

内容来源:本文内容由阿里大数据计算服务(MaxCompute)团队投稿提供。IT 大咖说经授权发布,转载请标明出处。
阅读字数:5502 | 14分钟阅读
摘要
目前hash clustering table已经在阿里巴巴内部集群生产环境正式发布,并且已经有蚂蚁、安全部、菜鸟等多个BU参与了试用。从蚂蚁的反馈来看,改造之后的任务收效非常明显,运行时间缩短40%到80%,节省计算资源23%到67%。
对于增量更新的场景,可以利用 MaxCompute2.0的新特性,对语句做简单改造,从而大幅提升性能,节约集群资源。

背景介绍
在数据开发的过程中,往往会进行分层的设计,在ODS层中,一种非常常见的场景是使用一个增量表delta对一个存量表snapshot进行更新。例如snapshot表存储所有的会员信息,而增量表中包括新增会员信息和原有会员信息属性的一些修改;或者snapshot表存储最近一个月的订单信息,delta表存储了新增订单以及物流的更新等等。
对于这种任务,往往有以下几个特征:
snapshot表存储量巨大,delta表相对较小
snapshot表和delta表拥有一致的schema
snapshot和delta表中存在主键key,且key可能有重合(否则可以通过简单的union all来完成)
上一个周期的snapshot + 当前周期的delta => 当前周期的snapshot
为了完成上述的功能,对应的sql逻辑一般使用full outer join,简单起见,我们的snapshot和delta表只有两列
(key string, value string)其中key为主键
INSERT OVERWRITE TABLE snapshot PARTITION (ds='20170102')
SELECT
CASE WHEN d.key IS NULL THEN s.key ELSE d.key END,
CASE WHEN d.key IS NULL THEN s.value ELSE d.value END
FROM
(SELECT * FROM snapshot WHERE ds='20170101') s
FULL OUTER JOIN
(SELECT * FROM delta WHERE ds = '20170102')d
ON s.key = d.key;这个语句表示,对于delta表存在的数据,使用delta表的值,对于delta表不存在的数据,使用snapshot的值。
问题
但是在实际执行的过程中,虽然只是进行简单的join操作,但是由于存量表可能非常大(几T到几十T的规模),这种任务往往耗时非常长,有些任务甚至需要耗费一天的时间才能产出。这种任务是否存在优化的空间呢?我们可以分析一个线上实际的大表full outer join的执行计划。
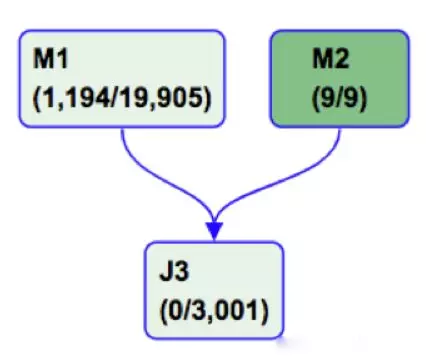
可以看到M1是snapshot表,需要将近20000的并发,M2是delta表,只有9个并发,而为了进行join的操作,两边会各自进行shuffle,在J3阶段进行sort-merge-join的计算。实际执行过程中,M2只需要几分钟,M1需要十几分钟,而在J3阶段则往往需要一两个小时,因为J3只有3000个并发,但是却读取了上游将近20000个并发读取的数据,相当于并发减小到原来的15%,处理的数据量却是一样的,当然耗时会长。另外,从M1到J3这个路径的shuffle中间存在大表的一次读写+两次排序,而且在数据量较大的情况下,还有可能会发生数据spill,使得运行性能更差。
在这种情况下,为了缩短执行时间,通常可以调大join阶段的instance数目,增加join阶段的内存减少spill等,但是instance的数目不能无限增长,否则会由于shuffle规模太大造成集群压力过大,另外内存的资源也是有限的,所以调整参数也只是牺牲资源换取时间,治标不治本。
为了对这个场景进行彻底的优化,我们希望能完全消除掉大表的shuffle阶段,将M1和J3合二为一,这样大表数据只需要读写一次,而且免去了中间排序的过程,执行时间可以缩短一半甚至更多。有调优经验的同学可能已经想到了mapjoin,但是这里的delta表往往数据较多无法当做mapjoin的小表,另外mapjoin无法支持full outer join,这两个限制都无法绕过,所以这个方案只能被pass了。那么这个shuffle的阶段应该如何省去呢?这里就要引入我们今天介绍的功能,hash clustering table了。
方案
Hash clustering,简而言之,就是将数据提前进行shuffle和排序,在使用数据的过程中,读取数据后直接参与计算。这种模式非常适合产出后后续节点多次按照相同key进行join或者聚合的场景。当然生成hash clustering table本身也是有代价的,在生成阶段会进行一次额外的shuffle。因此,这个功能并不是对于所有的场景都有效,例如数据生成之后只使用了一次,那么这个shuffle在生成表的阶段进行还是在读表之后进行其实并没有什么区别。但是对于特定的场景,这个特性可以起到显著的效果。
根据这个方案,我们重建一下snapshot表
ALTER TABLE snapshot CLUSTERED BY (key) SORTED BY (key) INTO 100 BUCKETS;注意这个100 bucket需要根据实际数据规模进行设置,这里只是示例,不要照抄^_^
然后重建一下ds='20170101'的数据
INSERT OVERWRITE TABLE snapshot PARTITION (ds='20170101')
SELECT key, value
FROM snapshot
WHERE ds='20170101'注意,这个过程由于会有一个额外的shuffle阶段,所以耗时会比普通的insert overwrite长。
第一次尝试: full outer join
数据准备完成后,重新执行刚才的full outer join语句
INSERT OVERWRITE TABLE snapshot PARTITION (ds='20170102')
SELECT
CASE WHEN d.key IS NULL THEN s.key ELSE d.key END,
CASE WHEN d.key IS NULL THEN s.value ELSE d.value END
FROM
(SELECT * FROM snapshot WHERE ds='20170101') s
FULL OUTER JOIN
(SELECT * FROM delta WHERE ds = '20170102')d
ON s.key = d.key;让我们看下执行计划
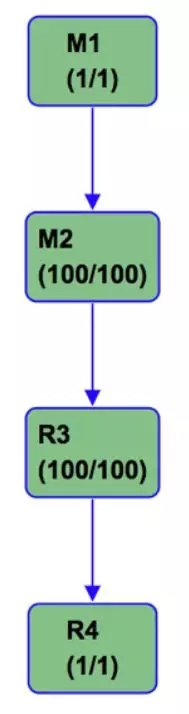
结果好像不尽如人意,M1读取了delta表,M2读取了snapshot表并且进行了sort-merge-join操作,但是读取完成以后数据重新进行了一次shuffle才写入了ds='20170102'分区,为什么会这样呢?
原因是ds='20170102'这个分区也是一个hash clustering table的分区,在写入的过程中,也需要数据按照特定key进行shuffle,虽然ds='20170101'的数据是shuffle过了的,但是在后续的full outer join的过程中,可能会存在补null的行为,并不能保证输出数据依然符合shuffle的特征,所以需要进行一次reshuffle。
其实,这个sql通过CASE WHEN d.id IS NULL THEN s.id ELSE d.id END在语义上实际是保证了不会出现额外补null的行为的,但是这个行为目前我们的优化器还不能识别,所以这种情况下大表数据依然会有一次shuffle,这并不能让我们满意。
第二次尝试: not in + union all
下一个问题是如何才能让优化器识别出来我们其实并没有改变shuffle的属性呢,我们观察到这个full outer join其实这个sql就是一个求并集的过程
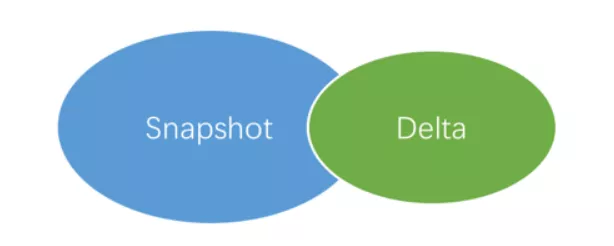
那么整个这个sql可以被拆分为两部分
SELECT a.key, a.value
FROM (SELECT * FROM snapshot WHERE ds='20170101' AND KEY NOT IN
(SELECT key FROM delta WHERE ds='20170102')) a -- snapshot_not_in_delta
UNION ALL
SELECT key, value FROM delta WHERE ds='20170102' -- delta_all在上述两部分中,前一部分对应图中的蓝色部分,后一部分对应图中的绿色部分。我们仅仅是对snapshot的key列进行了过滤操作,并没有改变key的分布,所以这个语句可以省去一次额外的shuffle。但是MaxCompute对于not in有一个限制是结果集合不能超过2000条,这个又限制了这种写法的应用场景。
最终方案: anti semi join + union all
好在MaxCompute2.0中新支持的anti semi join同样实现了not in的语义,而且对结果集大小并没有限制,使用anti semi join 这个语句可以进一步修改为
INSERT OVERWRITE TABLE snapshot PARTITION (ds='20170102')
SELECT s.key, s.value
FROM (SELECT * FROM snapshot WHERE ds='20170101') s
LEFT ANTI JOIN
(SELECT * FROM delta WHERE ds='20170102') d ON s.key = d.key
UNION ALL
SELECT key, value
FROM delta
WHERE ds='20170102';经过这一步的改造后,让我们运行一下,看看发生了什么。
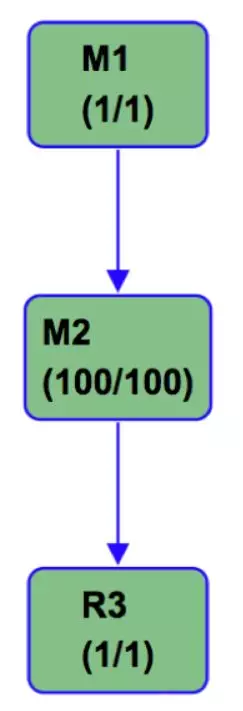
只有三个阶段,M1读取delta表,M2读取snapshot表并进行sort-merge-join,随后写出数据,最后一个R3阶段仅仅是一个收集信息的任务,耗时在秒级别,所以实际的处理阶段只有两个stage,其中M1合并了之前M1和J3的功能,由于省去了一次数据读写、排序以及可能的spill等操作,实际运行时间往往可以减半。
上面也说过,如果数据只是进行一次读写,其实hash clustering table的作用有限,但是在增量更新这个特定的场景下,我们的输入和输出都为hash clustering的数据,而且中间过程并没有对cluster key进行修改,只是进行了过滤,所以我们可以只在一个阶段中完成read->join->union all->write这四个操作,极大地缩短了运行时间。
收效
目前hash clustering table已经在阿里巴巴内部集群生产环境正式发布,并且已经有蚂蚁、安全部、菜鸟等多个BU参与了试用。
从蚂蚁的反馈来看,改造之后的任务收效非常明显,运行时间缩短40%到80%,节省计算资源23%到67%。
菜鸟在使用hash clustering之后,任务的执行计划有所变化,节省了之前join操作需要的shuffle等操作,任务执行时间从40分钟左右降低到20分钟以内,有效的提升了任务执行效率,缩短执行时间,节约了资源。
飞猪应用Hash Clustering后,对于计算,整个计算过程由优化前的3小时,缩短到40分钟内完成,对于明细事实表视图一次读取计算可在1分钟内完成;对于存储,节省的存储和数据膨胀程度是线性关系,采用视图形式,我们用非常小的计算消耗代价节省了80%的存储,这一点看来,是很值得的。
所以我们付出的代价,仅仅是将表的属性进行修改,并且提前进行一次数据生成操作,这个操作也只需要执行一次,一劳永逸。
最后,欢迎大家在自己的增量更新的任务使用hash clustering功能,从现有的经验来看,大表的数据越多,收益越明显。
一些需要注意的地方
bucket的数目设置需要一些经验,bucket越多,并发越多,运行越快,但是如果文件本身不大,小文件也越多,目前推荐500MB~1GB设置一个bucket,超大规模数据情况下一个bucket的数据可以更多。在任何情况下,不建议设置bucket number超过4096。
hash clustering table会对数据进行重排,在一些极端场景下,可能会导致原来压缩率较高的文件压缩率降低,影响后续的性能,这个可以通过观察生成表的summary的input/output bytes来确认
目前我们正在对decimal类型进行重构,重构之后可能会影响decimal类型的分布方式,所以clustered key不要选用decimal类型
snapshot表和delta表的schema不需要完全一致,但是如果key的类型不同,比如一边是bigint,一边是string,在join的时候需要将delta表的类型转换为snapshot的key类型,否则依然会需要一次reshuffle。
以上为今天的分享内容,谢谢大家!
