

阿里技术团队有一篇文章,是讲淘宝双十一背后的支持系统的:一天造出10亿个淘宝首页,阿里工程师如何实现?。我对里面提到的深度召回框架还挺感兴趣的,试图从中解析一下看看。
从Graph Embedding开始
阿里的这个深度召回系统来源于《DeepWalk: Online Learning of Social Representations》。我们今天先来看看这篇文章讲了什么。
DeepWalk本身是一个学习网络中顶点的embedding表达的图算法。它使用语言模型的方法来学习社交网络中的顶点的隐藏表达,并获得了很好的效果。总之,DeepWalk输入是一个网络,输出是各个顶点的latent表达。
Problem Formulation
首先定义一些符号:是一个有向带权图,V和E分别表示顶点和边集。
是一个部分有标签的社交网络图,其中
,
是特征空间的维度。
,
是label集。在一般的分类算法中,我们试图寻找一个map将
的特征映射到
。而在这篇文章中,我们使用无监督方法来学习网络结构。
我们的目标是学习一个,d是隐向量维度并且很小。这个d维向量代表了网络结构特征。这个表达应该有如下特性:
- Adaptability:新的item加入时不需要全部重新训练
- Community aware:两个embedding之间距离的远近应该能用于衡量原始item之间的相似度
- 低维度
- Continuous:在连续空间内取值
Random walk
随机游走是常见的采样方法,本文中将它用于序列采样。文中的随机游走过程如下:从顶点开始的一次随机游走被标记为
,那么下一步要选择的顶点
是从顶点
的邻居中随机选择的。文章用这种方法完成采样并且将采样完成的序列当作语言模型中的语料来使用。
Language Model
一般来说,一个语言模型的预测目标是一个单词在一段预料中出现的概率,即给定一个单词序列:,我们需要通过最大化
来预测
。类比到我们的问题中,则应该是最大化
。但我们的目标是学习一个隐表达,设我们所需要的map为
,那么我们需要最大化
。而新的语言模型允许我们不考虑词语之间的顺序,把这个问题变成:
其中是窗口大小。在这种设定下,拥有类似邻居的节点会有相近的embedding表达。
Method
根据上述理论,DeepWalk的算法如下:


首先, 随机初始化。从V建立一颗二叉树,这主要是为了做hierarchical softmax。之后进行
轮在V上的随机游走,每一次都需要打乱V的顶点的访问顺序。每一轮V上的随机游走由从每一个顶点开始的一次长度为t的随机游走构成。在每一个随机游走序列形成以后,需要使用一次Skip-Gram算法。
Skip-Gram是一个语言模型,该模型用于最大化一个窗口内的单词的共现概率,我们在这里用于更新。具体来说,作者们运用了hierarchical softmax方法来优化完成Skip-Gram过程,并用随机梯度下降方法来完成更新。关于Skip-Gram,有兴趣的读者可以看这个blogWord2Vec Tutorial - The Skip-Gram Model。
淘宝对DeepWalk的改造
那么,还是根据一天造出10亿个淘宝首页,阿里工程师如何实现?我们该怎么把DeepWalk这个模型用到淘宝推荐系统中来呢?
生成网络
DeepWalk是一个在网络上生成embedding的模型,我们首先要生成一个网络。阿里使用SWING算法生成了一个商品之间的有向带权图作为网络。SWING其实是一个在u-i二部图上,利用一种叫做SWING的三角结构生成i-i相似度的方法,如果不会用SWING的话,应该用其他的相似度模型也可以代替这个算法。 SWINGF算法生成的i-i相似度不是对称的,所以最终形成的形式是有向带权图。
当然,有向带权图还意味着我们在random walk的时候需要根据权重对random walk进行调整。
对商品网络进行Random Walk采样
文章说他们借鉴了Node2vec: Scalable Feature Learning for Networks的采样方法。那么,这篇文章的采样方法是什么呢? node2vec本身是一个用于学习网络中节点的特征表达的半监督学习方法。它的流程其实跟DeepWalk很像。阿里在这里主要借鉴了它的random walk的流程。
首先,我们分别定义DFS和BFS邻居,如图所示:
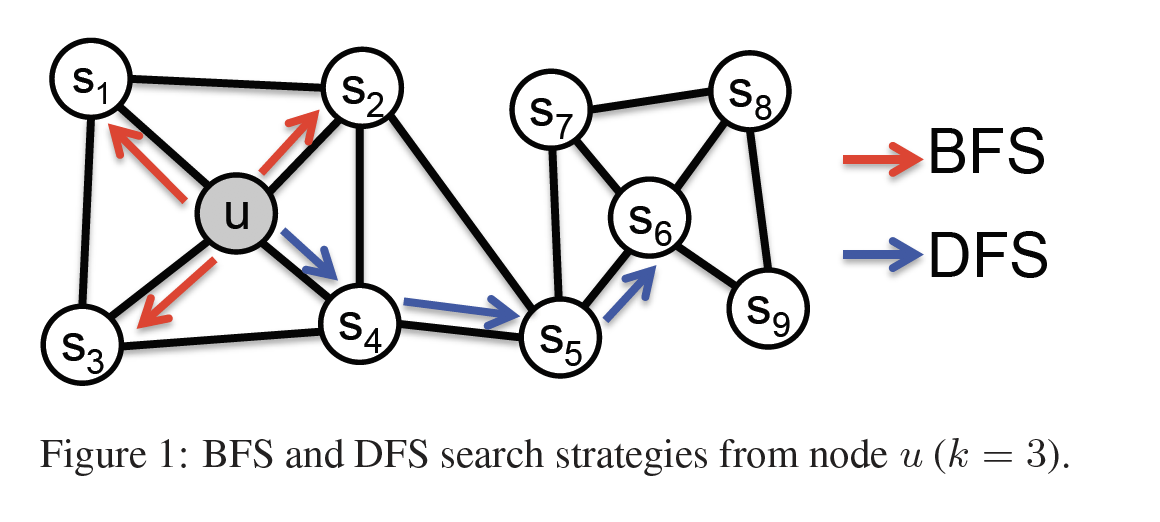
BFS邻居是指和节点直接相连的邻居节点;DFS邻居指的是sequence的邻居。BFS很容易理解,为什么要有DFS邻居这个定义呢?
网络中的节点有两种相似性:一种是趋同性,比如u和s1,一种是结构相似性,比如u和s6。BFS邻居有助于探索趋同性,而DFS邻居有助于探索结构相似性。在商品推荐中,啤酒和红酒可以认为是结构相似性,而啤酒和炸鸡可以认为是趋同性(我自己认为的,可能有误解)。在实践中,这两种相似性都很常用。Node2vec定义了同时可以运用这两种属性的random walk机制:
- 一般的random walk将选择下一节点的概率定义为正则化的转移概率。即
- 而这个random walk设计了一个bias参数。假如random walk刚从节点
走到节点
,并将下一个访问的节点记为
,令
,且
- 即设定
为回访参数,随机游走以
的概率返回节点
为远程访问参数,
除了random walk之外,node2vec还使用了negative sampling方法,用来取代DeepWalk中的hierarchical softmax方法。淘宝也同样采用了这个方法。同时,他们还采用了动态采样器的优化方式。关于Negative Sampling,有兴趣的读者可以看这个博客Word2Vec Tutorial Part 2 - Negative Sampling.
进一步优化
在上述基础上,淘宝提出了Sequence+Side-information版本。
就我的理解,所谓sequence,即用真实的用户session数据取代random walk的数据,作为训练样本。不过在这里,淘宝这个网站的特殊性是很重要的。作为一个实时更新的购物网站,用户的浏览记录之间有非常强的相关性,但是一般的网站可能相关性没有这么强,实践中能不能这么做依然存疑。
Side Information就比较好理解了,就是相当于加入一些item本身相关而structure无关的数据,加入embedding一起做训练。毕竟我们的目标是做item召回,而不是像Deep Walk那样想衡量社交网络上的相关性。
“在session内行为构建全网图后,引入类似tf-idf的转移概率连接边,克服哈利波特热点问题,且在此基础上进行概率采样,构建用户行为的"虚拟样本",以扩大后面输入到深度模型里面的宝贝覆盖量及准确度,使多阶扩展信息更加完善”这一段我其实没怎么理解,如果有理解了的读者欢迎交流。
最后一个阶段的优化其实是针对淘宝的大规模数据集的,在一般的推荐场景下很可能不需要考虑这部分的优化,当然相对于双十一这种规模的体量,这是非常重要的一部分。
总结
总而言之,淘宝的深度召回框架大概流程如下:
- 基于SWING或者任何一个i-i relevance table算法生成一个同构网络图
- 在这个网络图上根据node2vec进行random walk,收集训练样本
- 步骤1和2也可以用真实用户的session数据代替
- 在projection layer加入side information
- 执行Skip-Gram算法
ps:
关于Skip-Gram我觉得还有几个blog也写得很好,不过有些是国外博客的中文翻译:
