

在采用 SGD 或者其他的一些优化算法 (Adam, Momentum) 训练神经网络时,通常会使用一个叫 ExponentialMovingAverage (EMA) 的方法,中文名叫指数滑动平均。 它的意义在于利用滑动平均的参数来提高模型在测试数据上的健壮性。
今天我们来介绍一下 EMA。
什么是 MovingAverage?
假设我们得到一个参数 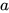 在不同的 epoch 下的值
在不同的 epoch 下的值
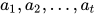
那么,训练结束的 MovingAverage 就是:
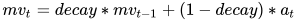
decay 代表衰减率,该衰减率用于控制模型更新的速度。
通过上式,容易得到
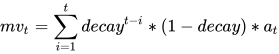
当 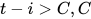 无穷大的时候
无穷大的时候
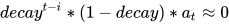
所以
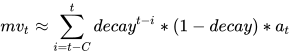
即 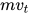 只和
只和 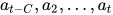 有关
有关
什么是 ExponentialMovingAverage?
有了之前的铺垫,下面引入 EMA 的公式。
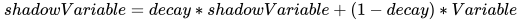
shadowVariable 为最后经过 EMA 处理后得到的参数值,Variable 为当前 epoch 轮次的参数值。
EMA 对每一个待更新训练学习的变量 (variable) 都会维护一个影子变量 (shadow variable)。影子变量的初始值就是这个变量的初始值。
由上述公式可知, decay 控制着模型更新的速度,越大越趋于稳定。实际运用中,通常会设为一个十分接近 1 的常数 (0.999 或 0.9999)。
PyTorch 代码实现
下面看看代码实现
class EMA():
def __init__(self, decay):
self.decay = decay
self.shadow = {}
def register(self, name, val):
self.shadow[name] = val.clone()
def get(self, name):
return self.shadow[name]
def update(self, name, x):
assert name in self.shadow
new_average = (1.0 - self.decay) * x + self.decay * self.shadow[name]
self.shadow[name] = new_average.clone()使用方法,分为初始化、注册和更新三个步骤。
// init
ema = EMA(0.999)
// register
for name, param in model.named_parameters():
if param.requires_grad:
ema.register(name, param.data)
// update
for name, param in model.named_parameters():
if param.requires_grad:
ema.update(name, param.data)