

量子位 授权转载 | 公众号 QbitAI
最近,纽约大学、纽约大学上海分校、AWS上海研究院以及AWS MXNet Science Team共同开源了一个面向图神经网络及图机器学习的全新框架,命名为Deep Graph Library(DGL)。
据介绍,这个框架在测试时表现出了良好的性能,能够既快又好地部署深度神经网络。
开源具体信息已经在今天召开的NeurIPS 2018 ML Sys Workshop(Workshop on Systems for ML and Open Source Software)上公布,量子位编辑如下:

深度神经网络在近年来的发展和成功有目共睹。这些网络架构成功的一个重要原因在于其能有效地捕捉到了数据内在的相关性,并在不同的抽象级别构建表示(representation)。
比如,CNN刻画了图片中相邻像素点间的空间不变性;RNN抓住了文本数据的有序线性结构。
CNN和RNN的成功让人思考——我们是否能将此思想拓展到其他结构的数据上呢?事实上,人们一直在探索如何将深度学习应用于更广泛的结构数据中。
早在2014年,Kai Sheng Tai等人就研究了能在文本语法树上训练的树神经网络模型TreeLSTM。这个工作在一定程度上冲击了大家用RNN处理文本的范式,并且用树型结构看待文本数据开创了很多新的研究可能。
从链表到树,从树到图:近年来,对于图神经网络(Graph Neural Network)的研究热潮使得神经网络的应用领域大大增加。
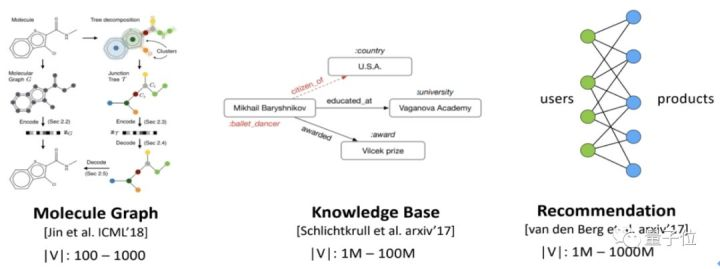
小到分子结构图([Gilmer et al., 2017], [Jin et al., 2018]),大到知识图谱([Schlichtkrull et al., 2017])、社交网络和推荐系统([Ying et al., 2018]),图神经网络都展现了强大的应用潜力。
广义上说,没有一个点的特征表达是孤立的;丰富特征的一个重要手段必然是融合该点和其他邻居点的互动。
从这个意义上来说,CNN和RNN分别把空间和时间上的相邻点看作互动对象是非常粗糙的。把图和深度学习结合的意义正在于突破这个局限。
由于结构数据的普适性,Google, Deepmind, Pinterest等公司也纷纷在这一领域发力。除了数据,深度神经网络模型的发展也有着更加动态和更加稀疏的趋势。
这源于目前深度神经网络对于算力的需求已经达到了一个惊人的地步。同时,我们观察到现在还没有一个框架既高效,又好用,能帮助开发新的模型。
(比如目前火热的BERT模型在一台8块V100的服务器上预计训练时间是42天。)
于是一个很现实的问题是如何设计“既快又好”的深度神经网络?也许更加动态和稀疏的模型会是答案所在。可见,不论是数据还是模型,“图”应该成为一个核心概念。
基于这些思考,我们开发了Deep Graph Library(DGL),一款面向图神经网络以及图机器学习的全新框架。
在设计上,DGL秉承三项原则:
- DGL必须和目前的主流的深度学习框架(Pytorch, MXNet, Tensorflow等)无缝衔接。从而实现从传统的tensor运算到图运算的自由转换。
- DGL应该提供最少的API以降低用户的学习门槛。
- 在保证以上两点的基础之上,DGL能高效并透明地并行图上的计算,以及能很方便地扩展到巨图上。
这里,我们简单介绍DGL是如何实现以上目标的。
设计一:DGL是一个“框架上的框架”
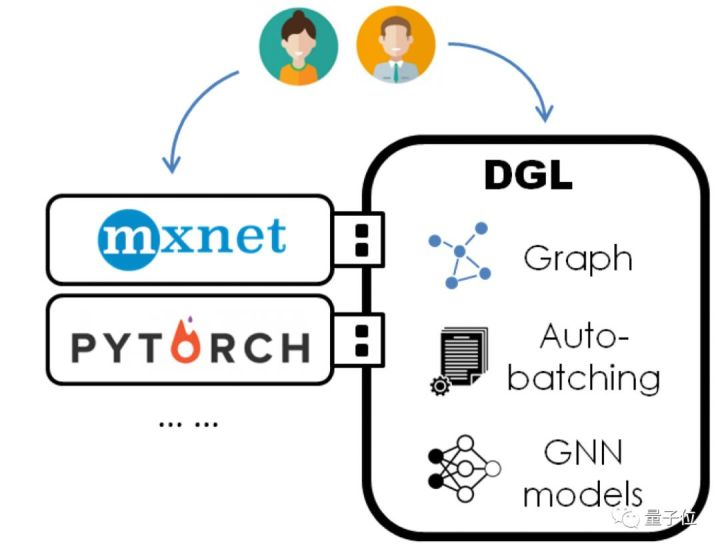
神经网络计算的重要核心是稠密张量计算和自动求导。当前神经网络框架对此都已经有了非常良好的支持。此外,由于神经网络模型的日益模块化,用户对于这些深度学习的框架的黏性度也越来越高。
为了避免重复造轮子(build a wheel again),DGL在设计上采取了类似Keras的做法——基于主流框架之上进行开发。但又不同于Keras,DGL并不限制用户必须使用自己的语法。
相反,DGL鼓励用户在两者间灵活地使用。比如用户可以使用他们偏爱的框架编写常见的卷积层和注意力层,而当遇到图相关的计算时则可以切换为DGL。用户通过DGL调用的计算,经过系统优化,仍然调用底层框架的运算和自动求导等功能,因此开发和调试都能更快上手。
用户和DGL的交互主要通过自定义函数UDF(user-defined function)。在下一节编程模型我们将继续展开。目前DGL支持Pytorch以及MXNet/Gluon作为系统后端。
设计二:基于“消息传递”(message passing)编程模型
消息传递是图计算的经典编程模型。原因在于图上的计算往往可以表示成两步:
- 发送节点根据自身的特征(feature)计算需要向外分发的消息。
- 接受节点对收到的消息进行累和并更新自己的特征。
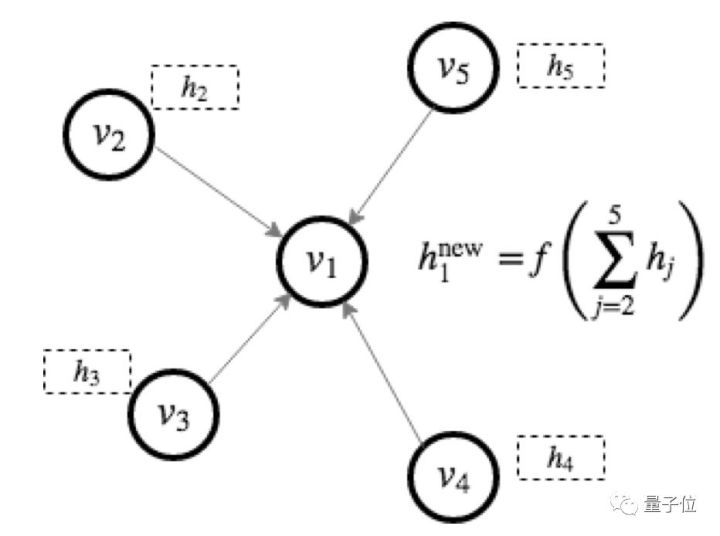
比如常见的卷积图神经网络GCN(Graph Convolutional Network)可以用下图中的消息传递模式进行表示(图中h表示节点各自的特征)。 用户可以定制化消息函数(message function),以及节点的累和更新函数(reduce function)来构造新的模型。事实上,在Google的2017年的论文中 [Gilmer et al. 2017] 将很多图神经网络都归纳到了这一体系内。
DGL的编程模型正基于此。以下是图卷积网络在DGL中的实现(使用Pytorch后端):
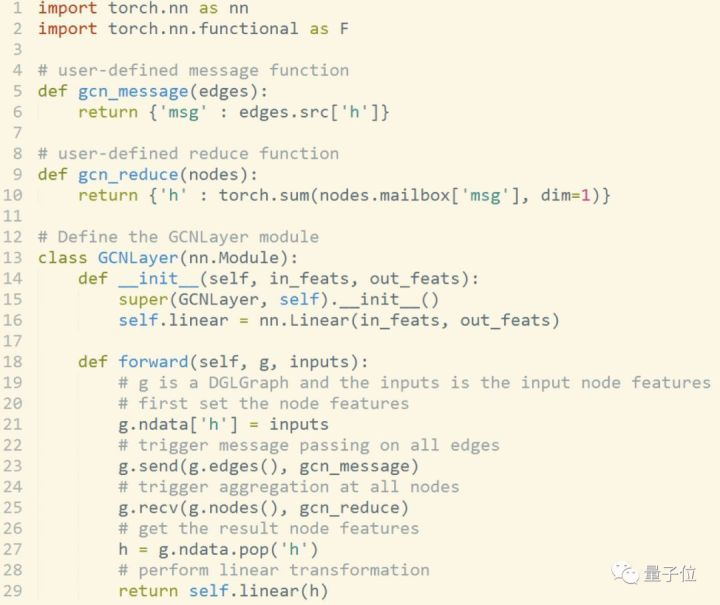
可以看到,用户可以在整个程序中灵活地使用Pytorch运算。而DGL则只是辅助地提供了诸如mailbox, send, recv等形象的消息传递API来帮助用户完成图上的计算。在我们内部的项目预演中,我们发现熟悉深度学习框架的用户可以很快上手DGL并着手开发新模型。
设计三:DGL的自动批处理(auto-batching)
好的系统设计应该是简单透明的。在提供用户最大的自由度的同时,将系统优化最大程度地隐藏起来。图计算的主要难点在于并行。
我们根据模型特点将问题划分为三类。首先是处理单一静态图的模型(比如citation graph),其重点是如何并行计算多个节点或者多条边。DGL通过分析图结构能够高效地将可以并行的节点分组,然后调用用户自定义函数进行批处理。相比于现有的解决方案(比如Dynet和TensorflowFold),DGL能大大降低自动批处理的开销从而大幅提高性能。
第二类是处理许多图的模型(比如module graph),其重点是如何并行不同图间的计算。DGL的解决方案是将多张图合并为一张大图的多个连通分量,从而将该类模型转化为了第一类。
第三类是巨图模型(比如knowledge graph),对此,DGL提供了高效的图采样接口,将巨图变为小图样本,从而转化为第一类问题。
目前DGL提供了10个示例模型,涵盖了以上三种类别。其中除了TreeLSTM,其余都是2017年以后新鲜出炉的图神经网络,其中包括几个逻辑上相当复杂的生成模型(DGMG、JTNN)我们也尝试用图计算的方式重写传统模型比如Capsue和Universal Transformer,让模型简单易懂,帮助进一步扩展思路。
我们也对DGL的性能进行了测试:
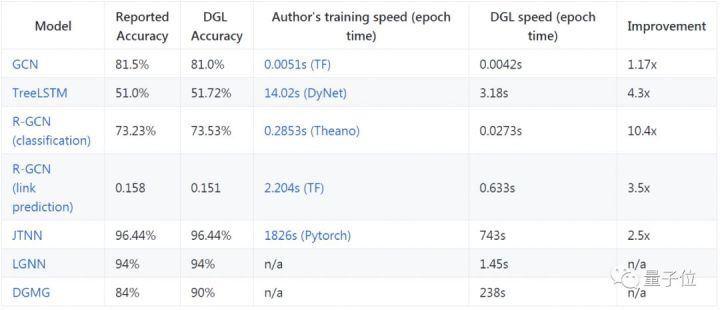
可以看到,DGL能在这些模型上都取得了相当好的效果。我们也对DGL在巨图上的性能进行了测试。在使用MXNet/Gluon作为后端时,DGL能支持在千万级规模的图上进行神经网络训练。
传送门
DGL现已开源,感兴趣可查主页地址:
项目地址:
https://github.com/jermainewang/dgl
对于想了解DGL的初学者,我们推荐从这些教程开始:
https://docs.dgl.ai/tutorials/basics/index.html
同时,所有示例模型,我们都提供了详细的从零开始的教程:
https://docs.dgl.ai/tutorials/models/index.html
我们欢迎任何来自社区的贡献,同时也希望能和大家一起学习进步,推动结构化深度学习这一个新方向。
DGL项目由纽约大学,纽约大学上海分校,AWS上海研究院以及AWS MXNet Science Team共同开发(详见https://www.dgl.ai/ack) 。
— 完 —
量子位 · QbitAI
վ'ᴗ' ի 追踪AI技术和产品新动态
量子位www.zhihu.com
欢迎大家关注我们,以及订阅我们的知乎专栏
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!
相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。
