

《HBase 不睡觉书》是一本让人看了不会睡着的 HBase 技术书籍,写的非常不错,为了加深记忆,决定把书中重要的部分整理成读书笔记,便于后期查阅,同时希望为初学 HBase 的同学带来一些帮助。
目录
- 第一章 - 初识 HBase
- 第二章 - 让 HBase 跑起来
- 第三章 - HBase 基本操作
- 第四章 - 客户端 API 入门
- 第五章 - HBase 内部探险
- 第六章 - 客户端 API 的高阶用法
- 第七章 - 客户端 API 的管理功能
- 第八章 - 再快一点
- 第九章 - 当 HBase 遇上 MapReduce
本文主要介绍 hbase shell 的使用。
一、表操作(DDL)
1、启动 HBase Shell
一般的数据库都有命令行工具,HBase 也自带了一个用 JRuby(JRuby 是用 Java 写的 Ruby 解释器)写的 shell 命令行工具,执行以下命令来进入 HBase 的 shell:
# 一般集群安装好可以直接使用 hbase shell 启动
$ HBASE_HOME/bin/hbase shell
2、新建表(create)
新建表需要注意的几点:
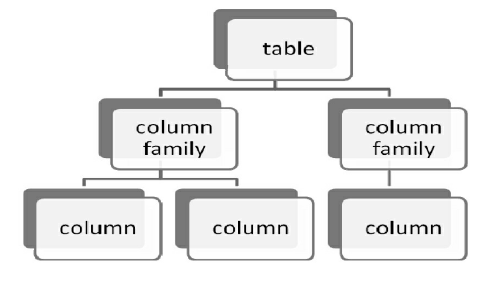
- HBase 的表都是由列族(Column Family)组成的;
- 没有列族的表是没有意义的;
- 列并不是依附于表上,而是依附于列族上。
可用通过下面的命令新建一个表:
# 新建一个表 'test',包含了一个列族 'cf'
# HBase 新建表时,至少需要一个列族
create 'test', 'cf'
3、查看数据库表(list)
用list命令可以看到整个库中有哪些表:
hbase(main):010:0> list
TABLE
test
test1
test3
3 row(s)
Took 0.0048 seconds
=> ["test", "test1", "test3"]
4、查看表属性(describe)
用 describe 命令查看表的元信息:
hbase(main):018:0> describe "test"
Table test is ENABLED
test
COLUMN FAMILIES DESCRIPTION
{
NAME => 'cf',
VERSIONS => '1',
EVICT_BLOCKS_ON_CLOSE => 'false',
NEW_VERSION_BEHAVIOR => 'false',
KEEP_DELETED_CELLS => 'FALSE',
CACHE_DATA_ON_WRITE => 'false',
DATA_BLOCK_ENCODING => 'NONE',
TTL => 'FOREVER',
MIN_VERSIONS => '0',
REPLICATION_SCOPE => '0',
BLOOMFILTER => 'ROW',
CACHE_INDEX_ON_WRITE => 'false',
IN_MEMORY => 'false',
CACHE_BLOOMS_ON_WRITE => 'false',
PREFETCH_BLOCKS_ON_OPEN => 'false',
COMPRESSION => 'NONE',
BLOCKCACHE => 'true',
BLOCKSIZE => '65536'
}
1 row(s)
Took 0.0504 seconds
可以看到,默认是没有设置压缩和数据块编码。
5、删除表(drop)
在删除 HBase 表之前的时候,必须先执行停用(disable)命令,因为可能有很多客户端现在正好连着,而且也有可能 HBase 正在做合并或者分裂操作。如果你这时删除了表,会造成无法恢复的错误,HBase 也不会让你直接就删除表,而是需要先做一个 disable 操作,意思是把这个表停用掉,并且下线。
hbase(main):019:0> disable "test"
Took 0.8052 seconds
hbase(main):020:0> drop "test"
Took 0.4512 seconds
hbase(main):021:0>
在没有什么数据或者没有什么人使用的情况下 disable 命令执行得很快,但如果在系统已经上线了,并且负载很大的情况下 disable 命令会执行得很慢,因为 disable 要通知所有的 RegionServer 来下线这个表,并且有很多涉及该表的操作需要被停用掉,以保证该表真的已经完全不参与任何工作了。
6、修改表(alter)
可以使用 alter 命令对表进行修改,修改时无需禁用表,但是强烈建议在生产环境下执行这个命令之前,最好先停用(disable)这个表。因为对列族的所有操作都会同步到 所有拥有这个表的 RegionServer 上,当有很多客户端都在连着的时候,直接新增一个列族对性能的影响较大(还有可能出现意外的问题)。
# 修改多个属性
alter 't1', 'f1', {NAME => 'f2', IN_MEMORY => true}, {NAME => 'f3', VERSIONS => 5}
# 新增列族
alter 't1', 'cf2'
# 删除列族
alter 't1', NAME => 'f1', METHOD => 'delete'
二、数据操作(DML)
1、插入(put)
HBase 中行的每一个列都存储在不同的位置,插入数据时必须指定要存储在哪个单元格;而单元格需要根据表、行、列这几个维度来定位,因此插入数据的时候必须指定把数据插入到哪个表的哪个列族的哪个行的哪个列,例如:
hbase(main):024:0> put 'test1','row1','cf:name','jack'
Took 0.0838 seconds
hbase(main):025:0> scan 'test1'
ROW COLUMN+CELL
row1 column=cf:name, timestamp=1543161899520, value=jack
1 row(s)
Took 0.0301 seconds
向 test 表插入一个单元格,这个单元格的 rowkey 为 row1,该单元格的列族为 cf,该单元格的列名为 name,数据值为 jack。
插入成功后,使用 scan 命令查看表中数据,可以看到表中有一条记录,ROW 列显示的就是 rowkey,COLUMN+CELL 显示的就是这个记录的具体列族(column 里面冒号前面的 部分)、列(colum 里面冒号后面的部分)、时间戳(timestamp)、值(value)信息。
- 时间戳:每一个单元格都可以存储多个版本(version)的值,HBase 的单元格并没有 version 这个属性,它用 timestamp 来存储该条记录的时间戳,这个时间戳就用来当版本号使用;这个 timestamp 虽然说是时间的标定,其实你可以输入任意的数字,比如 1、2、3 都可以存储进去。
- 列族和列的标识:HBase 并没有专门的一个列族的栏来显示列族这个属性,它总是把列族和列用 “列族:列” 的组合方式来一起显示,无论是 put 存储还是 scan 的查询使用的列定义,都是 列族:列” 的格式。
2、获取单条数据(get)
get 只能查询一个单元格的记录,在表的数据很大的时候,get 查询的速度远远高于 scan。
get 'test','row7',{COLUMN=>'cf:name',VERSIONS=>5}
COLUMN CELL
cf:name timestamp=3, value=wangwu
cf:name timestamp=2, value=lisi
cf:name timestamp=1, value=zhangsan
3、查询多条数据(scan)
Scan 是最常用的查询表数据的命令,这个命令相当于传统数据库的 select。在 HBase 中我们用起始行(STARTROW)和结束行(ENDROW)来限制显示记录的条数。
STARTROW 和 ENDROW 都是可选的参数,可以不输入。如果 ENDROW 不输入的话,就从 STARTROW 开始一直显示下去直到表的结尾;如果 STARTROW 不输入的话,就从表头一直显示到 ENDROW 为止。
scan 'test',{STARTROW=>'row3'}
ROW COLUMN+CELL
row3 column=cf:name, timestamp=1471112677398, value=alex
row4 column=cf:name, timestamp=1471112686290, value=jim
scan 'test',{ENDROW=>'row4'}
ROW COLUMN+CELL
row2 column=cf:name, timestamp=2222222222222, value=billy
row3 column=cf:name, timestamp=1471112677398, value=alex
4、删除单元格数据(delete)
删除表数据可以使用 delete 命令:
# 删除某一单元格数据
delete 'test','row4','cf:name'
# 根据版本删除数据(删除这个版本之前的所有版本)
delete't1','r1','c1',ts
HBase 删除记录并不是真的删除了数据,而是放置了一个墓碑标记(tombstone marker),把这个版本连同之前的版本都标记为不可见了。这是为了性能着想,这样 HBase 就可以定期去清理这些已经被删除的记录,而不用每次都进行删除操作。
“定期” 的时间点是在 HBase 做自动合并(compaction,HBase整理存储文件时的一个操作,会把多个文件块合并成一个文件)的时候,这样删除操作对于 HBase 的性能影响被降到了最低,就算在很高的并发负载下大量删除记录也不怕了!
在记录被真正删除之前还是可以查询到的,只需要在 scan 命令后跟上
RAW=>true参数和适当的 VERSIONS 参数就可以看到被打上墓碑标记(tombstone marker)的记录,跟上 RAW 就是查询到表的所有未经过过滤的原始记录。
5、删除整行数据(deleteall)
如果一个行有很多列,用 delete 来删除记录会把人累死,可以 deleteall 命令来删除整行记录。
# 只需要明确到 rowkey 即可
deleteall 'test','row3'
三、获取帮助
HBase 还有很多表相关的操作,这里不一一列出,在 shell 控制台可以输入 help 命令获得帮助信息;如果希望查看某个命令的帮助信息,可以执行 help '指令'。
hbase(main):026:0> help
HBase Shell, version 2.0.0-cdh6.0.1, rUnknown, Wed Sep 19 09:14:00 PDT 2018
Type 'help "COMMAND"', (e.g. 'help "get"' -- the quotes are necessary) for help on a specific command.
Commands are grouped. Type 'help "COMMAND_GROUP"', (e.g. 'help "general"') for help on a command group.
Any Code,Code Any!
扫码关注『AnyCode』,编程路上,一起前行。

