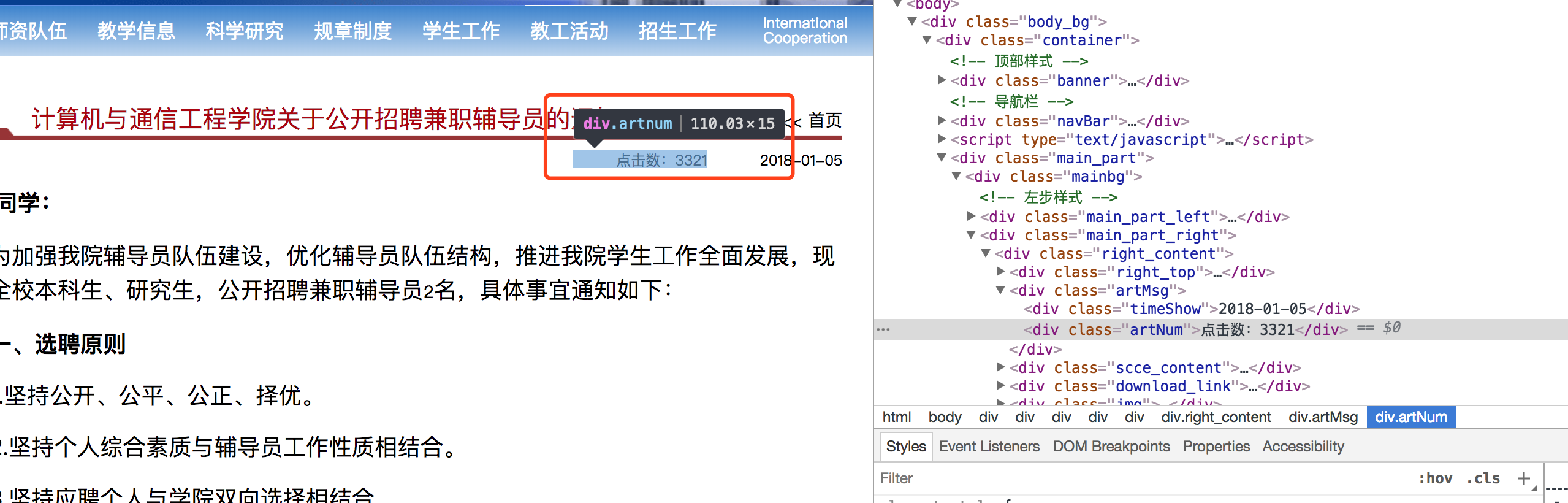
第二级页面是:nladuo.cn/scce_site/a…,也就是新闻的详情页,这里可以获取到新闻的内容以及点击数目等。
下面我们创建两个worker,一个负责爬取列表页面,一个负责爬取新闻详情页。
def worker(queue, task):
""" 爬取新闻列表页 """
pass
def detail_worker(queue, task):
""" 爬取新闻详情页 """
pass
主代码
对于main代码,这里首先需要创建一个crawler。然后添加两个worker,id分别为“worker”和“detail_worker”。然后添加一个初始的任务,也就是爬取新闻列表页的首页。
if __name__ == '__main__':
crawler = SimpleCrawler(5)
crawler.add_worker("worker", worker)
crawler.add_worker("detail_worker", detail_worker)
crawler.add_task({
"id": "worker",
"url": "http://nladuo.cn/scce_site/",
"page": 1
})
crawler.start()
worker代码编写
接下来,完成我们的worker代码,worker接受两个参数:queue和task。
- queue: 用于解析网页后,添加新的任务
- task: 要完成的任务
然后worker①首先下载网页,②其次解析网页,③再根据解析的列表进一步需要爬取详情页,所以要添加爬取详情页的任务;④最后判断当前是不是最后一页,如果是就发送退出信号,否则添加下一页的新闻列表爬取任务。
def worker(queue, task):
""" 爬取新闻列表页 """
# 下载任务
url = task["url"] + "%d.html" % task["page"]
print("downloading:", url)
resp = requests.get(url)
# 解析网页
soup = BeautifulSoup(resp.content, "html.parser")
items = soup.find_all("div", {"class", "list_title"})
for index, item in enumerate(items):
detail_url = "http://nladuo.cn/scce_site/" + item.a['href']
print("adding:", detail_url)
# 添加新任务: 爬取详情页
queue.put({
"id": "detail_worker",
"url": detail_url,
"page": task["page"],
"index": index,
"title": item.get_text().replace("\n", "")
})
if task["page"] == 10: # 添加结束信号
queue.put({"id": "NO"})
else:
# 添加新任务: 爬取下一页
queue.put({
"id": "worker",
"url": "http://nladuo.cn/scce_site/",
"page": task["page"]+1
})
detail_worker代码编写
detail_worker的任务比较简单,只要下载任务,然后解析网页并打印即可。这里为了让屏幕输出没那么乱,我们只获取点击数。
def detail_worker(queue, task):
""" 爬取新闻详情页 """
# 下载任务
print("downloading:", task['url'])
resp = requests.get(task['url'])
# 解析网页
soup = BeautifulSoup(resp.content, "html.parser")
click_num = soup.find("div", {"class", "artNum"}).get_text()
print(task["page"], task["index"], task['title'], click_num)
思考
到这里,我们就用我们自己开发的框架实现了一个多级页面的爬虫。读者可以考虑一下以下的问题。
- 如何实现爬虫的自动结束?考虑监控队列的情况和worker的状态。
- 如何实现一个分布式爬虫?考虑使用分布式队列:celery
