

第一次在实际项目中接触 Resnet 还是去年暑假实习的时候,可以说是 Resnet 带我走进深度学习的大门。去年差不多这个时候我也曾在自己的博客写过一篇对 Resnet 的总结,现在过了一年,再看去年那会的总结,感觉还是有一些不足之处,所以今天重新整理一下。
背景知识
在过去的一年里,我深刻的感觉到 Resnet 像 word2vec 一样普及到了现在的深度学习任务中,为什么这么说呢,现在我们在构建深度学习模型的时候,会认为用预训练好的词向量来初始化 Embeding 层是理所当然的;同样,在多层网络之间,用 Resnet 的思想做一个 shortcut 也逐渐被认为是理所当然的(Google 的 Transformer 就这么做了)。可以说,Resnet 是一个和word2vec 一样里程碑式的一个成果。
在深度学习任务中,网络的深度对最后的分类和识别的效果有着很大的影响,所以一般把网络设计的越深效果越好。但是事实有时却经常不如我们所愿,常规的堆叠网络层数,在网络很深的时候,效果却越来越差了。这里的效果差不是单指在测试集上的效果差,而是在训练集和测试集上的效果都变差。按我们原本的假设,网络很深的时候,会大概率发生过拟合,但是实际的情况是过拟合没有发生,反而发生是欠拟合。
Kaiming 大神在他的 Resnet 大作中这么解释这个问题,产生这种问题的原因之一即是网络越深,梯度消失的现象就越来越明显,网络的训练效果也不会很好。但是如果网络层数不深的话又无法明显提升网络的识别效果,所以他提出了 Resnet, 目标是在网络深度加深的情况下解决梯度消失的问题。
Resnet 结构

先抛出一个常规的神经网络结构,如上图所示。
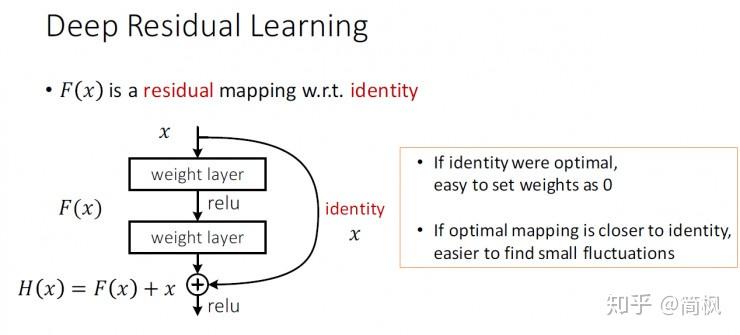
和常规的神经网络结构不同的是,ResNet 引入了残差网络结构(一个shortcht),通过残差网络,可以把网络层弄的很深,据说可以达到了1000多层,最终的网络分类的效果也是非常好,残差网络的基本结构如上图所示。
通过增加一个 shortcut(也称恒等映射),而不是简单的堆叠网络层,将原始所需要学习的函数 转换成
。这样可以解决网络由于很深出现梯度消失的问题,从而可以把网络做的很深,ResNet 其中一个网络结构如下图所示:

观察这个网络,有以下几个特点:
- 3x3 卷积层(几乎所有的卷积核都是这个大小)
- 空间规模/2 => #过滤器x2 (~每一层的复杂度相同)
- 简约的设计风格
论文中介绍了一个深层次的残差学习框架来解决精准度下降问题。并且明确地让这些层适合残差映射,而不是寄希望于每一个堆叠层直接适合一个所需的底层映射。形式上,把 作为所需的基本映射,让堆叠的非线性层适合另一个映射
。
公式 可以通过 shortcut 前馈神经网络实现。在这个场景中,shortcut 简单的执行一个恒等映射,并将它们的输出和叠加层的输出相加。shortcut 连接既不产生额外的参数,也会增加不计算的复杂度。
为什么 Resnet 效果这么好
残差网络的精美之处在于那个 shortcut 的设计 (特别像电路图里面的短路。。。)。
增加一个恒等映射 shortchut 这一步,将原始所需要学习的函数 转换成
。论文认为这两种表达的效果是相同的,但是优化的难度却大不相同。
首先作者假设 的优化会比
简单的多。这一想法也是源于图像处理中的残差向量编码,通过一个 reformulation,将一个问题分解成多个尺度直接的残差问题,能够很好的起到优化训练的效果。
我个人对于为什么 Resnet 能够这么好的解决梯度消失现象的理解是这样的,梯度消失往往是发生在反向传播更新网络参数的时候,传统的网络由于堆叠了太多的网络层,导致反向传播中参数更新的越来越慢(尤其是越靠近输入的网络层),甚至几乎不变,因此网络难以学到新的东西。而有了 Resnet 中的 shortcut 之后,通过这个恒等映射,在反向传播的时候,后面层的梯度可以直接传递到前面层,前面层的参数因此也能继续更新。
在 Resnet 中,通过 shortcut 将输入和输出进行一个 element-wise 的加叠,这个简单的加法并不会给网络增加额外的参数和计算量,同时却可以大大增加模型的训练速度、提高训练效果,并且当模型的层数加深时,这个简单的结构能够很好的解决梯度消失问题。
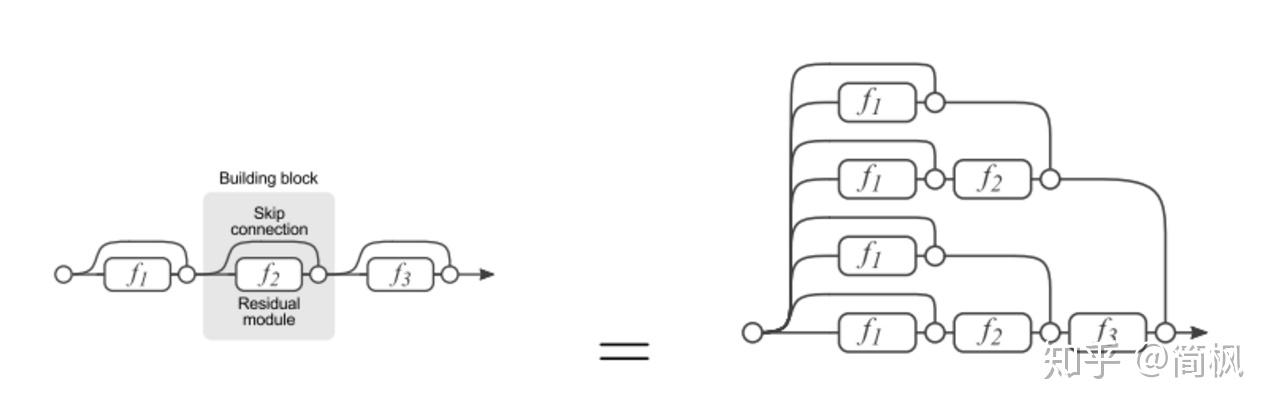
根据网上的资料,残差网络也可以从另一个角度来理解,如上图所示。
残差网络单元其中可以分解成右边的形式,从图中可以看出,残差网络其实是由多种路径组合的一个网络,即,残差网络其实是很多并行子网络的组合,整个残差网络其实相当于一个多人投票系统(ensemble)。
为了证明,如果删除残差网络的一部分
如果把残差网络理解成一个 ensemble 的系统,那么砍掉网络的一小部分就相当于少一些投票的人,如果只是删除一个基本的残差单元,对最后的分类结果应该影响很小;而最后的分类错误率应该是和删除的残差单元的个数成正比的,这个结论也被学者实验证明。
Pytorch 实现 Resnet 代码:https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py
