

论文来源:IJCAI
论文链接:Bilateral multi-perspective matching for natural language sentences
之前介绍过,在最近举办的很多数据挖掘比赛中,ESIM 都是冠军必选的模型,今天介绍一个 BiMPM,它在很多自然语言的任务中超过 ESIM 的,其实 2 个方法提出时间没差多久。虽然我没有去复现论文里面的实验,但是根据一些比赛用这个方法的感受。。。一个字,慢。。。,效果还不错,和 ESIM 不相上下吧,所以一般我不用它。
今天为什么要介绍 BiMPM 呢?因为他在设计网络结构上有很多可取之处,下面开始介绍环节。
背景
设计一个算法或者模型去判断两句话的相似性,是许多任务 (抽取式自动问答、问题推荐算法等) 的基础。目前有 2 种主流的深度学习解决方案。一种是 Siamese network (比如 ABCNN, SiaGRU): 对两个输入句子通过相同的共享权重的神经网络结构得到两个句子向量,然后对这两个句子向量做匹配。这种共享参数的方式可以有效减少学习的参数,让训练更方便。但是这种方式只是针对两个句子向量做匹配,对于两个句子之间的交互信息利用的很少。于是有了第二种方法 matching-aggregation (比如 ESIM 和 BiMPM): 这种方法首先对两个句子之间的单元做匹配 (比如各自经过 LSTM 处理后得到的不同 time step 的输出),匹配结果通过一个神经网络 (CNN或LSTM) 转化为一个向量,然后再做匹配。这种方式可以捕捉到两个句子之间的交互特征。
这里 BiMPM 的改进思路是说,之前虽然有基于 matching-aggregation 的深度学习方法去解决这类问题,但是他们对于两个句子间的交互信息提取的不够充分,我们的方法捕捉到到特征更细粒度一点。
这就是 BiMPM 方法的 contribution,提出了一种双向的多角度匹配模型(bilateral multi-perspective matching)。
BiMPM 模型:
假设我们要比较的两个句子分别为 P 和 Q。句子 P 表示的句子长度为 M,句子 Q 表示的句子长度为 N,y 表示 P 和 Q 是否相似的 label。模型的目标就是学习概率分布 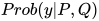 ,整体结构如下:
,整体结构如下:
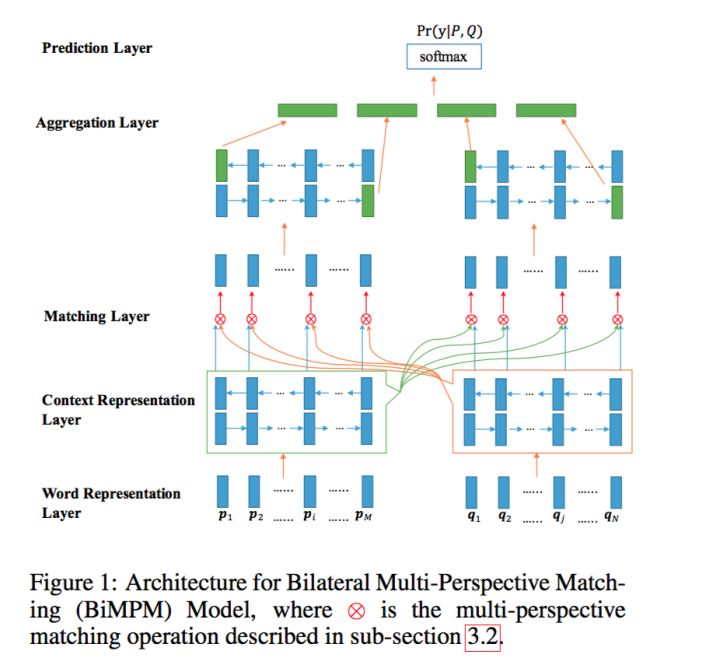
结合上面的架构图,先对模型的整体有个简单对认识。下面会分部分结合 PyTorch 实现的 BiMPM 模型的 forward 函数讲解。
初始化
定义一些后面会使用到的变量和函数
代码如下:
def __init__(self, args, data):
super(BiMPM, self).__init__()
# ----- Word Representation Layer -----
self.char_emb = nn.Embedding(args.char_vocab_size, args.char_dim, padding_idx=0)
self.word_emb = nn.Embedding(args.word_vocab_size, args.word_dim)
# initialize word embedding with GloVe or Other pre-trained word embedding
self.word_emb.weight.data.copy_(data.TEXT.vocab.vectors)
# no fine-tuning for word vectors
self.word_emb.weight.requires_grad = False
self.char_LSTM = nn.LSTM(
input_size=self.args.char_dim,
hidden_size=self.args.char_hidden_size,
num_layers=1,
bidirectional=False,
batch_first=True)
# ----- Context Representation Layer -----
self.context_LSTM = nn.LSTM(
input_size=self.d,
hidden_size=self.args.hidden_size,
num_layers=1,
bidirectional=True,
batch_first=True
)
# ----- Matching Layer -----
for i in range(1, 9):
setattr(self, f'mp_w{i}',
nn.Parameter(torch.rand(self.l, self.args.hidden_size)))
# ----- Aggregation Layer -----
self.aggregation_LSTM = nn.LSTM(
input_size=self.l * 8,
hidden_size=self.args.hidden_size,
num_layers=1,
bidirectional=True,
batch_first=True
)
# ----- Prediction Layer -----
self.pred_fc1 = nn.Linear(self.args.hidden_size * 4, self.args.hidden_size * 2)
self.pred_fc2 = nn.Linear(self.args.hidden_size * 2, self.args.class_size)
Word Representation Layer
将句子中的每个词语表示为 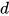 维向量,这里 维向量分为两部分:一部分是固定的词向量,另一部分是字符向量构成的词向量,这里将一个单词里面的每个字符向量经过 LSTM 处理得到最后的词向量作为这部分输入。
维向量,这里 维向量分为两部分:一部分是固定的词向量,另一部分是字符向量构成的词向量,这里将一个单词里面的每个字符向量经过 LSTM 处理得到最后的词向量作为这部分输入。
代码如下:
p = self.word_emb(kwargs['p'])
h = self.word_emb(kwargs['h'])
p = self.dropout(p)
h = self.dropout(h)
if self.args.use_char_emb:
# (batch, seq_len, max_word_len) -> (batch * seq_len, max_word_len)
seq_len_p = kwargs['char_p'].size(1)
seq_len_h = kwargs['char_h'].size(1)
char_p = kwargs['char_p'].view(-1, self.args.max_word_len)
char_h = kwargs['char_h'].view(-1, self.args.max_word_len)
# (batch * seq_len, max_word_len, char_dim)-> (1, batch * seq_len, char_hidden_size)
_, (char_p, _) = self.char_LSTM(self.char_emb(char_p))
_, (char_h, _) = self.char_LSTM(self.char_emb(char_h))
# (batch, seq_len, char_hidden_size)
char_p = char_p.view(-1, seq_len_p, self.args.char_hidden_size)
char_h = char_h.view(-1, seq_len_h, self.args.char_hidden_size)
# (batch, seq_len, word_dim + char_hidden_size)
p = torch.cat([p, char_p], dim=-1)
h = torch.cat([h, char_h], dim=-1)Context Representation Layer
将上下文信息融合到 P 和 Q 每个 time-step 的表示中,这里利用 Bi-LSTM 去得到 P 和 Q 每个time-step 的上下文向量。
代码如下:
# ----- Context Representation Layer -----
# (batch, seq_len, hidden_size * 2)
con_p, _ = self.context_LSTM(p)
con_h, _ = self.context_LSTM(h)
con_p = self.dropout(con_p)
con_h = self.dropout(con_h)
# (batch, seq_len, hidden_size)
con_p_fw, con_p_bw = torch.split(con_p, self.args.hidden_size, dim=-1)
con_h_fw, con_h_bw = torch.split(con_h, self.args.hidden_size, dim=-1)Matching Layer
双向:比较句子 P 的每个上下文向量(time-step)和句子 Q 的所有上下文向量(time-step),比较句子 Q 的每个上下文向量(time-step)和句子 P 的所有上下文向量(time-step)。为了比较一个句子中某个上下文向量(time-step)和另外一个句子的所有上下文向量(time-step),这里设计了一种 multi-perspective 的匹配方法,用于获取两个句子细粒度的联系信息。
这层的输出是两个序列,序列中每一个向量是一个句子的某个 time-step 相对于另一个句子所有的 time-step 的匹配向量。
代码如下:
# ----- Matching Layer -----
# 1. Full-Matching
# (batch, seq_len, hidden_size), (batch, hidden_size)
# -> (batch, seq_len, l)
mv_p_full_fw = mp_matching_func(con_p_fw, con_h_fw[:, -1, :], self.mp_w1)
mv_p_full_bw = mp_matching_func(con_p_bw, con_h_bw[:, 0, :], self.mp_w2)
mv_h_full_fw = mp_matching_func(con_h_fw, con_p_fw[:, -1, :], self.mp_w1)
mv_h_full_bw = mp_matching_func(con_h_bw, con_p_bw[:, 0, :], self.mp_w2)
# 2. Maxpooling-Matching
# (batch, seq_len1, seq_len2, l)
mv_max_fw = mp_matching_func_pairwise(con_p_fw, con_h_fw, self.mp_w3)
mv_max_bw = mp_matching_func_pairwise(con_p_bw, con_h_bw, self.mp_w4)
# (batch, seq_len, l)
mv_p_max_fw, _ = mv_max_fw.max(dim=2)
mv_p_max_bw, _ = mv_max_bw.max(dim=2)
mv_h_max_fw, _ = mv_max_fw.max(dim=1)
mv_h_max_bw, _ = mv_max_bw.max(dim=1)
# 3. Attentive-Matching
# (batch, seq_len1, seq_len2)
att_fw = attention(con_p_fw, con_h_fw)
att_bw = attention(con_p_bw, con_h_bw)
# (batch, seq_len2, hidden_size) -> (batch, 1, seq_len2, hidden_size)
# (batch, seq_len1, seq_len2) -> (batch, seq_len1, seq_len2, 1)
# -> (batch, seq_len1, seq_len2, hidden_size)
att_h_fw = con_h_fw.unsqueeze(1) * att_fw.unsqueeze(3)
att_h_bw = con_h_bw.unsqueeze(1) * att_bw.unsqueeze(3)
# (batch, seq_len1, hidden_size) -> (batch, seq_len1, 1, hidden_size)
# (batch, seq_len1, seq_len2) -> (batch, seq_len1, seq_len2, 1)
# -> (batch, seq_len1, seq_len2, hidden_size)
att_p_fw = con_p_fw.unsqueeze(2) * att_fw.unsqueeze(3)
att_p_bw = con_p_bw.unsqueeze(2) * att_bw.unsqueeze(3)
# (batch, seq_len1, hidden_size) / (batch, seq_len1, 1) -> (batch, seq_len1, hidden_size)
att_mean_h_fw = div_with_small_value(att_h_fw.sum(dim=2), att_fw.sum(dim=2, keepdim=True))
att_mean_h_bw = div_with_small_value(att_h_bw.sum(dim=2), att_bw.sum(dim=2, keepdim=True))
# (batch, seq_len2, hidden_size) / (batch, seq_len2, 1) -> (batch, seq_len2, hidden_size)
att_mean_p_fw = div_with_small_value(att_p_fw.sum(dim=1), att_fw.sum(dim=1, keepdim=True).permute(0, 2, 1))
att_mean_p_bw = div_with_small_value(att_p_bw.sum(dim=1), att_bw.sum(dim=1, keepdim=True).permute(0, 2, 1))
# (batch, seq_len, l)
mv_p_att_mean_fw = mp_matching_func(con_p_fw, att_mean_h_fw, self.mp_w5)
mv_p_att_mean_bw = mp_matching_func(con_p_bw, att_mean_h_bw, self.mp_w6)
mv_h_att_mean_fw = mp_matching_func(con_h_fw, att_mean_p_fw, self.mp_w5)
mv_h_att_mean_bw = mp_matching_func(con_h_bw, att_mean_p_bw, self.mp_w6)
# 4. Max-Attentive-Matching
# (batch, seq_len1, hidden_size)
att_max_h_fw, _ = att_h_fw.max(dim=2)
att_max_h_bw, _ = att_h_bw.max(dim=2)
# (batch, seq_len2, hidden_size)
att_max_p_fw, _ = att_p_fw.max(dim=1)
att_max_p_bw, _ = att_p_bw.max(dim=1)
# (batch, seq_len, l)
mv_p_att_max_fw = mp_matching_func(con_p_fw, att_max_h_fw, self.mp_w7)
mv_p_att_max_bw = mp_matching_func(con_p_bw, att_max_h_bw, self.mp_w8)
mv_h_att_max_fw = mp_matching_func(con_h_fw, att_max_p_fw, self.mp_w7)
mv_h_att_max_bw = mp_matching_func(con_h_bw, att_max_p_bw, self.mp_w8)
# (batch, seq_len, l * 8)
mv_p = torch.cat(
[mv_p_full_fw, mv_p_max_fw, mv_p_att_mean_fw, mv_p_att_max_fw,
mv_p_full_bw, mv_p_max_bw, mv_p_att_mean_bw, mv_p_att_max_bw], dim=2)
mv_h = torch.cat(
[mv_h_full_fw, mv_h_max_fw, mv_h_att_mean_fw, mv_h_att_max_fw,
mv_h_full_bw, mv_h_max_bw, mv_h_att_mean_bw, mv_h_att_max_bw], dim=2)
mv_p = self.dropout(mv_p)
mv_h = self.dropout(mv_h)Aggregation Layer
Aggregation Layer 的主要功能是聚合两个匹配向量序列为一个固定长度的匹配向量。对两个匹配序列分别使用 Bi-LSTM,然后连接 Bi-LSTM 最后一个 time-step 的向量(4个)得到最后的匹配向量。
代码如下:
# ----- Aggregation Layer -----
# (batch, seq_len, l * 8) -> (2, batch, hidden_size)
_, (agg_p_last, _) = self.aggregation_LSTM(mv_p)
_, (agg_h_last, _) = self.aggregation_LSTM(mv_h)
# 2 * (2, batch, hidden_size) -> 2 * (batch, hidden_size * 2) -> (batch, hidden_size * 4)
x = torch.cat(
[agg_p_last.permute(1, 0, 2).contiguous().view(-1, self.args.hidden_size * 2),
agg_h_last.permute(1, 0, 2).contiguous().view(-1, self.args.hidden_size * 2)], dim=1)
x = self.dropout(x)Prediction Layer
预测概率 ,利用两层前馈神经网络然后接 softmax 分类。激活函数使用 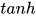 。
。
代码如下:
# ----- Prediction Layer -----
x = F.tanh(self.pred_fc1(x))
x = self.dropout(x)
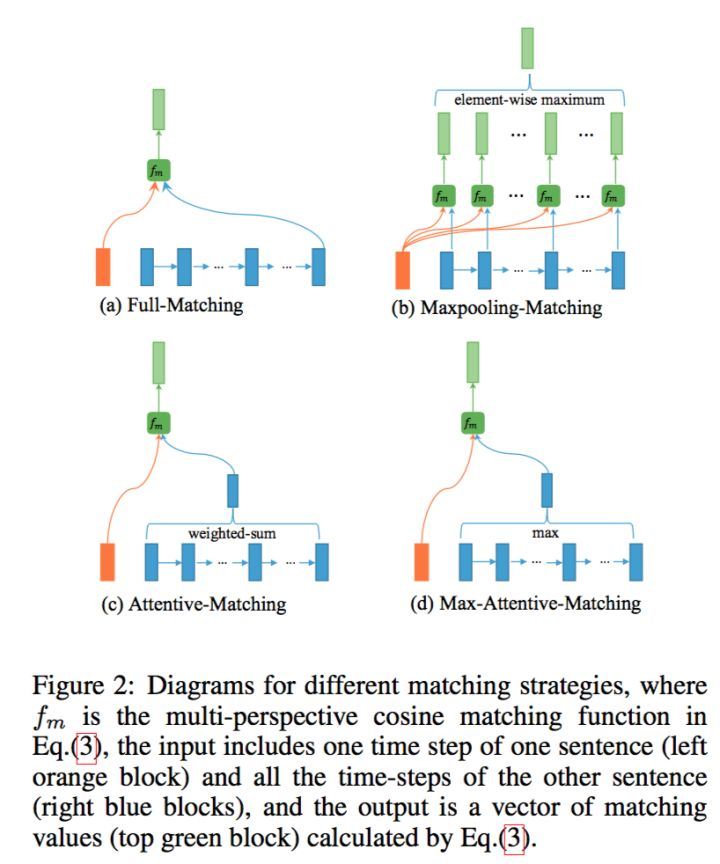
x = self.pred_fc2(x)这里的 Multi-perspective Matching 可以分为以下四种方案:
首先,定义比较两个向量的 multi-perspective 余弦函数 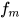
(对应代码里面的 mp_matching_func)
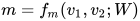
这里 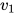 和
和 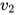 是 维向量,W 是
是 维向量,W 是 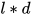 的可训练的参数,
的可训练的参数,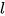 表示的是 perspcetive 的个数,所以m 是一个 维的向量,每一维度表示的是两个加权向量的余弦相似度:
表示的是 perspcetive 的个数,所以m 是一个 维的向量,每一维度表示的是两个加权向量的余弦相似度:
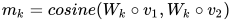
接着,为了比较一个句子的某个 time-step 与另一个句子的所有 time-step,制定了四种匹配策略,下面分别来介绍。
1. Full-Matching
取一个句子的某个 time-step 和另一个句子的最后一个 time-step 做比较
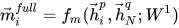
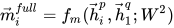
代码如下:
def mp_matching_func(v1, v2, w):
"""
:param v1: (batch, seq_len, hidden_size)
:param v2: (batch, seq_len, hidden_size) or (batch, hidden_size)
:param w: (l, hidden_size)
:return: (batch, l)
"""
seq_len = v1.size(1)
# (1, 1, hidden_size, l)
w = w.transpose(1, 0).unsqueeze(0).unsqueeze(0)
# (batch, seq_len, hidden_size, l)
v1 = w * torch.stack([v1] * self.l, dim=3)
if len(v2.size()) == 3:
v2 = w * torch.stack([v2] * self.l, dim=3)
else:
v2 = w * torch.stack([torch.stack([v2] * seq_len, dim=1)] * self.l, dim=3)
m = F.cosine_similarity(v1, v2, dim=2)
return m
# 1. Full-Matching
# (batch, seq_len, hidden_size), (batch, hidden_size)
# -> (batch, seq_len, l)
mv_p_full_fw = mp_matching_func(con_p_fw, con_h_fw[:, -1, :], self.mp_w1)
mv_p_full_bw = mp_matching_func(con_p_bw, con_h_bw[:, 0, :], self.mp_w2)
mv_h_full_fw = mp_matching_func(con_h_fw, con_p_fw[:, -1, :], self.mp_w1)
mv_h_full_bw = mp_matching_func(con_h_bw, con_p_bw[:, 0, :], self.mp_w2)2. Max-pooling-Matching
取一个句子的某个 time-step 和另一个句子的所有 time-step 比较后取最大
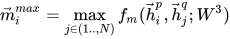
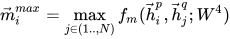
代码如下:
def div_with_small_value(n, d, eps=1e-8):
# too small values are replaced by 1e-8 to prevent it from exploding.
d = d * (d > eps).float() + eps * (d <= eps).float()
return n / d
def mp_matching_func_pairwise(v1, v2, w):
# (1, l, 1, hidden_size)
w = w.unsqueeze(0).unsqueeze(2)
# (batch, l, seq_len, hidden_size)
v1, v2 = w * torch.stack([v1] * self.l, dim=1), w * torch.stack([v2] * self.l, dim=1)
# (batch, l, seq_len, hidden_size->1)
v1_norm = v1.norm(p=2, dim=3, keepdim=True)
v2_norm = v2.norm(p=2, dim=3, keepdim=True)
# (batch, l, seq_len1, seq_len2)
n = torch.matmul(v1, v2.transpose(2, 3))
d = v1_norm * v2_norm.transpose(2, 3)
# (batch, seq_len1, seq_len2, l)
m = div_with_small_value(n, d).permute(0, 2, 3, 1)
# 2. Maxpooling-Matching
# (batch, seq_len1, seq_len2, l)
mv_max_fw = mp_matching_func_pairwise(con_p_fw, con_h_fw, self.mp_w3)
mv_max_bw = mp_matching_func_pairwise(con_p_bw, con_h_bw, self.mp_w4)
# (batch, seq_len, l)
mv_p_max_fw, _ = mv_max_fw.max(dim=2)
mv_p_max_bw, _ = mv_max_bw.max(dim=2)
mv_h_max_fw, _ = mv_max_fw.max(dim=1)
mv_h_max_bw, _ = mv_max_bw.max(dim=1)3. Attentive-Matching
首先计算一个句子的某个 time-step 和另一个句子的所有 time-step 的余弦相似度,类似 Attention 矩阵。
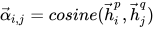
利用上面的余弦相似度对另一个句子的所有 time-step 加权取平均
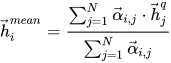
最后比较一个句子的某个 time-step 与另一个句子的加权 time-step
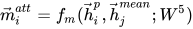
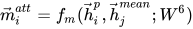
代码如下:
def attention(v1, v2):
"""
:param v1: (batch, seq_len1, hidden_size)
:param v2: (batch, seq_len2, hidden_size)
:return: (batch, seq_len1, seq_len2)
"""
# (batch, seq_len1, 1)
v1_norm = v1.norm(p=2, dim=2, keepdim=True)
# (batch, 1, seq_len2)
v2_norm = v2.norm(p=2, dim=2, keepdim=True).permute(0, 2, 1)
# (batch, seq_len1, seq_len2)
a = torch.bmm(v1, v2.permute(0, 2, 1))
d = v1_norm * v2_norm
return div_with_small_value(a, d)
def div_with_small_value(n, d, eps=1e-8):
# too small values are replaced by 1e-8 to prevent it from exploding.
d = d * (d > eps).float() + eps * (d <= eps).float()
return n / d
def mp_matching_func(v1, v2, w):
"""
:param v1: (batch, seq_len, hidden_size)
:param v2: (batch, seq_len, hidden_size) or (batch, hidden_size)
:param w: (l, hidden_size)
:return: (batch, l)
"""
seq_len = v1.size(1)
# (1, 1, hidden_size, l)
w = w.transpose(1, 0).unsqueeze(0).unsqueeze(0)
# (batch, seq_len, hidden_size, l)
v1 = w * torch.stack([v1] * self.l, dim=3)
if len(v2.size()) == 3:
v2 = w * torch.stack([v2] * self.l, dim=3)
else:
v2 = w * torch.stack([torch.stack([v2] * seq_len, dim=1)] * self.l, dim=3)
m = F.cosine_similarity(v1, v2, dim=2)
return m
# 3. Attentive-Matching
# (batch, seq_len1, seq_len2)
att_fw = attention(con_p_fw, con_h_fw)
att_bw = attention(con_p_bw, con_h_bw)
# (batch, seq_len2, hidden_size) -> (batch, 1, seq_len2, hidden_size)
# (batch, seq_len1, seq_len2) -> (batch, seq_len1, seq_len2, 1)
# -> (batch, seq_len1, seq_len2, hidden_size)
att_h_fw = con_h_fw.unsqueeze(1) * att_fw.unsqueeze(3)
att_h_bw = con_h_bw.unsqueeze(1) * att_bw.unsqueeze(3)
# (batch, seq_len1, hidden_size) -> (batch, seq_len1, 1, hidden_size)
# (batch, seq_len1, seq_len2) -> (batch, seq_len1, seq_len2, 1)
# -> (batch, seq_len1, seq_len2, hidden_size)
att_p_fw = con_p_fw.unsqueeze(2) * att_fw.unsqueeze(3)
att_p_bw = con_p_bw.unsqueeze(2) * att_bw.unsqueeze(3)
# (batch, seq_len1, hidden_size) / (batch, seq_len1, 1) -> (batch, seq_len1, hidden_size)
att_mean_h_fw = div_with_small_value(att_h_fw.sum(dim=2), att_fw.sum(dim=2, keepdim=True))
att_mean_h_bw = div_with_small_value(att_h_bw.sum(dim=2), att_bw.sum(dim=2, keepdim=True))
# (batch, seq_len2, hidden_size) / (batch, seq_len2, 1) -> (batch, seq_len2, hidden_size)
att_mean_p_fw = div_with_small_value(att_p_fw.sum(dim=1), att_fw.sum(dim=1, keepdim=True).permute(0, 2, 1))
att_mean_p_bw = div_with_small_value(att_p_bw.sum(dim=1), att_bw.sum(dim=1, keepdim=True).permute(0, 2, 1))
# (batch, seq_len, l)
mv_p_att_mean_fw = mp_matching_func(con_p_fw, att_mean_h_fw, self.mp_w5)
mv_p_att_mean_bw = mp_matching_func(con_p_bw, att_mean_h_bw, self.mp_w6)
mv_h_att_mean_fw = mp_matching_func(con_h_fw, att_mean_p_fw, self.mp_w5)
mv_h_att_mean_bw = mp_matching_func(con_h_bw, att_mean_p_bw, self.mp_w6)4. Max-Attentive-Matching
方法与 3 类似,只是加权平均变成了取最大
# 4. Max-Attentive-Matching
# (batch, seq_len1, hidden_size)
att_max_h_fw, _ = att_h_fw.max(dim=2)
att_max_h_bw, _ = att_h_bw.max(dim=2)
# (batch, seq_len2, hidden_size)
att_max_p_fw, _ = att_p_fw.max(dim=1)
att_max_p_bw, _ = att_p_bw.max(dim=1)
# (batch, seq_len, l)
mv_p_att_max_fw = mp_matching_func(con_p_fw, att_max_h_fw, self.mp_w7)
mv_p_att_max_bw = mp_matching_func(con_p_bw, att_max_h_bw, self.mp_w8)
mv_h_att_max_fw = mp_matching_func(con_h_fw, att_max_p_fw, self.mp_w7)
mv_h_att_max_bw = mp_matching_func(con_h_bw, att_max_p_bw, self.mp_w8)总结
其实怎么看怎么觉得 BiMPM 和 ESIM 很像很像,他们都有 Match Layer 和 Aggregation Layer。主要使用的也都是 Bi-LSTM,区别主要在于 Match 的方式不同,BiMPM 利用的信息更多一点。
个人感觉,ESIM 是这个领域的一个突破,提出类似 matching-aggregation 的模型,BiMPM 在此基础上更进一步,当然,代价是参数变多,训练更慢(个人的感受,如果有大佬不同意,欢迎反驳)。
BiMPM 在匹配过程中,从多视野的角度,一个句子的每一步都与另一个句子的所有 time-steps 对应匹配 (类比 ESIM 中的 soft-attention-align,是不是很像?)。最后也是用一个 Bi-LSTM被用来集合所有匹配结果到一个固定长度的向量(ESIM 最后 overall modeling 的时候也有这一步,用双层 Bi-LSTM 来 aggregate)。
BiMPM 有一个地方我觉得很值得学习,它使用词级别和字符级别的词向量。这倒没什么特别的,特别的是它在使用字符级别的词向量的时候,先用 LSTM 去编码一下,这里有点 elmo 利用语言模型的意思(这里不展开了,以后专门开坑讲 Elmo。。。)
总之,BiMPM 更加注重句子之间交互信息,从不同层次不同粒度来匹配待比较的句子,这样效果怎么能不好?
代码地址
参考
《Bilateral Multi-Perspective Matching for Natural Language Sentences》读书笔记
