

版权声明:本套技术专栏是作者(秦凯新)平时工作的总结和升华,通过从真实商业环境抽取案例进行总结和分享,并给出商业应用的调优建议和集群环境容量规划等内容,请持续关注本套博客。版权声明:禁止转载,欢迎学习。QQ邮箱地址:1120746959@qq.com,如有任何问题,可随时联系。
Flink牛刀小试系列目录
- Flink牛刀小试-Flink 集群运行原理兼部署及Yarn运行模式深入剖析
- Flink牛刀小试-Flink Window类型及使用原理案例实战
- Flink牛刀小试-Flink Broadcast 与 Accumulators 应用案例实战
- Flink牛刀小试-Flink与SparkStreaming之Counters& Accumulators 累加器双向应用案例实战
- Flink牛刀小试-Flink分布式缓存Distributed Cache应用案例实战
- Flink牛刀小试-Flink状态管理与checkPoint数据容错机制深入剖析
- Flink牛刀小试-Flink Window分析及Watermark解决乱序数据机制深入剖析
- Flink牛刀小试-Flink Restart Strategies 重启策略机制深入剖析
- Flink牛刀小试-Flink CheckPoint状态点恢复与savePoint机制对比剖析
- Flink牛刀小试-Flink SQL Table 我们一起去看2018中超联赛
- Flink牛刀小试-Flink基于Kafka-Connector 数据流容错回放机制及代码案例实战
- [Flink牛刀小试-Flink DataStreamAPI与DataSetAPI应用案例实战]
- [Flink牛刀小试-Flink并行度 Parallel及Slots关系原理深入剖析]
- [Flink牛刀小试-Flink集群HA配置及高可用机制深入剖析]
- [Flink牛刀小试-Flink批处理与流处理案例实战深入剖析]
- [Flink牛刀小试-Flink综合性应用案例实践及垂直业务深入剖析]
1 Kafka-connector 再次亲密牵手Flink
- Kafka中的partition机制和Flink的并行度机制深度结合,实现数据恢复。
- Kafka可以作为Flink的source和sink,牛在这里。
- 任务失败,通过设置kafka的offset来恢复应用
2 回顾Spark Streaming针对kafka使用技术
// 设置检查点目录
ssc.checkpoint("./streaming_checkpoint")
// 获取Kafka配置(通过配置文件读取,ConfigurationManager自定义方法)
val broker_list = ConfigurationManager.config.getString("kafka.broker.list")
val topics = ConfigurationManager.config.getString("kafka.topics")
// kafka消费者配置
val kafkaParam = Map(
"bootstrap.servers" -> broker_list,//用于初始化链接到集群的地址
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
//用于标识这个消费者属于哪个消费团体
"group.id" -> "commerce-consumer-group",
//如果没有初始化偏移量或者当前的偏移量不存在任何服务器上,可以使用这个配置属性
//可以使用这个配置,latest自动重置偏移量为最新的偏移量
"auto.offset.reset" -> "latest",
//如果是true,则这个消费者的偏移量会在后台自动提交
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// 创建DStream,返回接收到的输入数据
// LocationStrategies:根据给定的主题和集群地址创建consumer
// LocationStrategies.PreferConsistent:持续的在所有Executor之间分配分区
// ConsumerStrategies:选择如何在Driver和Executor上创建和配置Kafka Consumer
// ConsumerStrategies.Subscribe:订阅一系列主题
val adRealTimeLogDStream=KafkaUtils.createDirectStream[String,String](ssc,
LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String,String](Array(topics),kafkaParam))
3 再论 Flink Kafka Consumer

3.1 理论时间
-
setStartFromGroupOffsets()【默认消费策略】
默认读取上次保存的offset信息 如果是应用第一次启动,读取不到上次的offset信息,则会根据这个参数auto.offset.reset的值来进行消费数据
-
setStartFromEarliest() 从最早的数据开始进行消费,忽略存储的offset信息
-
setStartFromLatest() 从最新的数据进行消费,忽略存储的offset信息
-
setStartFromSpecificOffsets(Map<KafkaTopicPartition, Long>)
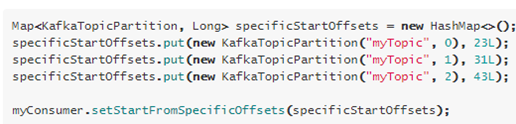
-
当checkpoint机制开启的时候,KafkaConsumer会定期把kafka的offset信息还有其他operator的状态信息一块保存起来。当job失败重启的时候,Flink会从最近一次的checkpoint中进行恢复数据,重新消费kafka中的数据。
-
为了能够使用支持容错的kafka Consumer,需要开启checkpoint env.enableCheckpointing(5000); // 每5s checkpoint一次
-
Kafka Consumers Offset 自动提交有以下两种方法来设置,可以根据job是否开启checkpoint来区分:
(1) Checkpoint关闭时: 可以通过下面两个参数配置
enable.auto.commit
(2) Checkpoint开启时:当执行checkpoint的时候才会保存offset,这样保证了kafka的offset和checkpoint的状态偏移量保持一致。 可以通过这个参数设置
setCommitOffsetsOnCheckpoints(boolean)
这个参数默认就是true。表示在checkpoint的时候提交offset, 此时,kafka中的自动提交机制就会被忽略
3.2 案例实战
依赖引入:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.3</version>
</dependency>
案例实战:
public class StreamingKafkaSource {
public static void main(String[] args) throws Exception {
//获取Flink的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//checkpoint配置
env.enableCheckpointing(5000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//设置statebackend
//env.setStateBackend(new RocksDBStateBackend("hdfs://hadoop100:9000/flink/checkpoints",true));
String topic = "kafkaConsumer";
Properties prop = new Properties();
prop.setProperty("bootstrap.servers","SparkMaster:9092");
prop.setProperty("group.id","kafkaConsumerGroup");
FlinkKafkaConsumer011<String> myConsumer = new FlinkKafkaConsumer011<>(topic, new SimpleStringSchema(), prop);
myConsumer.setStartFromGroupOffsets();//默认消费策略
DataStreamSource<String> text = env.addSource(myConsumer);
text.print().setParallelism(1);
env.execute("StreamingFromCollection");
}
}
4 再论 Flink Kafka Producer
4.1 理论时间
-
Kafka Producer的容错-Kafka 0.9 and 0.10
-
如果Flink开启了checkpoint,针对FlinkKafkaProducer09和FlinkKafkaProducer010 可以提供 at-least-once的语义,还需要配置下面两个参数:
setLogFailuresOnly(false)
setFlushOnCheckpoint(true)
-
注意:建议修改kafka 生产者的重试次数retries【这个参数的值默认是0】
-
Kafka Producer的容错-Kafka 0.11,如果Flink开启了checkpoint,针对FlinkKafkaProducer011 就可以提供 exactly-once的语义,但是需要选择具体的语义
Semantic.NONE
Semantic.AT_LEAST_ONCE【默认】
Semantic.EXACTLY_ONCE
4.2 KafkaSink案例实战
public class StreamingKafkaSink {
public static void main(String[] args) throws Exception {
//获取Flink的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//checkpoint配置
env.enableCheckpointing(5000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//设置statebackend
//env.setStateBackend(new RocksDBStateBackend("hdfs://SparkMaster:9000/flink/checkpoints",true));
DataStreamSource<String> text = env.socketTextStream("SparkMaster", 9001, "\n");
String brokerList = "SparkMaster:9092";
String topic = "kafkaProducer";
Properties prop = new Properties();
prop.setProperty("bootstrap.servers",brokerList);
//第一种解决方案,设置FlinkKafkaProducer011里面的事务超时时间
//设置事务超时时间
//prop.setProperty("transaction.timeout.ms",60000*15+"");
//第二种解决方案,设置kafka的最大事务超时时间,主要是kafka的配置文件设置。
//FlinkKafkaProducer011<String> myProducer = new FlinkKafkaProducer011<>(brokerList, topic, new SimpleStringSchema());
//使用仅一次语义的kafkaProducer
FlinkKafkaProducer011<String> myProducer = new FlinkKafkaProducer011<>(topic, new KeyedSerializationSchemaWrapper<String>(new SimpleStringSchema()), prop, FlinkKafkaProducer011.Semantic.EXACTLY_ONCE);
text.addSink(myProducer);
env.execute("StreamingFromCollection");
}
}
5 结语
kafka必不可少,关于kafka还有很多要说的内容,详情请参考我的kafka商业环境实战系列吧。
版权声明:本套技术专栏是作者(秦凯新)平时工作的总结和升华,通过从真实商业环境抽取案例进行总结和分享,并给出商业应用的调优建议和集群环境容量规划等内容,请持续关注本套博客。版权声明:禁止转载,欢迎学习。QQ邮箱地址:1120746959@qq.com,如有任何问题,可随时联系。
- kafka 商业环境实战-kafka生产环境规划
- kafka 商业环境实战-kafka生产者和消费者吞吐量测试
- kafka 商业环境实战-kafka生产者Producer参数设置及参数调优建议
- kafka 商业环境实战-kafka集群管理重要操作指令运维兵书
- kafka 商业环境实战-kafka集群Broker端参数设置及调优准则建议
- kafka 商业环境实战-kafka之Producer同步与异步消息发送及事务幂等性案例应用实战
- kafka 商业环境实战-kafka Poll轮询机制与消费者组的重平衡分区策略剖析
- kafka 商业环境实战-kafka Rebalance 机制与Consumer多种消费模式案例应用实战
- kafka 商业环境实战-kafka集群消息格式之V1版本到V2版本的平滑过渡详解
- kafka 商业环境实战-kafka ISR设计及水印与leader epoch副本同步机制深入剖析
- kafka 商业环境实战-kafka日志索引存储及Compact机制深入剖析
- [kafka 商业环境实战-kafka精确一次语义EOS的原理深入剖析]
- [kafka 商业环境实战-kafka消息的幂等性与事务支持机制深入剖析]
- [kafka 商业环境实战-kafka集群Controller竞选与责任设计思路架构详解]
- [kafka 商业环境实战-kafka集群日志文件系统设计与留存机制及Compact深入研究]
- [kafka 商业环境实战-kafka集群Consumer group状态机及Coordinaor管理深入剖析]
- [kafka 商业环境实战-kafka调优过程在吞吐量,持久性,低延时,可用性等指标的折中选择研究]
秦凯新 于深圳 20181127023
