

经历了改名、抢票和论文评审等等风波的「预热」,第 32 届 NeurIPS 于当地时间 12 月 3 日在加拿大蒙特利尔正式开幕。机器之心有幸参与了「第一届 NeurIPS」。
在大会第一天的 Opening Remarks 上,NeurIPS 2018 公布了本届大会的获奖论文。来自多伦多大学的陈天琦、麦克马斯特大学的 Hassan Ashtiani、谷歌 AI 的 Tyler Lu,以及华为诺亚方舟实验室的 Kevin Scaman 等人成为了最佳论文奖的获得者。
作为人工智能的顶级会议,NeurIPS 究竟有多火?首先,让我们看看参会人数的变化:2016 年有 5000 人注册参加该会议,2017 年参会人数飙升至 8000,今年参会人数近 9000,且出现了 11 分钟大会门票被抢光的盛况,仅次于 Beyonce 音乐会的售票速度。
在活动方面,今年新增了 Expo 环节,吸引了全球 32 家公司的参与。在 12 月 2 日的 Expo 中,这些公司共组织了 15 场 Talk&Pannel、17 场 Demonstration、10 场 workshop。此外,为期一周的整个大会包含 4 个 tutorial session、5 场 invited talk、39 场 workshop 等。

至于论文方面,NeurIPS 2018 共收到 4856 篇投稿,创历史最高记录,最终录取了 1011 篇论文,其中 Spotlight 168 篇 (3.5%),oral 论文 30 篇 (0.6%)。
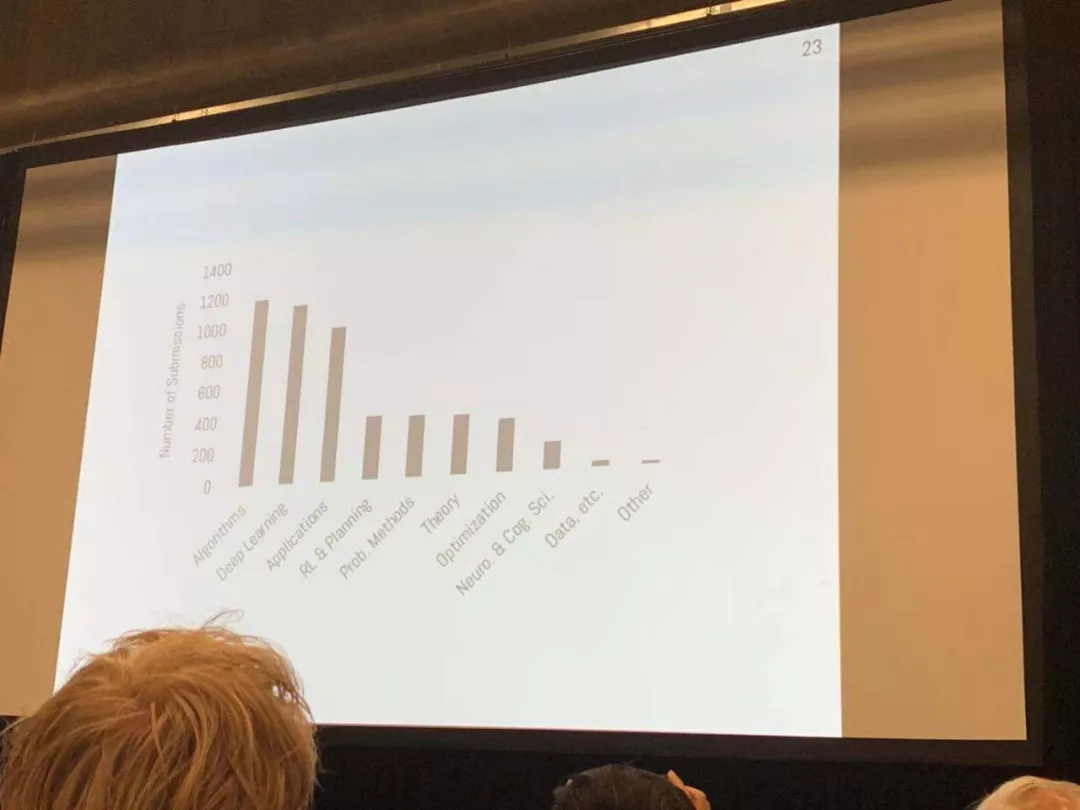
而这些论文涉及的主题包括算法、深度学习、应用、强化学习与规划等。大会程序委员联合主席表示,这些提交论文中,69% 的论文作者表示将放出代码(结果只有 44%),42% 将公布数据。
介绍完大会基本信息,我们来看看今年的最佳论文:
4 篇最佳论文(Best paper awards)
论文:Neural Ordinary Differential Equations
作者:Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, David Duvenaud(四人均来自多伦多大学向量研究所)
链接:https://papers.nips.cc/paper/7892-neural-ordinary-differential-equations.pdf
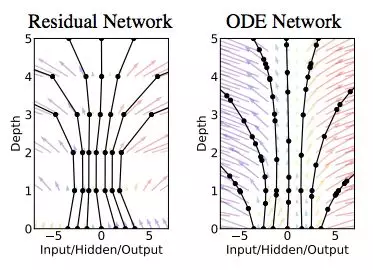
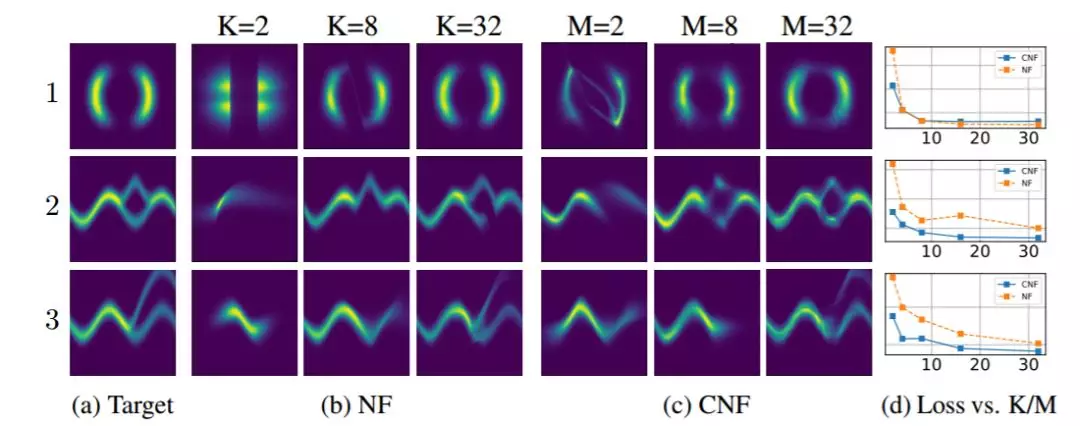
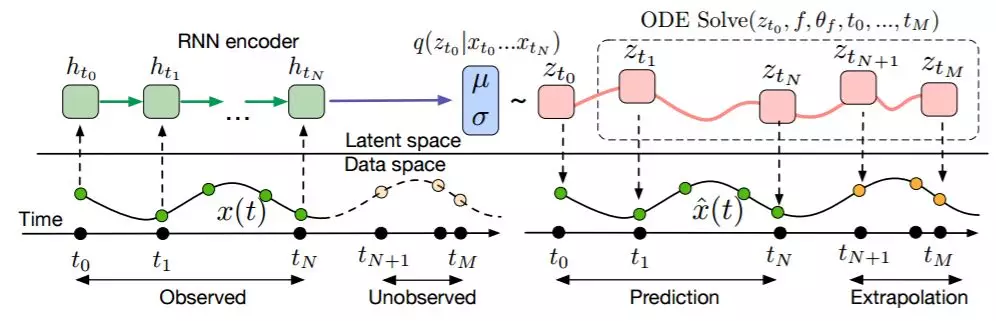
摘要:本研究介绍了一种新的深度神经网络模型家族。我们并没有规定一个离散的隐藏层序列,而是使用神经网络将隐藏状态的导数参数化。然后使用黑箱微分方程求解器计算该网络的输出。这些连续深度模型(continuous-depth model)的内存成本是固定的,它们根据输入调整评估策略,并显式地用数值精度来换取运算速度。我们展示了连续深度残差网络和连续时间隐变量模型的特性。此外,我们还构建了连续的归一化流,即一个可以使用最大似然训练的生成模型,无需对数据维度进行分割或排序。至于训练,我们展示了如何基于任意 ODE 求解器进行可扩展的反向传播,无需访问 ODE 求解器的内部操作。这使得在较大模型内也可以实现 ODE 的端到端训练。
论文:Nearly tight sample complexity bounds for learning mixtures of Gaussians via sample compression schemes
作者:Hassan Ashtiani、Shai Ben-David 等(麦克马斯特大学、滑铁卢大学等)
链接:https://papers.nips.cc/paper/7601-nearly-tight-sample-complexity-bounds-for-learning-mixtures-of-gaussians-via-sample-compression-schemes.pdf
本文作者证明了 样本对于学习 R^d 中 k-高斯混合模型是必要及充分的,总变分距离的误差为ε。这一研究改善了该问题的已知上限和下限。对于轴对齐高斯混合模型,本文表明
样本是充分的,与已知的下限相匹配。其上限的证明基于一种基于样本压缩概念的分布学习新技术。任何允许这种样本压缩方案的类别分布也可以用很少的样本来学习。此外,如果一类分布有这样的压缩方案,那么这些分布的乘积和混合也是如此。本研究的核心结果是证明了 R^d 中的高斯类别具有有效的样本压缩。
论文:Non-delusional Q-learning and value-iteration
作者:Tyler Lu(Google AI)、Dale Schuurmans(Google AI)、Craig Boutilier(Google AI)
链接:https://papers.nips.cc/paper/8200-non-delusional-q-learning-and-value-iteration.pdf
摘要:本研究发现了使用函数近似的 Q-learning 和其它形式的动态规划中的一个基本误差源。当近似架构限制了可表达贪婪策略的类别时,就会产生 delusional bias。由于标准 Q 更新对于可表达的策略类作出了全局不协调的动作选择,因此会导致不一致甚至冲突的 Q 值估计,进而导致高估/低估、不稳定、发散等病态行为。为了解决这个问题,作者引入了一种新的策略一致性概念,并定义了一个本地备份过程,该过程通过使用信息集(这些信息记录了与备份 Q 值一致的策略约束)来确保全局一致性。本文证明,基于模型和无模型的算法都可以利用这种备份消除 delusional bias,并产生了第一批能够保证一般情况下最佳结果的已知算法。此外,这些算法只需要多项式的信息集(源于潜在的指数支持)。最后,作者建议了其它尝试消除 delusional bias 的实用价值迭代和 Q-learning 的启发式方法。
论文:Optimal Algorithms for Non-Smooth Distributed Optimization in Networks
作者:Kevin Scaman(华为诺亚方舟实验室)、Francis Bach(PSL 研究大学)、Sébastien Bubeck(微软研究院)、Yin Tat Lee(微软研究院)、Laurent Massoulié(PSL 研究大学)
链接:https://papers.nips.cc/paper/7539-optimal-algorithms-for-non-smooth-distributed-optimization-in-networks.pdf
摘要:本研究考虑使用计算单元网络对非光滑凸函数进行分布式优化。我们在两种规则假设下研究该问题:1)全局目标函数的利普希茨连续;2)局部单个函数的利普希茨连续。在局部假设下,我们得到了最优一阶分散式算法(decentralized algorithm)——多步原始对偶(multi-step primal-dual,MSPD)及其对应的最优收敛速率。该结果重要的方面在于,对于非光滑函数,尽管误差的主要项在 O(1/ sqrt(t)) 中,但通讯网络(communication network)的结构仅影响 O(1/t) 中的二阶项(t 是时间)。也就是说,通讯资源限制导致的误差会以非常快的速度降低,即使是在非强凸目标函数中。在全局假设下,我们得到了一个简单但高效的算法——分布式随机平滑(distributed randomized smoothing,DRS)算法,它基于目标函数的局部平滑。研究证明 DRS 的最优收敛速率在 d^(1/4) 乘积因子内(d 是潜在维度)。
经典论文奖(Test of time award)
去年的经典论文颁给了核函数加速训练方法,今年的经典论文也是一篇偏理论的研究论文,它们都是 2007 年的研究。
论文:The Tradeoffs of Large Scale Learning
作者:Le´on Bottou(NEC laboratories of America)、Olivier Bousquet(谷歌)
链接:https://papers.nips.cc/paper/3323-the-tradeoffs-of-large-scale-learning.pdf
该论文的贡献在于开发了一个理论框架,其考虑了近似优化对学习算法的影响。该分析展示了小规模学习和大规模学习的显著权衡问题。小规模学习受到一般近似估计权衡的影响,而大规模学习问题通常要在质上进行不同的折中,且这种权衡涉及潜在优化算法的计算复杂度,它基本上是不可求解的。

作为本次大会的受邀媒体,机器之心来到了蒙特利尔,参与了本次 NeruIPS 大会。未来几天,我们还将发来最新现场报道,敬请期待。

NeurIPS 2018相关论文链接:
NeurIPS 2018提前看:生物学与学习算法
NeurIPS 2018,最佳论文也许就藏在这30篇oral论文中
NeurIPS 2018 | 腾讯AI Lab&北大提出基于随机路径积分的差分估计子非凸优化
NeurIPS 2018亮点选读:深度推理学习中的图网络与关系表征
NeurIPS 2018提前看:可视化神经网络泛化能力
Google AI提出物体识别新方法:端到端发现同类物体最优3D关键点——NeurIPS 2018提前看
MIT等提出NS-VQA:结合深度学习与符号推理的视觉问答
画个草图生成2K高清视频,这份效果惊艳研究值得你跑一跑
下一个GAN?OpenAI提出可逆生成模型Glow
CMU、NYU与FAIR共同提出GLoMo:迁移学习新范式
Quoc Le提出卷积网络专属正则化方法DropBlock
Edward2.2,一种可以用TPU大规模训练的概率编程
南大周志华等人提出无组织恶意攻击检测算法UMA
MIT新研究参透批归一化原理
程序翻译新突破:UC伯克利提出树到树的程序翻译神经网络
将RNN内存占用缩小90%:多伦多大学提出可逆循环神经网络
哪种特征分析法适合你的任务?Ian Goodfellow提出显著性映射的可用性测试
行人重识别告别辅助姿势信息,商汤、中科大提出姿势无关的特征提取GAN
作为多目标优化的多任务学习:寻找帕累托最优解
Dropout可能要换了,Hinton等研究者提出神似剪枝的Targeted Dropout
利用Capsule重构过程,Hinton等人实现对抗样本的自动检测
