

内容来源:2018 年 11 月 10 日,SOUG联合创始人周亮在“2018 SOUG年度数据库技术峰会”进行《Oracle AI 性能优化指南探讨》的演讲分享。IT 大咖说作为独家视频合作方,经主办方和讲者审阅授权发布。
阅读字数:3313 | 9分钟阅读
获取嘉宾演讲视频及PPT,请点击:t.cn/EyZX8Q6。
 摘要
摘要
Oracle AI 性能优化指南探讨。现在我们绝大部分的运维工作还是集中在文档化定位、脚本化、运维工具化,虽然这三大块里面已经有很多企业实现了部分的自动化运维,但是我相信很多时候还是靠人肉为主。
运维发展阶段
运维发展的第一个阶段是无序化运维,也就是所谓的水来土淹,兵来将挡,有故障了就处理,没故障就喝茶看报,文档也没有,全靠人工处理。下一阶段是文档化运维,这应该是现在绝大部分的人所处的阶段,一些故障和心得会被写到文档里面,形成知识手册,或者博客文章等。
再往下是脚本化运维,有了脚本之后下一任的人员接手就会简单很多,他只需要知道脚本的用途和使用方式就行了,至于细节方面,一开始并不需要了解太多,除非是要对脚本进行量身定制化,
工具化运维是脚本化运维的升级,将脚本打包成工具使用,比如说自动化运维平台、性能优化平台、监控平台,简单来说就是将所用的脚本归档集中起来。然后是自动化运维,关于这方面的讨论这几年非常火,各种大会上都在讲自动化。根据我的观察,目前自动化运维主要在做那么一件或两件事,大多是一些不需要太多的流程,不需要太多的人工智能的事情。比如说安装部署、空间扩容。虽然自动化在互联网企业中推行了开来,但是在传统企业里面,自动化有一个很大的瓶颈在,那就是不够标准化。所谓的不够标准化,指的是我们的机房环境错综复杂,自动化运维很难部署下去。
最后是智能化运维,这是也本次要讲的一个比较重要的主题。所谓的智能化运维就是让机器去干人的事情,让机器学习人的思想,再通过人工智能的一些手段实现出来。
现在我们绝大部分的运维工作还是集中在文档化定位、脚本化、运维工具化,虽然这三大块里面已经有很多企业实现了部分的自动化运维,但是我相信很多时候还是靠人肉为主。
所谓的自动化运维也只是在简单的接受一些告警,这些告警往往是海量的,运维人员看多了也就麻痹掉了,不会再去看。所以说自动化运维只是实现了部分告警让机器去做,可能安装部所巡检还是人在做。而智能化运维甚至还在起步阶段,或者说在概念的阶段。
AI性能运维需求
作为一个非甲方公司,我们考虑的智能化性能,必须要兼容所有的数据,这是一个大的前提。不同的数据库的类型,智能化运维需求是不一样的。比如小型数据库,主机的负载很低的,并发也不高的,空间往往小于500G,其性能问题往往是有SQL执行效率引起的,比如SQL执行计划发生变异,一个索性突然变成全量。
对于中大型数据库,他们的主机资源负载或者事务并发都比较高,大致情况可能是每秒钟有100个以上SQL再解析,每个节点有200个左右的当前的事务在执行。它的性能问题往往不是一条简单的SQL导致的,更多的是受到主机资源不足、数据库资源冲突、SQL执行效率等因素影响。
在这种情况下到底有哪些人需要AI运维呢?我个人来看可能是一些基础不是特别牢固的人员,以平台的形式提供给他们使用,该平台以结果为导向,提供简介明了的操作指南,实现过程性的关联告警,明确问题方向。
我们做性能优化的时候面临的首要难点就是不报错,这对于水平比较低的人来讲就完全没有头绪了。如果有报错,还可以去百度,谷歌或者其他地方查询,只要有足够的时间,就能找到一个问题的方向。因此在智能化运维性能这块,我们要把这些毫无头绪的环节梳理出来。
性能优化的目标
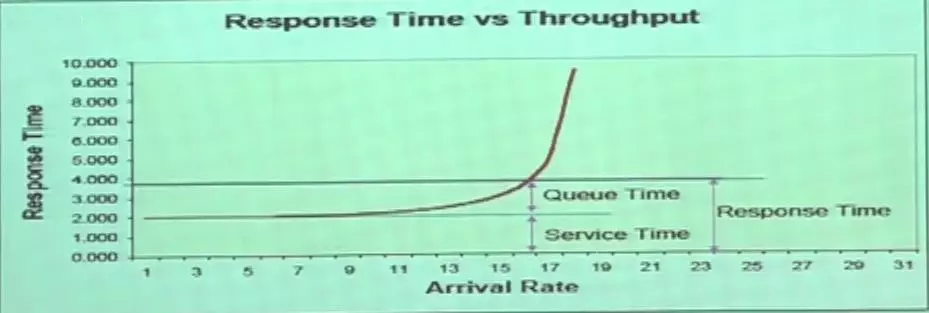
所有的性能优化的目标都是让拐点后移动, 所谓的拐点后移动,就是当压力或者并发积累到一定程度的时候,数据库的吞吐量时间会急剧上升,从缓慢上升到急剧上升的突变点就叫拐点。随着性能优化的持续的投入,我们会把这个点尽量的往后移,让数据库能承受更多的压力,这就是所有的数据库的性能优化的目标。
我们在说性能优化的时候有个关键点——变化,明确的说是寻找变化。因为性能优化是不报错的,所以当数据库出现性能问题的时候,需要数据库出现性能问题前后的比较报告。通过比较两份报告,可以更容易的看出数据库发生了哪些变化,并以此分析出问题点。
AI性能优化关键点
AI性能优化的关键点之一是流程化肢解。如果不把性能优化肢解掉,那就只一笔所谓的一笔糊涂账,我们只知道数据库变慢了,但却不知道具体问题在哪。所以才要把整个数据库性能肢解成几个环节。
从数据库内部的角度来讲,整个数据库本质上是用来读取和存储数据的。现在我们可以把这一环节肢解掉,进一步细分为五个步骤。第一个环节是会访登陆,第二个环节是SQL解析,第三个环节是SQL执行,接着是提交和返回环节。
这样肢解之后,有些问题就可以进行针对性的比较了。如果不这样做,比较的东西就太多了,无法抓住关键点。
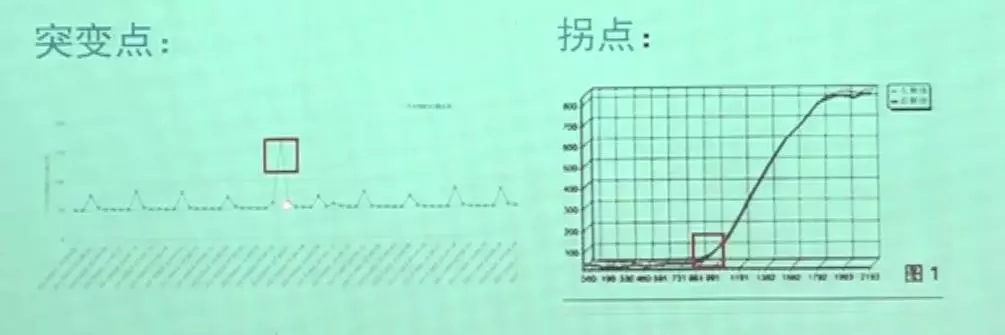
另外一个关键点是寻找拐点和突破点。每个系统所有的数据库,只要放大到一定的时间时间轴后都是有业务节奏的,当其中的某部分不符合业务节奏的时候就会出现问题,这个点就是突破点。
现在业内在做性能优化的时候,大多情况下是没有性能相关的告警的,数据库报错可能会告警出来,但数据库变慢了,我相信很少会有报警,最多也就是CPU 80%以上、空间不足的时候才会有报警。
而如果能寻找出拐点跟突破点的话,完全可以进行性能方面的报警。比如我们通过机器学习已经了解到了系统的业务节奏是什么样的,之后的业务周期内,如果产生新的突破点,在业务感知之前就可以进行报警,指出当前的数据库性能违背了平常的波动规律,可能会出现问题。除了性能告警之外,还可以做一些性能预警。因为已经学习了性能波动曲线,所以可以预测未来的波动情况。
第三个关键点是机器学习,首先学习曲线规律,也就是数据库的指标特征,学习完成后要开始预测变化趋势。随着时间的推移,机器还有很重要的特点,即根据业务节奏的变化,要不停的修正告警阈值,因为业务系统是会不停发展的,另外还有性能预警。
运维数据
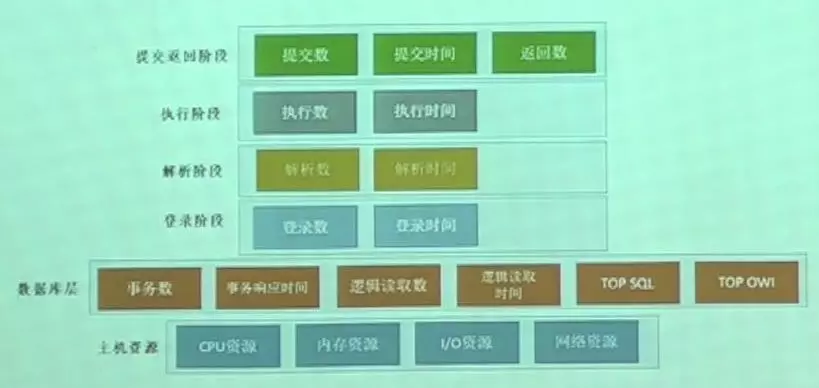
那么怎样提取核心环节和核心指标呢?肯定是从主机资源开始,主机的四大资源必须要提取出来,CPU内存、内存资源、I/O资源、网络资源。再往上是数据库层,它反应了数据库的典型特征,包括事务数、事务响应时间、逻辑读取数、逻辑读取时间、TOP SQL、TOP OWI。
其中逻辑读的次数是一个很能直观反映数据库性能的指标,当SQL执行计划发生变异的时候,比如说正常的索引读取,一条SQL读一条数据可能要十个逻辑读,在比较高效的时候,其实十个数据块都不要,如果索引读刚好在这个数据块的索引里面或者是在根节点里面,可能只要1到2个数据块就行了。但是SQL执行计划发生变异了的话,可能就要全表扫描,这样的话逻辑读的次数就会直线上升。而如果有机器学习抓取的指标在,经过对比后就会告警出来。
接下来是将数据库肢解后的4个阶段,登录、解析、执行、提交返回,分别在这几个阶段进行横向对比。
假设应用报出了数据库慢的问题,你在完全比对了这四个环节之后,发现登陆阶段、解析阶段指标没有波动,但是在执行阶段指标发生波动了,那么就基本可以确定是执行阶段的性能问题导致整个数据库变慢。
后台架构
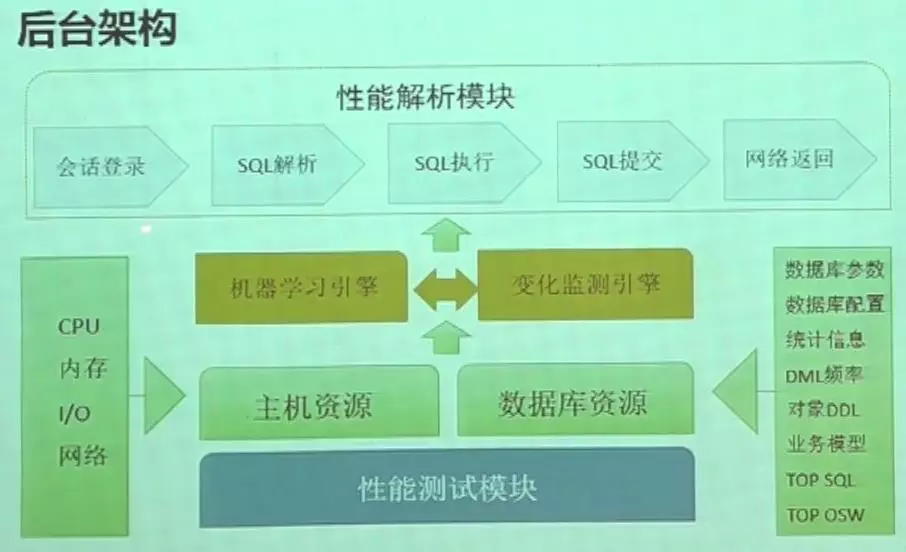
上图是我设想的后台架构,最上方的性能解析模块分成5个部分,下面的登录解析引擎和变化监测引擎互相补充,机器学习引擎是去学习上面五个模块的各种指标,变化检测通过机器学习的指标解释性能的突变点或者拐点在哪里。然后是主机资源和数据库资源,他们是数据库能正常运行的一个前提。
以上为今天的分享内容,谢谢大家!
编者:IT大咖说,转载请标明版权和出处