

一般,深度学习的教材或者是视频,作者都会通过 MNIST 这个数据集,讲解深度学习的效果,但这个数据集太小了,而且是单色图片,随便弄些模型就可以取得比较好的结果,但如果我们不满足于此,想要训练一个神经网络来对彩色图像进行分类,可以不可以呢?
当然可以的,但是没有想象的容易。
我最开始亲自设置神经网络去训练时,训练准确度还不到 30%,并且不能收敛。后来逐步运用自己对于深度学习的理解去不断调整网络的结构,同时采用有效的优化手段,让自己的模型可以攀升到 50%,然后又提高到 70%,最后达到训练时 99% 的准确度,测试时达到 85% 的准确度,所以这个模型也见证了我自己深度学习过程的能力成长。也是我分享这篇文章的用意。
那么,神经网络的训练一般要进行哪些步骤呢?
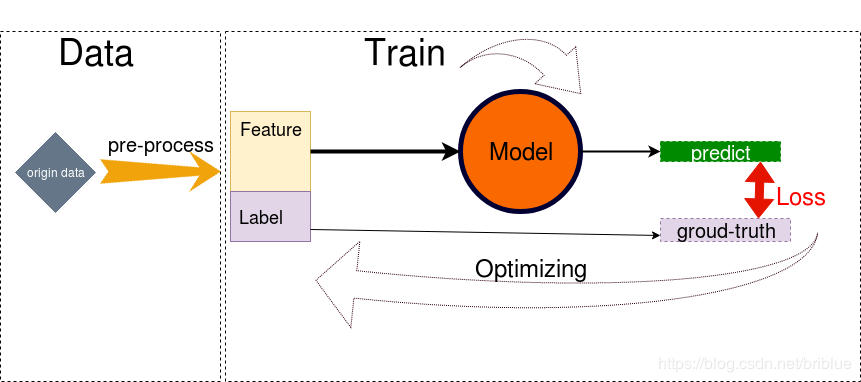
上图说明了一般有监督学习的训练过程。
- 加载数据集,并做预处理。
- 预处理后的数据分为 feature 和 label 两部分,feature 送到模型里面,label 被当做 ground-truth。
- model 接收 feature 作为 input,并通过一系列运算,向外输出 predict。
- 通过以 predict 和 predict 为变量,建立一个损失函数 Loss,Loss 的函数值是为了表示 predict 与 ground-truth 之间的差距。
- 建立 Optimizer 优化器,优化的目标就是 Loss 函数,让它的取值尽可能最小,loss 越小代表 Model 预测的准确率越高。
- Optimizer 优化过程中,Model 根据规则改变自身参数的权重,这是个反复循环和持续的过程,直到 loss 值趋于稳定,不能在取得更小值。
注意:本篇文章,用 PyTorch 进行开发,其实其它深度学习框架如 TensorFlow 也能轻易实现。
由于是基于 PyTorch 代码说明,所以我假定读者对于 PyTorch 这个深度学习框架具备基本的了解。
1.加载数据集
数据集的加载,我们可以自行编写代码,但如果是基于学习的目的的话,那么把经历放在编写这个步骤的代码上面会让人十分崩溃与无聊。
好在,pytorch 提供了非常方便的包 torchvision.
torchvison 提供了 dataloader 去加载常见的 MNIST、CIFAR-10、ImageNet 等数据集,也提供了 transform 去对图像进行变换、正则化和可视化。
核心包:torchvision.datasets、torch.utils.data.DataLoader
在本文中,我们的目的是用 pytorch 创建基于 CIFAR-10 数据集的图像分类器。

CIFAR-10 有 50000 张训练图片,10000 张测试图片,总共 10 个类别,分别是 ‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’ CIFAR-10 图片的尺寸是 32x32x3,所以它是比较小的彩色图片。
如何加载呢?
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import torch.optim as optim
import time
import os
transform = transforms.Compose(
[
transforms.RandomHorizontalFlip(),
transforms.RandomGrayscale(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
transform1 = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=100,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform1)
testloader = torch.utils.data.DataLoader(testset, batch_size=50,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
transform 在上面的代码的作用主要是用来对数据进行预处理。
transforms.RandomHorizontalFlip(),
transforms.RandomGrayscale(),
这两句代码主要是用来做数据增强的,为了防止训练出现过拟合,通常在小型数据集上,通过随机翻转图片,随机调整图片的亮度,来达到增加训练时数据集的容量。
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
数据集加载时,默认的图片格式是 numpy,所以通过 transforms 转换成 Tensor。 然后,再对输入图片进行标准化。
但是,测试的时候,并不需要对数据进行增强,所以它们的转换还是有点不同。
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
torchvision.datasets.CIFAR10 就指定了 CIFAR-10 这个数据集,这个模块定义了它如何去下载数据集,及如何从本地加载现成的数据。
root 指定了数据集存放的位置,train 指定是否是训练数据集。
trainloader = torch.utils.data.DataLoader(trainset, batch_size=100,
shuffle=True, num_workers=2)
数据集需要配合 DataLoader 使用,DataLoader 从数据集中不断提取数据然后送往 Model 进行训练和预测。
在这里,指定了 batch size 为 100,也就是 mini-batch 单批次图片的数量为 100.
shuffle = True 表明提取数据时,随机打乱顺序,因为我们都是基于随机梯度下降的方式进行训练优化,但测试的时候因为不需要更新参数,所以就无须打乱顺序了。
num_workers = 2 指定了工作线程的数量。
运行代码后,会自动下载数据集,并存放在当前目录下的 data 文件中。
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz
Files already downloaded and verified
2. 定义神经网络
我们可以再看看文章开始的那张图,Model 是核心部分,而神经网络就是一个 Model。
而在本篇博文中,我创建的神经网络层次还比较深,是 VGG 的翻版,目的是想让测试的准确率更加高一点。但我没有完全参照 VGG-16,因为我的 GPU 是 GTX1080i,当时在 Tensorflow 上实验时爆出了内存不够的问题,所以我在 VGG-16 的基础上减少了卷积核的数量。
VGG 的最大特征是大量采用 3x3 尺寸的卷积核,更详细的信息可以参考我的博文。【深度学习】经典神经网络 VGG 论文解读
| input (32x32x3) color image |
|---|
| Conv1 3x3,64 |
| Conv2 3x3,64 |
| Maxpool 2x2,strides=2 |
| Batch Normalization |
| Relu |
| – |
| Conv3 3x3,128 |
| Conv4 3x3,128 |
| Maxpool 2x2,strides=2 |
| Batch Normalization |
| Relu |
| – |
| Conv5 3x3,128 |
| Conv6 3x3,128 |
| Conv7 1x1,128 |
| Maxpool 2x2,strides=2 |
| Batch Normalization |
| Relu |
| – |
| Conv8 3x3,256 |
| Conv9 3x3,256 |
| Conv10 1x1,256 |
| Maxpool 2x2,strides=2 |
| Batch Normalization |
| Relu |
| – |
| Conv11 3x3,512 |
| Conv12 3x3,512 |
| Conv13 1x1,512 |
| Maxpool 2x2,strides=2 |
| Batch Normalization |
| Relu |
| – |
| FC14 (8192,1024) |
| Dropout |
| Relu |
| FC15 (1024,1024) |
| Dropout |
| Relu |
| FC16 (1024,10) |
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(3,64,3,padding=1)
self.conv2 = nn.Conv2d(64,64,3,padding=1)
self.pool1 = nn.MaxPool2d(2, 2)
self.bn1 = nn.BatchNorm2d(64)
self.relu1 = nn.ReLU()
self.conv3 = nn.Conv2d(64,128,3,padding=1)
self.conv4 = nn.Conv2d(128, 128, 3,padding=1)
self.pool2 = nn.MaxPool2d(2, 2, padding=1)
self.bn2 = nn.BatchNorm2d(128)
self.relu2 = nn.ReLU()
self.conv5 = nn.Conv2d(128,128, 3,padding=1)
self.conv6 = nn.Conv2d(128, 128, 3,padding=1)
self.conv7 = nn.Conv2d(128, 128, 1,padding=1)
self.pool3 = nn.MaxPool2d(2, 2, padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.relu3 = nn.ReLU()
self.conv8 = nn.Conv2d(128, 256, 3,padding=1)
self.conv9 = nn.Conv2d(256, 256, 3, padding=1)
self.conv10 = nn.Conv2d(256, 256, 1, padding=1)
self.pool4 = nn.MaxPool2d(2, 2, padding=1)
self.bn4 = nn.BatchNorm2d(256)
self.relu4 = nn.ReLU()
self.conv11 = nn.Conv2d(256, 512, 3, padding=1)
self.conv12 = nn.Conv2d(512, 512, 3, padding=1)
self.conv13 = nn.Conv2d(512, 512, 1, padding=1)
self.pool5 = nn.MaxPool2d(2, 2, padding=1)
self.bn5 = nn.BatchNorm2d(512)
self.relu5 = nn.ReLU()
self.fc14 = nn.Linear(512*4*4,1024)
self.drop1 = nn.Dropout2d()
self.fc15 = nn.Linear(1024,1024)
self.drop2 = nn.Dropout2d()
self.fc16 = nn.Linear(1024,10)
def forward(self,x):
x = self.conv1(x)
x = self.conv2(x)
x = self.pool1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.pool2(x)
x = self.bn2(x)
x = self.relu2(x)
x = self.conv5(x)
x = self.conv6(x)
x = self.conv7(x)
x = self.pool3(x)
x = self.bn3(x)
x = self.relu3(x)
x = self.conv8(x)
x = self.conv9(x)
x = self.conv10(x)
x = self.pool4(x)
x = self.bn4(x)
x = self.relu4(x)
x = self.conv11(x)
x = self.conv12(x)
x = self.conv13(x)
x = self.pool5(x)
x = self.bn5(x)
x = self.relu5(x)
# print(" x shape ",x.size())
x = x.view(-1,512*4*4)
x = F.relu(self.fc14(x))
x = self.drop1(x)
x = F.relu(self.fc15(x))
x = self.drop2(x)
x = self.fc16(x)
return x
在 PyTorch 中可以通过继承 nn.Module 来自定义神经网络,在 init() 中设定结构,在 forward() 中设定前向传播的流程。 因为 PyTorch 可以自动计算梯度,所以不需要特别定义 backward 反向传播。
值得注意的是,我有采用 Batch Normalization 去加速神经网络的训练,更多细节也可以参考我这篇博文。【深度学习】Batch Normalizaton 的作用及理论基础详解
另外,forward 最后没有对 output 进行 softmax 操作,所以它只是 inference,在训练阶段,Loss 会定义这个操作,而如果是测试或者是预测的话,就不需要 softmax 操作。
3. 定义 Loss 函数和优化器
按照文章最前面的流程图,定义好神经网络模型后,就需要定义损失函数 Loss 和优化器 Optimizer。
在这里采用 cross-entropy-loss 函数作为 loss 函数,采用 Adam 作为 Optimizer,当然 SGD 也可以。
loss = nn.CrossEntropyLoss()
#optimizer = optim.SGD(self.parameters(),lr=0.01)
optimizer = optim.Adam(self.parameters(), lr=0.0001)
需要注意的是,nn.CrossEntropyLoss() 包含了 logsoftmax 和 loss 两个操作。
4.训练
定义 Loss 和优化器就可以开始训练了,训练的手段就是通过 Optimizer 尽量让 loss 的值变得更小,从而神经网络的预测变得越来越高。
for epoch in range(100): # loop over the dataset multiple times
timestart = time.time()
running_loss = 0.0
total = 0
correct = 0
for i, data in enumerate(trainloader, 0):
# get the inputs
inputs, labels = data
inputs, labels = inputs.to(device),labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = self(inputs)
l = loss(outputs, labels)
l.backward()
optimizer.step()
# print statistics
running_loss += l.item()
# print("i ",i)
if i % 500 == 499: # print every 500 mini-batches
print('[%d, %5d] loss: %.4f' %
(epoch, i, running_loss / 500))
running_loss = 0.0
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the %d tran images: %.3f %%' % (total,
100.0 * correct / total))
total = 0
correct = 0
print('epoch %d cost %3f sec' %(epoch,time.time()-timestart))
print('Finished Training')
程序设定训练过程要经过 100 个 epoch,然后结束。
也许有同学还不清楚 epoch 和 iteration 的区别,iteration 指的是单次 mini-batch 训练,而 epoch 和数据集的大小还有 batch size 有关。
CIFAR-10 训练集图片数量是 50000,batch size 的大小是 100,所以要经过 500 次 iteration 才算走完一个 epoch。
epoch 可以大致当成神经网络把训练集所有的照片从头看到尾都过了一遍。
inputs, labels = data
inputs, labels = inputs.to(device),labels.to(device)
PyTorch 可以指定设备,比如 GPU 或者是 CPU,上面的代码其实就是这个操作,当然默认是 CPU。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
上面的代码指定了 device 类型。
optimizer.zero_grad()
# forward + backward + optimize
outputs = self(inputs)
l = loss(outputs, labels)
l.backward()
optimizer.step()
上面几句代码是,训练的核心部分。
分别是前向传播+后向传播+优化,按照 PyTorch 的官方示例,就这样写。
running_loss += l.item()
# print("i ",i)
if i % 500 == 499: # print every 500 mini-batches
print('[%d, %5d] loss: %.4f' %
(epoch, i, running_loss / 500))
running_loss = 0.0
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the %d tran images: %.3f %%' % (total,
100.0 * correct / total))
total = 0
correct = 0
刚刚有讲到,在本文中,500 次 iteration 达成了 1 次 epoch,训练时希望检测训练时的效果,所以每 1 次 epoch,打印一下 loss 值和准确度。 准确度就是本次 epoch 中预测准确的数量占总共样本的百分比。
4.1 保存和恢复训练模型
可能有些同学的电脑没有可用的 GPU,或者是 GPU 的版本比较低,那么训练的时间会很长,所以能够随时保存和恢复训练模型就显得非常重要了。
PyTorch 当然也支持了这样的功能。
torch.save({'epoch':epoch,
'model_state_dict':net.state_dict(),
'optimizer_state_dict':optimizer.state_dict(),
'loss':loss
},path)
torch.save() 可以保存训练时的 epoch、state_dict、loss。
state_dict 是什么呢?是能够被学习的参数字典。 需要注意的是网络的 state_dict 和 optimizer 的 state_dict 都可以保存。
path 指定了模型的保存路径。
所以我们可以根据实际情况在必要的时刻保存训练进度和状态。
path = 'weights.tar'
checkpoint = torch.load(path)
self.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
initepoch = checkpoint['epoch']
loss = checkpoint['loss']
通过 torch.load() 加载 checkpoint
然后通过 net 和 optimizer 的 load_state_dict() 方法来恢复参数。
同时之前的 epoch 值和 loss 都可以恢复。
这样,具有保存和恢复模型功能的训练函数完整代码如下:
def train_sgd(self,device):
optimizer = optim.Adam(self.parameters(), lr=0.0001)
path = 'weights.tar'
initepoch = 0
if os.path.exists(path) is not True:
loss = nn.CrossEntropyLoss()
# optimizer = optim.SGD(self.parameters(),lr=0.01)
else:
checkpoint = torch.load(path)
self.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
initepoch = checkpoint['epoch']
loss = checkpoint['loss']
for epoch in range(initepoch,100): # loop over the dataset multiple times
timestart = time.time()
running_loss = 0.0
total = 0
correct = 0
for i, data in enumerate(trainloader, 0):
# get the inputs
inputs, labels = data
inputs, labels = inputs.to(device),labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = self(inputs)
l = loss(outputs, labels)
l.backward()
optimizer.step()
# print statistics
running_loss += l.item()
# print("i ",i)
if i % 500 == 499: # print every 500 mini-batches
print('[%d, %5d] loss: %.4f' %
(epoch, i, running_loss / 500))
running_loss = 0.0
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the %d tran images: %.3f %%' % (total,
100.0 * correct / total))
total = 0
correct = 0
torch.save({'epoch':epoch,
'model_state_dict':net.state_dict(),
'optimizer_state_dict':optimizer.state_dict(),
'loss':loss
},path)
print('epoch %d cost %3f sec' %(epoch,time.time()-timestart))
print('Finished Training')
5. 测试
训练神经网络的目的是为了做预测,但为了检验这个模型的能力,所以在训练完成后需要进行测试。
测试图片和训练图片不在同一堆数据当中。
测试时,模型的参数固定,并不需要计算梯度。 然后主要进行评估,评估模型预测的结构和 ground-truth 之间的百分比。
def test(self,device):
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = self(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %.3f %%' % (
100.0 * correct / total))
最后,我们观察最终的结果。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = Net()
net = net.to(device)
net.train_sgd(device)
net.test(device)
创建了 Net 对象,然后先训练,训练完成后再进行测试。
Files already downloaded and verified
Files already downloaded and verified
[99, 499] loss: 0.0383
Accuracy of the network on the 100 tran images: 99.000 %
epoch 99 cost 15.083664 sec
Finished Training
Accuracy of the network on the 10000 test images: 85.050 %
我跑一个 epoch 大概花费 15 秒多,最终这个神经网络的测试准确度达到了 85%。 目前已知的 CIFAR-10 最好的成绩是 96.53,按照我这显示的 85% 算的话,大概能排到 37 名吧。
本文涉及的完整代码如下
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import torch.optim as optim
import time
import os
transform = transforms.Compose(
[
transforms.RandomHorizontalFlip(),
transforms.RandomGrayscale(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
transform1 = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=100,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform1)
testloader = torch.utils.data.DataLoader(testset, batch_size=50,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(3,64,3,padding=1)
self.conv2 = nn.Conv2d(64,64,3,padding=1)
self.pool1 = nn.MaxPool2d(2, 2)
self.bn1 = nn.BatchNorm2d(64)
self.relu1 = nn.ReLU()
self.conv3 = nn.Conv2d(64,128,3,padding=1)
self.conv4 = nn.Conv2d(128, 128, 3,padding=1)
self.pool2 = nn.MaxPool2d(2, 2, padding=1)
self.bn2 = nn.BatchNorm2d(128)
self.relu2 = nn.ReLU()
self.conv5 = nn.Conv2d(128,128, 3,padding=1)
self.conv6 = nn.Conv2d(128, 128, 3,padding=1)
self.conv7 = nn.Conv2d(128, 128, 1,padding=1)
self.pool3 = nn.MaxPool2d(2, 2, padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.relu3 = nn.ReLU()
self.conv8 = nn.Conv2d(128, 256, 3,padding=1)
self.conv9 = nn.Conv2d(256, 256, 3, padding=1)
self.conv10 = nn.Conv2d(256, 256, 1, padding=1)
self.pool4 = nn.MaxPool2d(2, 2, padding=1)
self.bn4 = nn.BatchNorm2d(256)
self.relu4 = nn.ReLU()
self.conv11 = nn.Conv2d(256, 512, 3, padding=1)
self.conv12 = nn.Conv2d(512, 512, 3, padding=1)
self.conv13 = nn.Conv2d(512, 512, 1, padding=1)
self.pool5 = nn.MaxPool2d(2, 2, padding=1)
self.bn5 = nn.BatchNorm2d(512)
self.relu5 = nn.ReLU()
self.fc14 = nn.Linear(512*4*4,1024)
self.drop1 = nn.Dropout2d()
self.fc15 = nn.Linear(1024,1024)
self.drop2 = nn.Dropout2d()
self.fc16 = nn.Linear(1024,10)
def forward(self,x):
x = self.conv1(x)
x = self.conv2(x)
x = self.pool1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.pool2(x)
x = self.bn2(x)
x = self.relu2(x)
x = self.conv5(x)
x = self.conv6(x)
x = self.conv7(x)
x = self.pool3(x)
x = self.bn3(x)
x = self.relu3(x)
x = self.conv8(x)
x = self.conv9(x)
x = self.conv10(x)
x = self.pool4(x)
x = self.bn4(x)
x = self.relu4(x)
x = self.conv11(x)
x = self.conv12(x)
x = self.conv13(x)
x = self.pool5(x)
x = self.bn5(x)
x = self.relu5(x)
# print(" x shape ",x.size())
x = x.view(-1,512*4*4)
x = F.relu(self.fc14(x))
x = self.drop1(x)
x = F.relu(self.fc15(x))
x = self.drop2(x)
x = self.fc16(x)
return x
def train_sgd(self,device):
optimizer = optim.Adam(self.parameters(), lr=0.0001)
path = 'weights.tar'
initepoch = 0
if os.path.exists(path) is not True:
loss = nn.CrossEntropyLoss()
# optimizer = optim.SGD(self.parameters(),lr=0.01)
else:
checkpoint = torch.load(path)
self.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
initepoch = checkpoint['epoch']
loss = checkpoint['loss']
for epoch in range(initepoch,100): # loop over the dataset multiple times
timestart = time.time()
running_loss = 0.0
total = 0
correct = 0
for i, data in enumerate(trainloader, 0):
# get the inputs
inputs, labels = data
inputs, labels = inputs.to(device),labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = self(inputs)
l = loss(outputs, labels)
l.backward()
optimizer.step()
# print statistics
running_loss += l.item()
# print("i ",i)
if i % 500 == 499: # print every 500 mini-batches
print('[%d, %5d] loss: %.4f' %
(epoch, i, running_loss / 500))
running_loss = 0.0
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the %d tran images: %.3f %%' % (total,
100.0 * correct / total))
total = 0
correct = 0
torch.save({'epoch':epoch,
'model_state_dict':net.state_dict(),
'optimizer_state_dict':optimizer.state_dict(),
'loss':loss
},path)
print('epoch %d cost %3f sec' %(epoch,time.time()-timestart))
print('Finished Training')
def test(self,device):
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = self(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %.3f %%' % (
100.0 * correct / total))
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = Net()
net = net.to(device)
net.train_sgd(device)
net.test(device)
上面的代码,亲自试验可运行。
待优化的地方
1. 神经网络的层数和卷积核的数量
可能有的同学的 GPU 比我的要好,那么可以尝试一下加深层级,或者是增大每一层卷积核的数量。
GPU 不怎么好或者没有 GPU 的同学可以尝试减低神经网络的层数还有每一层卷积核的数量,不然训练可能会花费一定的时间。
2. 调整神经网络的架构
我这个神经网络是参考 VGG-16 改良的,有兴趣的同学可以参考 Inception-V3 或者是 ResNet 来改造,也学准确度会更高。
3. 可视化训练结果
Tensorflow 中有 TensorBoard 这个可视化的工具,PyTorch 可以通过 Visdom 配合达到可视化的目的。
希望各位亲自实践一下,然后把测试准确度再提高。
