

原文发表在:
holmeshe.me/network-ess…一般情况下,系统瓶颈由延时决定,而不是吞吐量。然而 TCP 套接字默认开启了所谓的"nagle算法",会延缓发包时间,以便和后面(需要发送)的网络包合并在一起发送。这个算法主要用于减少网络包的数量,从而减少TCP报文头的吞吐量开销。setsockopt, TCP_NODELAY and Packet Aggregation I一般情况下,系统瓶颈由延时决定,而不是吞吐量。然而 TCP 套接字默认开启了所谓的"nagle算法",会延缓发包时间,以便和后面(需要发送)的网络包合并在一起发送。这个算法主要用于减少网络包的数量,从而减少TCP报文头的吞吐量开销。
锁和阻塞操作历来都是后台编程的忌讳,所以我看到这个算法的第一反应是:人家千辛万苦就是要减少延时,这里为啥反而要增加延时呢?于是便决定详细了解一下。
软件环境
客户端操作系统:Debian 4.9.88
服务端操作系统(局域网和广域网):Ubuntu 16.04
gcc:6.3.0
硬件(虚拟机)环境
服务器(局域网):Intel® Core™2 Duo CPU E8400 @ 3.00GHz × 2, 4GB
服务器(广域网):t2.micro, 1GB
nagle算法对延时的影响
先打上码
客户端:
...include
int main(int argc, char *argv[]) {
int sfd, portno, n, delay;
struct sockaddr_in srvaddr;
struct hostent *host;
char buffer[256] = "abc";
if (argc < 3) { fprintf(stderr,"usage: %s ip port delay\n", argv[0]); exit(0); }
portno = atoi(argv[2]);
sfd = socket(AF_INET, SOCK_STREAM, 0);
if (sfd < 0) { perror("ERROR: socket()"); exit(0); }
//int flags =1;
//if (setsockopt(sfd, SOL_TCP, TCP_NODELAY, (void *)&flags, sizeof(flags))) { perror("ERROR: setsocketopt(), TCP_NODELAY"); exit(0); };
host = gethostbyname(argv[1]);
if (host == NULL) { fprintf(stderr,"ERROR: host does not exist"); exit(0); }
delay = atoi(argv[3]);
bzero((char *) &srvaddr, sizeof(srvaddr));
srvaddr.sin_family = AF_INET;
srvaddr.sin_port = htons(portno);
bcopy((char *)host->h_addr, (char *)&srvaddr.sin_addr.s_addr, host->h_length);
if (connect(sfd, (struct sockaddr *)&srvaddr, sizeof(srvaddr)) < 0) { perror("ERROR: connect()"); exit(0); }
for (int i = 0; i < 1000; i++) {
n = write(sfd, buffer, 4);
if (n < 0) { perror("ERROR: writing()"); exit(0); }
usleep(delay);
}
printf("finished\n");
return 0;
}
服务端:
...include
#define BUF_SIZE 256
int main(int argc, char *argv[])
{
int sfd, rfd, portno, clilen;
char buffer[BUF_SIZE];
struct sockaddr_in serv_addr, cli_addr;
int n;
if (argc < 2) { perror("ERROR: no port\n"); exit(1); }
sfd = socket(AF_INET, SOCK_STREAM, 0);
if (sfd < 0) { perror("ERROR: socket()"); exit(1); }
bzero((char *) &serv_addr, sizeof(serv_addr));
portno = atoi(argv[1]);
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = INADDR_ANY;
serv_addr.sin_port = htons(portno);
if (bind(sfd, (struct sockaddr *) &serv_addr, sizeof(serv_addr)) < 0) { perror("ERROR: bind()"); exit(1); }
listen(sfd, SOMAXCONN);
while (1) {
clilen = sizeof(cli_addr);
rfd = accept(sfd, (struct sockaddr *) &cli_addr, &clilen);
if (rfd < 0) { perror("ERROR: accept()"); exit(1); }
while (1) {
n = read(rfd, buffer, BUF_SIZE);
if (n <= 0) { printf("read() ends\n"); break; }
}
}
return 0;
}
简单解释一下。客户端会发送1000个4字节的网络包,每次发包的间隔由命令行参数决定。并且,如上所述,这段程序会使用TCP套接字的默认行为。服务器端则仅仅实现了 抛弃服务器,具体代码就不解释了。
测一下。接下来我会记录在不同的发包频率下的连包的数量,并在局域网(RTT < 0.6ms)和广域网(RTT ≈ 200ms)都做一遍。
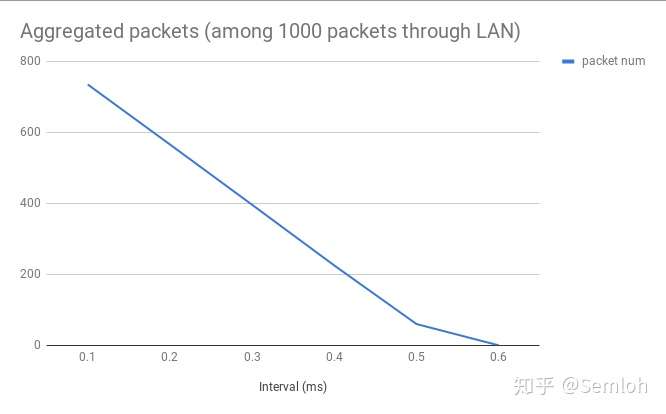
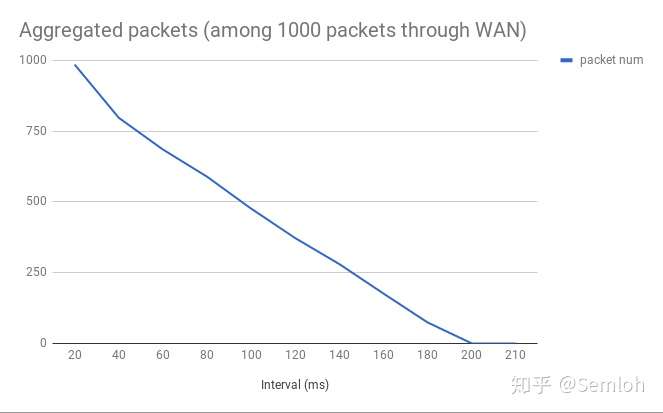
如图所示,连包的数量在发包间隔大于RTT时会趋近于0,这也符合<<TCP/IP Illustrated>>里所描述的:
This algorithm says that a TCP connection can have only one outstanding small segment that has not yet been acknowledged. No additional small segments can be sent until the acknowledgment is received.
直接查看 tcpdump 的输出,我们可以发现无论程序以何种频率调用write(2) ,nagle算法 都会把实际发包间隔设定为近似于 RTT,并将两次实际发包的所有网络包合并。
…
18:34:52.986972 IP debian.53700 > ******.compute.amazonaws.com.6666: Flags [P.], seq 4:12, ack 1, win 229, options [nop,nop,TS val 7541746 ecr 2617170332], length 8
18:34:53.178277 IP debian.53700 > ******.amazonaws.com.6666: Flags [P.], seq 12:20, ack 1, win 229, options [nop,nop,TS val 7541794 ecr 2617170379], length 8
18:34:53.369431 IP debian.53700 > ******.amazonaws.com.6666: Flags [P.], seq 20:32, ack 1, win 229, options [nop,nop,TS val 7541842 ecr 2617170427], length 12
18:34:53.560351 IP debian.53700 > ******.amazonaws.com.6666: Flags [P.], seq 32:40, ack 1, win 229, options [nop,nop,TS val 7541890 ecr 2617170475], length 8
18:34:54.325242 IP debian.53700 > ******.amazonaws.com.6666: Flags [P.], seq 68:80, ack 1, win 229, options [nop,nop,TS val 7542081 ecr 2617170666], length 12
…
平均下来,nagle算法 对每个网络包所增加的延时是 2 * RTT
ACK确认延迟
ACK确认延迟 则是另外一套相似的算法,这里我直接用<<TCP/IP Illustrated>>的描述:
TCP will delay an ACK up to 200 ms to see if there is data to send with the ACK.
TCP会延后(最多200毫秒)发送ACK,以便将后续可能出现的数据包和ACK一起发送。
解释一下。在某些情况,比如说后台接收到请求后并没有及时返回的数据,ACK确认延迟 会等待另外一组请求,而这组请求却在 nagle算法 下等待上一波请求的ACK。于是,这两套算法成功的构成了死锁。
由于在我的环境下无法用
flags = 0;
flglen = sizeof(flags);
getsockopt(sfd, SOL_TCP, TCP_QUICKACK, &flags, &flglen)
开启 ACK确认延时,这个短暂死锁的实际效果就没测了。
写在最后
在我写这篇文章时,除了(过时的) telnet ,大部分的应用,包括前端的 (Firefox,Chromium),后端的 (nginx,memcached),以及 telnet 的继任 ssh,都用类似以下的代码禁用了 nagle算法,
int flags =1;
setsockopt(sfd, SOL_TCP, TCP_NODELAY, (void *)&flags, sizeof(flags));
说直白点,就是不要阻塞,不要阻塞,不要阻塞。
…
18:22:38.983278 IP debian.43808 > 192.168.1.71.6666: Flags [P.], seq 1:5, ack 1, win 229, options [nop,nop,TS val 7358245 ecr 6906652], length 4
18:22:38.984149 IP debian.43808 > 192.168.1.71.6666: Flags [P.], seq 5:9, ack 1, win 229, options [nop,nop,TS val 7358246 ecr 6906652], length 4
18:22:38.985028 IP debian.43808 > 192.168.1.71.6666: Flags [P.], seq 9:13, ack 1, win 229, options [nop,nop,TS val 7358246 ecr 6906653], length 4
18:22:38.985897 IP debian.43808 > 192.168.1.71.6666: Flags [P.], seq 13:17, ack 1, win 229, options [nop,nop,TS val 7358246 ecr 6906653], length 4
18:22:38.986765 IP debian.43808 > 192.168.1.71.6666: Flags [P.], seq 17:21, ack 1, win 229, options [nop,nop,TS val 7358246 ecr 6906653], length 4
…
个人认为大家都用 TCP_NODELAY 的原因如下:
1) 带宽的增加,所以 nagle算法 越来越变成一个“过度优化” - 如果要让现代的某一条通路饱和,需要上十万条小包体,而
2)发送这么多小包体的应用,一般都对实时性(低延时)有很高的要求。
毕竟,玩惯了撸啊撸,80年代的回合(这里是200ms一个回合)制RPG还是有点过时了。
