

背景
检索对实时性的要求很高,不仅是对索引建立、结果召回、策略干扰等核心部分,也包括数据录入的部分。检索的数据流主要包括全量数据与增量数据,其中全量数据是在运行前就已经生成好的,在检索进程运行开始时就直接解析加载了,后面不会再产生,所以不会对录入有高实时性的需求;而增量数据理论上在整个检索进程运行过程中随时都可能新增,新增了就需要录入。所以,提高增量数据录入的实时性,对提升整个检索的性能有重要作用。
设计思路与折衷
目前搜索引擎实现增量更新的方案主要有这几种:(1)提供写接口,(2)使用文件,(3)使用消息队列。
方案1即检索框架本身提供写数据的接口,数据发布方直接调用,写入数据。这种方式应该是单次写入速度最快的,但会使两方代码过于耦合,不易扩展和维护。且检索框架需要提供数据接收读取的完整机制,也要消耗很多资源。对于发布方来说,发布操作也必须依赖接收方的进度。如果数据更新频率很低,数据量很小,可以考虑使用这种方式。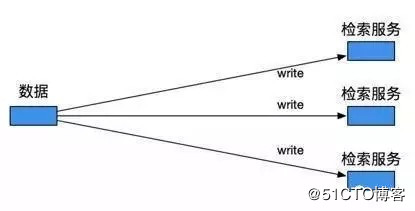
方案2主要是通过文件形式,即每次有新数据到来时,都先写入一个文件中,然后定期将文件配送到检索进程本地。检索服务运行时,会监控本地文件夹的inode变化,一旦有文件产生或修改,就执行回调函数,读取该文件,进行增量加载。这种方式一定程度上实现了数据发布方和接收方的解耦,但代价是要增加对文件的操作,并且实际应用中需要依赖数据配送,这是个很耗时的过程。文件本身的产生,拷贝,读写,效率也不算高,尤其在文件内容堆积得很大的时候。所以这种方案,实时性很难保证。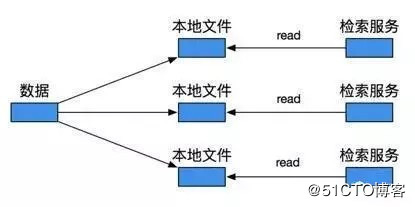
方案3是通过消息队列。数据发布方将数据推到消息队列中,接收方自己读取。这种方式很好地实现了双方业务的解耦,且无需维护对文件的一系列操作,也无需数据配送,实时性大大提升。对于发布方来说,不用再记录数据到底要发给哪几个检索实例,只需发布一份数据到消息队列中即可,检索实例的增加、减少也都不需要在发布方进行修改,更加灵活。对于接收方,不用再定期处理堆积得很多的数据,资源使用也更平衡。同时也可以方便地实现流量控制等。不过稳定性需要依赖于消息队列本身。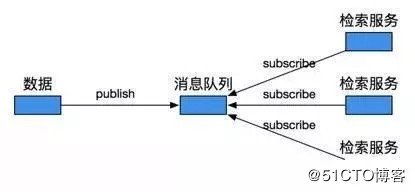
目前糯米的检索使用的是方案2,框架成熟,运行稳定,容错容灾也都很完整。但针对糯米本身的业务特点,仍有可以改进的空间。糯米主要是提供生活服务类的检索,特点就是数据更新频繁,数据量大。而文件形式的更新,第一是实时性较差,第二是灵活性不高。而这些都可以通过消息队列的特点进行优化。
消息队列大都分为队列模式和订阅模式,根据业务需求,多个检索实例都需要相同的一份数据,所以选择订阅模式。
针对业务特点,最终选择方案3,使用消息队列的订阅模式,来实现数据的实时加载。
具体实现
糯米现有检索框架一般都是在一个单独的线程中监控文件变化,通过回调实现增量数据加载。主线程只需在其时传入需要的配置以及对数据进行处理的回调函数即可,耦合度很低。所以消息队列的添加理论上只需对这个线程所做的工作进行相应修改即可。
糯米现有检索框架中,增量数据加载的工作流程大致如下:
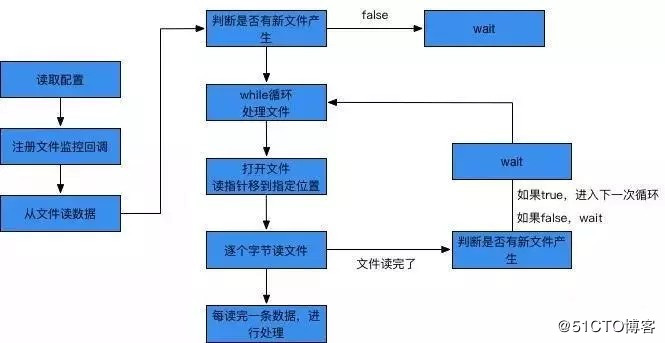
首先读取配置文件信息,包括增量文件的命名规则以及读到的行数等,这是为了后面打开文件及移动读指针做准备。这些配置放在本地一个单独的文件中。之后注册监控的回调函数,在文件夹inode发生变化时,会触发raise唤醒wait中的处理线程,从指定行开始逐个字节读文件,每读完一条数据就进行一次处理,读完整个文件后,就wait直到下个文件产生。
可见,整个流程都是围绕着文件展开的。改为使用消息队列读取数据后,这些和文件相关的操作就都不需要了,改为接入相应消息队列的订阅相关接口。下面描述一种使用消息队列(Kafka)的订阅模式进行数据加载的大致流程: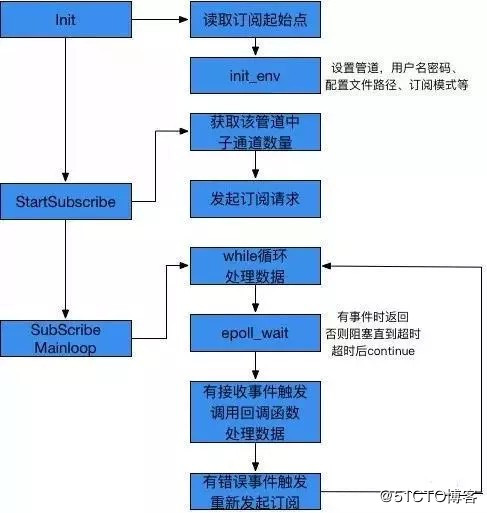
首先添加一个消息队列的订阅类,定义实现异步订阅的基本方法。
init中,主要实现对各个参数的配置,以及订阅起始点的读取。这个起始点是由数据发布方给出的,所以要在发起订阅前就设定好。目前的做法和上面一样,单独在本地建一个配置文件,里面存放了起始点的相关数据,init中直接读取即可。
StartSubscribe主要包含两个方法:获取要订阅的消息队列的子通道的数量,然后对每个子通道发起订阅请求。
之后进入SubscribeMainloop,在while循环中接收、处理数据。接收事件通过epoll_wait,只要有可读或报错事件触发,epoll_wait就会返回,否则会阻塞直到超时或有新事件到来。
epoll_wait返回后,如果包含可读事件,就调用回调函数进行处理即可。如果包含报错事件,会根据报错尝试重新发起订阅请求。
这样一条增量数据的加载就完成了,while循环会一直重复这个流程,直到加载完消息队列里最新的一条数据。之后就会阻塞在epoll_wait上,直到有新的数据发布进来。
总结
本文简单介绍了一种使用消息队列的订阅模式实现通用检索框架增量数据加载的新方案,及其设计与实现。糯米现有检索框架文件形式的更新,由于数据配送系统本身的复杂性,需要至少半小时才能更新一次数据。而使用消息队列更新一条数据的用时在0.5秒以内,更新1000条数据也可在2秒以内完成,实现了准实时流,值得全面推广在检索框架的增量数据录入部分使用。为什么某些人会一直比你优秀,是因为他本身就很优秀还一直在持续努力变得更优秀,而你是不是还在满足于现状内心在窃喜,
转载:http://blog.51cto.com/13732225/2175348
