



作者:UC 国际研发 叫兽
写在最前:欢迎你来到“UC国际技术”公众号,我们将为大家提供与客户端、服务端、算法、测试、数据、前端等相关的高质量技术文章,不限于原创与翻译。
 Call Stack 与 Stack 的概念
Call Stack 与 Stack 的概念Call Stack(调用栈) 一般指计算机程序执行时子程序之间消息处理的相互调用产生的一些列函数序列,而且几乎所有的计算机程序都依赖于调用栈。
在探讨 Call Stack 前,先来搞清楚 Stack(栈)的概念。
Stack 就是一种特殊的串列形式的数据结构,特殊之处在于只能允许在链接串列或阵列的一端(称为堆叠顶端指标,英语:top)进行加入数据(英语:push)和输出数据(英语:pop)的运算。因此栈的数据结构只允许在一端进行操作,按照后进先出(LIFO, Last In First Out)的原理运作。

Call Stack 是如何运作的让我们看看下面的代码:

它的执行结果是:
c
b
a
该代码执行过程经历了两个阶段 首先是执行入栈。
执行 a() 方法后,此时 a 就被添加到调用栈的顶部。

在 a 内部调用了 b(),此时的调用栈顶部添加了 b:

同样 b 内部调用了 c(),此时的调用栈顶部添加了 c,最终的调用栈变成了:

此时 console.log('c'); 首先被执行。
当执行完 c 后,调用并不就此完成,开始第二阶段的出栈:

b 方法重新获得了线程控制, 执行了 console.log('b'); 。
b 执行完成,栈退到 a 方法上:

执行 console.log('a'); 。
最后调用完成,调用栈 emptied。

调用栈的大小由于操作系统对每组线程的栈内存有一定的限制,为适应线程各种操作系统,所以 Node.js 默认的栈大小为 984k。
Slightly less than 1MB, since Windows' default stack size for the main execution thread is 1MB for both 32 and 64-bit. @src/globals.h:108:1
如何获取当前环境的调用栈大小?

不过,由于不同版本的 Node 集成的 V8 版本和优化等不同,即使同样 size 的栈空间,调用栈的栈深浅各不相同,我们尝试使用递归函数来测试一下每个版本的 Node.js 环境的可用栈深情况。

computeMaxCallStackSize 15705
computeMaxCallStackSize 15700
computeMaxCallStackSize 15718
computeMaxCallStackSize 15674
从执行结果看,虽然各个版本的调用栈空间默认都是 984kB,从 4.8.3、5.12.0 和 6.10.2 数个版本栈深度大约在 15700 以上,而 7.9.0 版的深度则为 15674。
从实际使用上看,这样的栈深表示一个线程上执行函数的调用栈可达到 15700 层,除非代码中出现"死循环"等情况,对于日常的运算基本是不会有任何问题。
但需要注意的是,调用栈的深度要根据当前调用函数的函数体大小和 local 变量的多少来决定,假如调用栈需要保存的本地变量数量较多,则需要占用较多栈空间来放置这些变量指针,那么栈深度就将远小于该值。
如果需要修改栈的大小,可以通过以下指令增加其大小:

V8 的调用栈优化V8 为提高 JavaScript code 的运行性能,从一开始就采取激进的基于机器码编码方案,那么 V8 在处理调用栈的问题上,是否又有进行了优化呢?
我们对以上的代码进行修改,尝试对同一段代码进行 10 次重复执行。
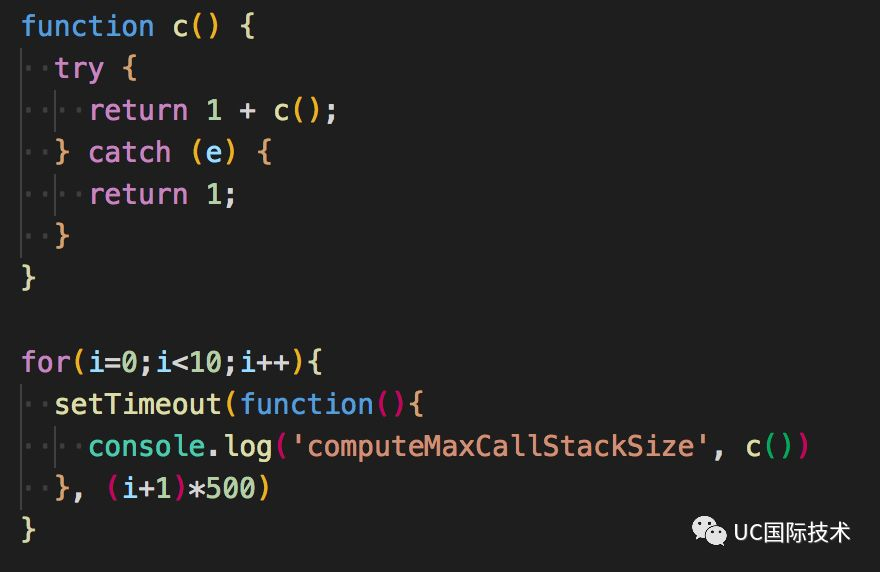
各个版本下,我们看到输出的数据:
node v4.8.3 (v8@4.5.103.47)
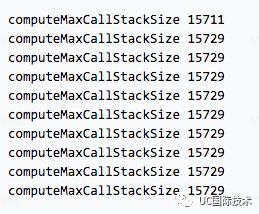
node v5.12.0 (v8@4.6.85.32)
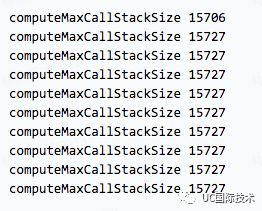
node v6.10.2 (v8@5.1.281.98)
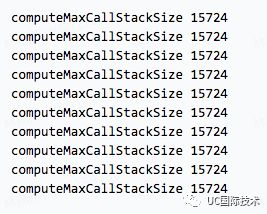
node v7.9.2 (v8@5.5.372.43)
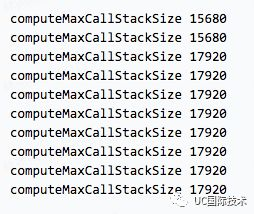
实验的结果,在栈大小不变的情况下,代码被重复执行 2、3 遍后,栈的深度会增加(但 6.10.2 除外,比较诡异),可以理解为栈的内存得到了优化。在而 7.9.2 的版本,运行了两次后,栈的深度更大幅增加 14.28%。
根据 V8 的优化机制,当程序进入 V8 VM 环境后,代码会首先进行简单编译(Full Compliler),这个过程为 gencode,生成机器码并后才开始执行,而 Crankshaft 的优化编译机制并不会被启动,因为此阶段对于编译器来说,看到的只是代码,还无法分析出这些代码哪部分需要优化的。
每个经过 FC 编译的函数都会包含一个计数器,当函数返回或完成一轮循环的时候,就会减少计数的值, 分析器在计数减到 0 的时候,内置性能分析器就可以挑选这类的热点函数,并启动 Crankshaft(优化编译)对其进一步的优化处理,指向其代码的指针就会被改写指向为一个 V8 内置的函数——Lazy Recompile,这样函数再次被调用时将执行经过优化的函数代码。(笔者认为:同时堆栈上的空间上用于存储的函数将被替换,指针指向了栈外的某个堆内存上,节省了栈空间的占用)。
总结Call Stack(调用栈)实际上就是用于存储函数的一种内存数据,而且遵循 LIFO 原理实现的进栈和出栈等一系列操作。栈的大小受到操作系统的限制,一般会少于 1MB 的空间,能使用的回调栈层数受制于栈中每个栈函数的内部变量数量等不同,调用栈的深浅也不一样。
从我们的开发层面看,代码的执行和栈深一般都是有限的,所以默认的情况下代码都不会出现调用栈溢出异常的问题发生。
在了解调用栈的工作原理,及调用栈在各个版本上的运行表现后,其实我们应该思考一下,假设我需要设计一个类似 process.nextTick() 或者 co.next() 这样的函数时,应该如何设计函数方法体,让该函数的代码既有效率地执行同时又能被系统做优化处理,而什么样的代码不行的问题。
“UC国际技术”致力于与你共享高质量的技术文章
欢迎关注我们的公众号、将文章分享给你的好友

