

背景:由于以前的应用多且杂,所以最近对公司的应用进行优化改造,需要所有接口RT达到xxx值以下。
一、监控
那么问题来了~现在应用都是放养式的,几乎没有什么监控工具,不可能根据log一个接口一个接口去捞日志,那怎么知道哪些接口rt长,需要优化呢。 所以第一步我们做的事情就是上监控。
监控工具:pinpoint。
选择pinpoint有几个方面的考量:
1.对应用代码0侵入,这个当然是我们程序员最关心的,谁都不喜欢因为附加功能在自己的应用大动干戈,万一影响原有业务就不值得了。。
2.应用依赖关系,调用关系一目了然,通过一个traceId将所有流程串起来,方便排查问题。这一点也是非常重要,在分布式系统中,调用关系请求太复杂,如果没有traceId标识,你是很难找到这个请求的上层调用关系的。
3.接口各种监控图表,当然也包括RT图表,便于快速定位需要优化的链路。
pinpoint的源码及教程可参考https://github.com/naver/pinpoint。
我们可以大致看一下pinpoint的监控页面,如下图
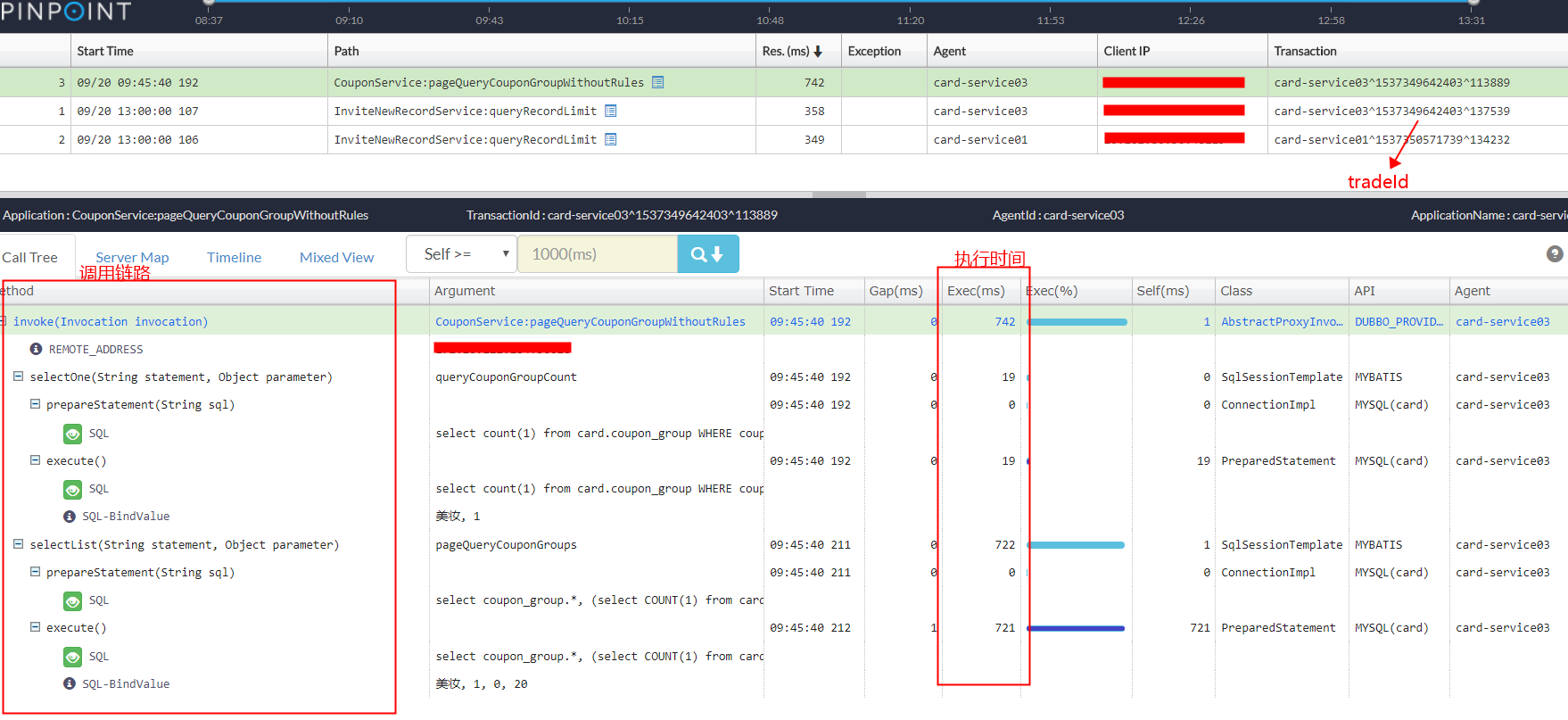
调用链路一列看出该请求实际执行了2次SQL。
执行时间一列看出第一次耗时19ms,第二次722ms。
traceId是此次请求的唯一标识,如果我们在应用需要记录该值,也可通过对应API获取。
当然这个示例只是一次很简单的请求,他还能监控dubbo调用、http请求、Redis、db等等操作,所以只要应用配置了它,那么该请求执行的调用细节就一目了然,尽在我们掌握之中,而不是放养任其发展。
二、优化
既然目标已经被我们揪出来了,那我们下一步当然就是把它解决掉,优化它。我从优化过程中得出一些很普遍,实用的优化经验,特别是对于初学者,可以多多参考。因为对于刚开始编程的来说这些就是习惯,正常的逻辑,但并不代表它就是最优的。
1.循环SQL操作
这类情况对于新手来说很容易犯,比如就创建交易订单。我们主子单关系如下:
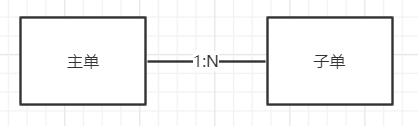
那么创建订单需要生成1个主单,N个子单,这时很多这么写(代码仅表示执行流程):
insert(主单);
for(子单:子单列表){
insert(子单);
}
所以就出现循环SQL操作,因为SQL操作比较耗时,循环的话就会大大拉大整个接口的rt时长,这种情况我们应该一次性把所有子单insert,而不是一次一次地操作,优化后代码类似为这样:
insert(主单);
batchInsert(子单列表);
Mybatits是支持循环标签的,所以在sqlMap文件里改造一下SQL就可以了。另外批量update也是可以的,执行批量操作需要在数据库链接加上参数allowMultiQueries=true
2.数据库索引
索引当然是必须要建的,不然得查到什么时候。不过建归建,但是我们还要正确的运用它。
我们可以通过explain命令检测SQL是否使用索引。
EXPLAIN SELECT * FROM article WHERE id=10;

key和rows反应了使用的索引以及预计需要扫描的行数。 还有一些我们需要注意的:
在我们优化Query语句中的ORDER BY的时候,尽可能利用已有的索引来避免实际的排序计算,可以很大幅度的提升 ORDER BY操作的性能。在有些 Query 的优化过程中,即使为了避免实际的排序操作而调整索引字段的顺序,甚至是增加索引字段也是值得的 因为MySQL中,order by的实现有两种类型:
1).一种是通过有序索引而直接取得有序的数据,这样不用进行任何排序操作即可得到满足客户端 要求的有序数据返回给客户端;

2).一种则需要通过 MySQL 的排序算法将存储引擎中返回的数据进行排序然后再将排序后的数 据返回给客户端

user_id,define_id,seq联合索引,可以看出第一张图排序define_id直接走索引,第二张图走不了索引需要额外的排序操作Using filesort.group by 其实也是进行了order by操作 然后进行分组,所以group by也是类似的优化方式。
DISTINCT尽量少用,DISTINCT其实也是进行了一次group by操作,然后每一组取的第一条记录。
java应用的类型一定和数据库索引列的类型匹配,例如java类型为long,数据库类型为varchar,这样去查询是用不了索引的,但是不会报错。 下图是两种方式的对比:


3.count计数千万不能用
计数也是我们经常用到的,比如优惠券领取数量,统计活动参加人数。这些有时是和业务强耦合的。比如秒杀只能卖出多少件等等。这类场景我们千万不能使用count来计数。我们来分析一下为什么不使用count:
1).count会查询所有满足条件的记录,如果表非常大,这将可能导致全表扫描,这后果大家都知道的吧。 2).如果使用count来控制,那么在业务逻辑执行期间,肯定要加锁,否则刚才count的结果就白操作了,这将也会阻止所有对该活动的请求。
这种场景我们一般都是在需要控制的记录上加个计数字段,比如控制最大领取值num=10个。那在业务逻辑里面可将对总数控制转为通过SQL的方式,
update xxx set num=num-1 where id=xx and num>0;
这是原子操作,可保证一定不会超领。根据返回结果判断是否执行成功(返回结果为影响的行数)。
4.锁
单机锁和分布式锁,锁其实我们能够避免就不要使用它,因为加锁就代表只能串行执行,并发数降为1,这肯定影响性能。
如果是类似库存扣减的场景,可参考第3条。通过数据库的原子操作来避免。
如果是更新等操作,可通过乐观锁来避免长时间的阻塞。
如果非要使用锁,不管是单机锁还是分布式锁,我们一定要评估该锁的影响范围,是针对单个用户userId还是所有的用户userId,单个用户是可以采用的,因为单个用户并发度极低,但是如果是所有用户的操作加锁,那一定要好好评估,这个操作会导致所有用户的类似操作阻塞。
5.适当冗余
在分布式系统中,冗余应该是非常常见的情况。我们这个时候就不要追求数据库范式的标准了,因为按照数据库第几范式来设计,所有字段都不冗余,但是这给我们查询带来很大麻烦。可能我们查一个订单,需要关联查询,查子单信息,查商品信息,查支付信息等等,查询这么多,想想我们接口的rt能快吗,qps能高吗。将商品名称等基本信息冗余可减少对其实模块的查询,未尝不是一种好的方式。
6.Redis缓存
其实缓存在我们系统普遍都用到了,所以对这部分优化不多。还是总结一些经验。 缓存的刷新策略选择:失效刷新还是定时刷新。 因为监控到很多接口RT总是有规律的变慢,这是因为都是在缓存失效的时候,需要从db及其他模块组装数据,然后推到缓存,这时所有请求都走不了缓存,在流量大的时候也有可能成为致命的因素。如果是这种情况,例如首页推荐商品、推荐帖子等等访问量大且相同的场景可以通过定时刷新的方式。 Keys*命令线上严禁使用:Redis是单线程,该命令的执行将会导致所有后续请求阻塞,影响整个系统性能。
7.搜索引擎
可能看到这个比较疑惑,搜索引擎怎么还能优化RT,他比DB当然慢,但是在某些场景他可以比DB更快。例如一个社区论坛,需要对文章进行筛选排序,总共十来个字段,而且自由组合,这时DB就无能为力,因为条件太多,各种排序操作,关联操作,数据库没办法建索引。我们可以通过将A、B表中的字段构建成完整的信息,推送到搜索引擎,查询的时候直接根据条件搜索。这样既能保证rt,又能避免DB被复杂查询拖垮。
