

背景介绍
相信凡是关注容器生态圈的人都不会否认,Kubernetes 已经成为容器编排调度的实际标准,不论 Docker 官方还是 Mesos 都已经支持了 Kubernetes。Spark 从2.3.0版本开始,也开始支持将任务提交至 Kubernetes 上进行计算。目前,Kylin Master 分支上的 Spark 版本也已经更新至了2.3.2,因此我决定尝试一下将 Kylin 的 Spark 任务提交至 Kubernetes 上进行计算,以验证 Kylin Spark Cubing on Kubernetes 的可行性。
什么是Kubernetes?
那么什么是 Kubernetes 呢?Kubernetes,简称K8s,是一个由 Google 开源的容器编排工具,用于自动化部署、扩展和管理容器化的应用程序。
Kubernetes 具备完善的集群管理能力,包括多层次的安全防护和准入机制、多租户应用支撑能力、透明的服务注册和服务发现机制、内建负载均衡器、故障发现和自我修复能力、服务滚动升级和在线扩容、可扩展的资源自动调度机制、多粒度的资源配额管理能力。还提供完善的管理工具,涵盖开发、部署测试、运维监控等各个环节。
Kubernetes这个名字源于希腊语,是舵手的意思,所以它的Logo既像一张渔网,又像一个罗盘。有意思的是 Docker 的 Logo 为驮着集装箱在大海上遨游的鲸鱼,Kubernetes 与 Docker 的关系可见一斑。

这里简单的介绍一下 Kubernetes 中的一个重要的概念,叫做 Pod。 Pod 是 Kubernetes 的最小工作单元。每个 Pod 运行着一个或多个容器,Pod 中的容器会作为一个整体被 K8s Master 调度到一个节点上运行。由于 K8s 本身的概念和组件都比较多,因此不在本文详细展开,感兴趣的同学可以查阅官方文档。
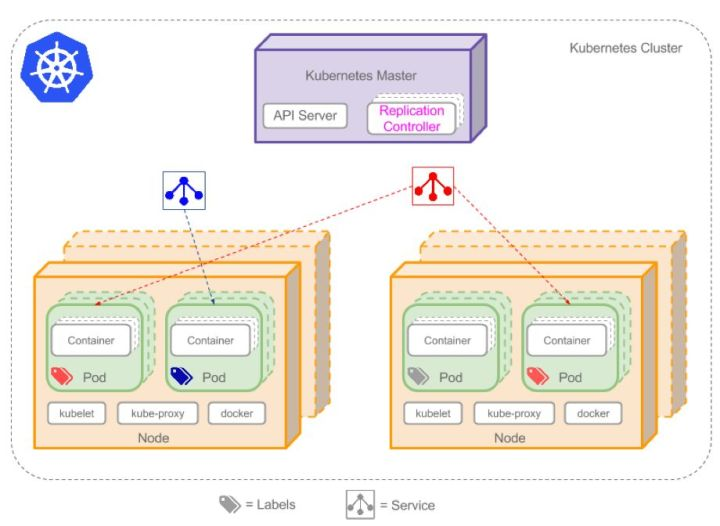
为什么要Spark run on Kubernetes?
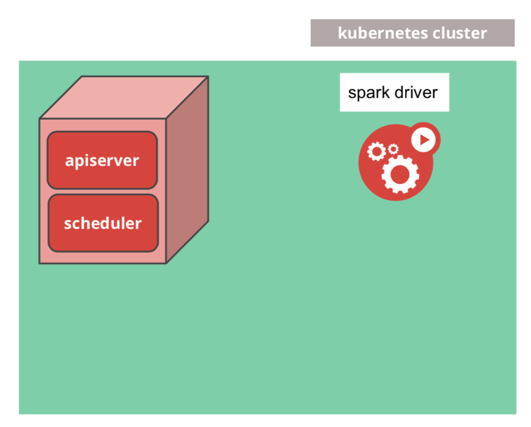
当 Spark run on Kubernetes 时, Kubernetes 的角色是一个集群管理器,就如下图所示。
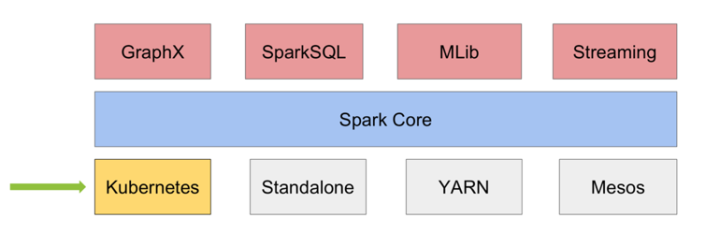
此时,Spark 能够利用 Kubernetes 的生态系统的特性以及所带来的优势。比如,可以直接利用 Kubernetes 的命名空间和资源配额对集群进行多租户设置和共享、可插拔授权和日志记录等管理功能;最重要的是,它不需要在 Kubernetes 集群上进行任何更改或新安装; 只需创建一个容器映像并为您的 Spark 应用程序设置正确的 RBAC角色即可。当您使用 Kubernetes 作为集群管理器时,您将与日志记录和监视解决方案无缝集成。
此外社区还在探索高级用例,例如管理流工作负载和利用服务网格等Istio。
如何将Spark job运行在Kubernetes上?
正确安装并配置 Spark 2.3+、和 Kubernetes(1.7+)。在安装 Kubernetes 的过程中,Docker 会从 Google 官方拉取镜像。Kubernetes 的官方镜像都是托管在 Google 自家的镜像服务上,因为众所周知的原因,在国内直接拉取几乎是不可能的,因此你得先让你的 linux 机器翻墙;还有一种解决方案是使用阿里云容器镜像服务来获取。具体方式不在此赘述,接下来直接介绍如何 run Spark job on Kubernetes。
一、制作镜像
Spark on Kubernetes 的本质是将任务打包放在由 K8s 管理的容器中运行,因此需要将任务打包成Docker image。
Spark 的 bin 目录下提供了docker-image-tool.sh脚本,用来制作 Docker image。该脚本默认会使用$SPARK_HOME/kubernetes/dockerfiles/spark/Dockerfile来构建镜像。以Spark的example程序为例,直接输入命令./bin/docker-image-tool.sh -t botcc -t spark-examplebuild。命令执行完毕后,能在 Docker 下查到这个镜像,说明构建成功,如下图。

现在我们来看一下这个Dockerfile:
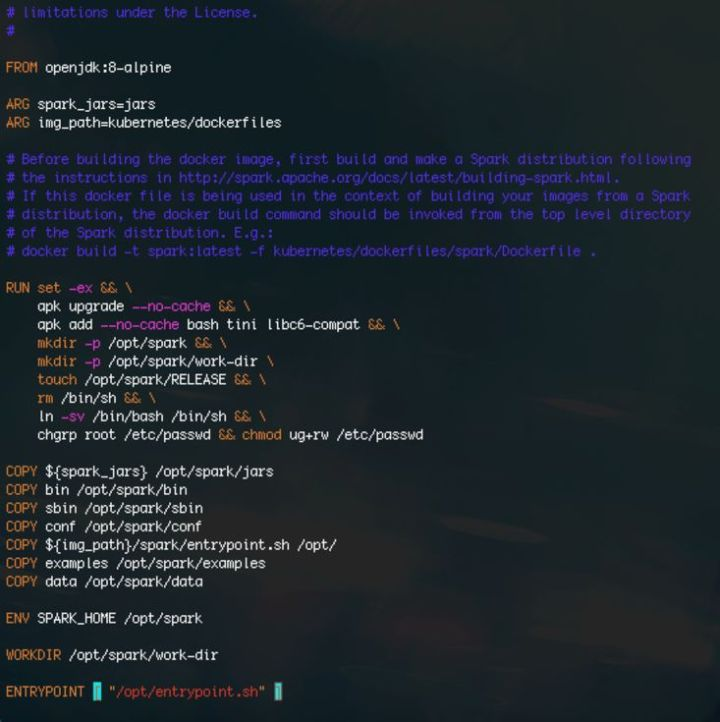
原理很简单,就是将 spark 的运行时环境(jars、bin、conf等)和任务(examples)直接复制到镜像中即可。
二、上传镜像
镜像制作完毕后,使用./bin/docker-image-tool.sh -r botcc -t spark-example push命令推送至 Docker Hub 上。为什么呢?因为将 Spark 任务提交至 Kubernetes 后,Kubernetes 上的各节点会根据 repository name 和 tags 去寻找并下拉该镜像,以此来创建容器执行任务。若不上传,则 K8s 节点会因找不到该 image 而导致任务创建失败,无法执行。
三、提交Spark任务
Spark 向 K8s 提交任务时,命令与向 YARN 上提交相比略有改动,以提交 Spark example 程序中求 PI 值为例:
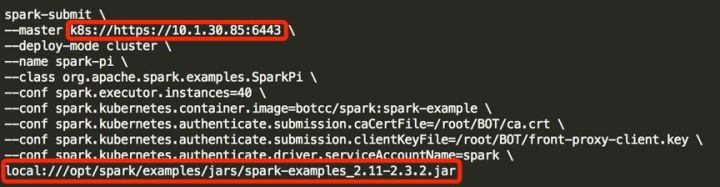
其中主要的改动是--master的参数变成了K8s master的地址;其次是指定依赖的命令变成了local://,local://相当于原先的--jar,但是它指的是容器中的jar包路径,而不是host机器上的路径!除了使用local://方式指定jar包依赖外,Spark还支持使用URL的方式来指定,详情可翻阅官方文档。--name是给spark driver pod进行命名;spark.kubernete.* 则是kubernetes相关的参数,比如权限验证等,这个根据实际情况来配置。任务提交后,查看pods的状态。
当driver pod的STATUS为ContainerCreating状态时,代表K8s的各节点正在拉取指定镜像。

当driver pod的STATUS为Running时,说明K8s的各节点拉取镜像成功,并开始创建executor pods执行计算任务,如下图。
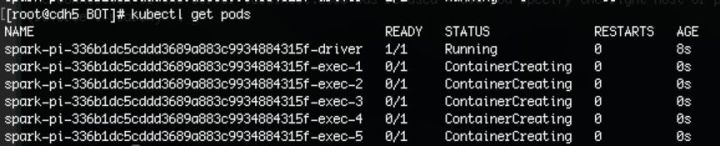
此时你在 K8s 的各节点上执行 Docker images 命令,发现会新增一个名为 botcc/spark:spark-example 的镜像。
当driver pod的STATUS会变成Completed时,此时任务执行成功。
四、工作流
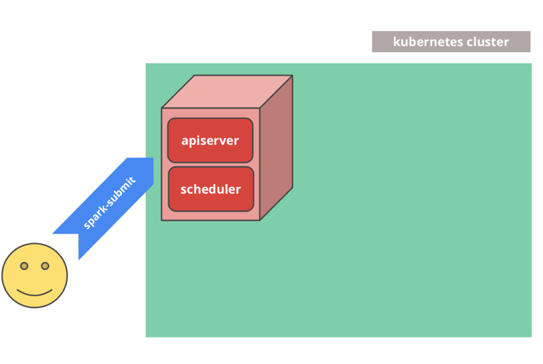
综上,总结一下K8s提交任务后的整个工作流。
一切从用户使用spark-submit命令向K8s集群提交任务开始:
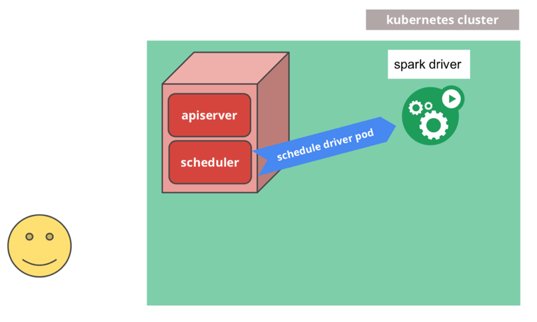
K8s 接收到任务后,scheduler启动一个spark driver pod:
Driver pod会根据需要,向scheduler申请分配若干个executor pods:
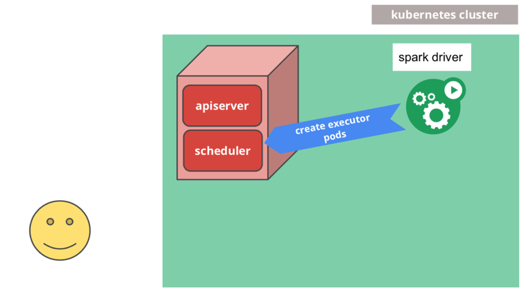
调度器生成executor pods,executor pods执行计算任务:
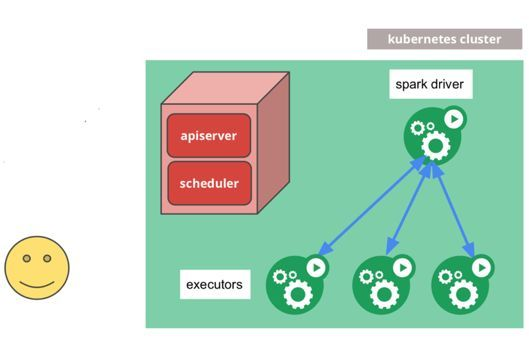
任务执行完成后,executorpods被销毁,资源释放;driver pods保留,并存放了log,直至K8s GC或用户手动删除。
如何将Kylin的Spark job运行在 Kubernetes上?
因为 Kylin Spark Cubing 的本质也是用 spark-submit 将任务提交至 Spark 上进行计算,并将结果写入 HBase。因此根据上述 run Spark examples on K8s 的步骤,我们举一反三,将其移植到 Kylin 的 Spark 任务上,就能实现 Kylin Spark cubing on Kubernetes。
一、添加Hadoop conf
将Hadoop conf的文件添加至$SPARK_HOME/conf目录下,使Spark Job在容器中运行时能够读取到Hadoop的配置信息。默认情况下,./bin/docker-image-tool.sh脚本会将$SPARK_HOME/conf打包进docker images中。
二、添加jar包
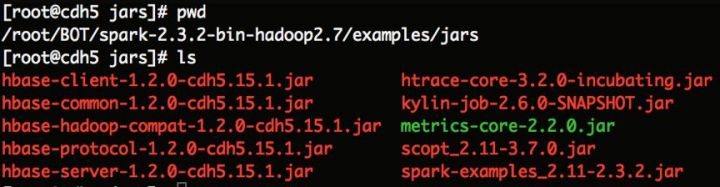
首先要分析Kylin Spark Cubing时,在哪些步骤提交了Spark任务,这些步骤又分别使用了哪些jar包?通过在Kylin Web UI上分析log,我们可以确定在以下三步中,Kylin提交了spark作业,分别为Step 3: Extract Fact Table Distinct Columns, Step 7: Build Cube with Spark, Step8: Convert Cuboid Data to HFile。其中Step 3、Step 7、Step 8都依赖kylin-job-<version>.jar; 除此之外Step8还依赖HBase相关的jar包,以我的集群为例,依赖的有hbase-common-1.2.0-cdh5.15.1.jarhbase-server-1.2.0-cdh5.15.1.jar、hbase-client-1.2.0-cdh5.15.1.jar、hbase-protocol-1.2.0-cdh5.15.1.jar、hbase-hadoop-compat-1.2.0-cdh5.15.1.jar、htrace-core-3.2.0-incubating.jar、metrics-core-2.2.0.jar。
根据上面对Dockerfile的分析以及出于方便起见,将这些jar包复制到$SPARK_HOME/examples/jars目录下(当然路径也可以自由指定,但是需要在Dockerfile做对应的增改),将这些jar包打包至Docker images中。如下图:
三、修改EntryPoint.sh(可选)
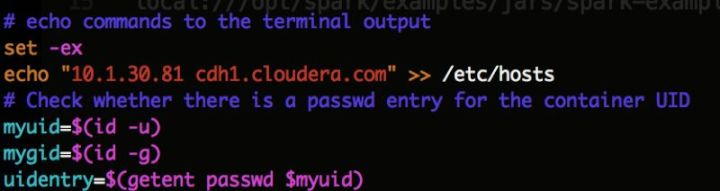
修改 $SPARK_HOME/kubernetes/dockerfiles/spark/entrypoint.sh脚本,新增Hadoop的hosts,如下图。该步骤的目的是,在提交任务时可以用hostname代替ip地址。
四、修改kylin.properties配置文件
正如 Kylin 官网上所说的,“所有使用“kylin.engine.spark-conf.”作为前缀的 Spark 配置属性都能在$KYLIN_HOME/conf/kylin.properties 中进行管理”。因此把原先有关YARN相关的配置都注释掉,并加上spark.kubernetes相关的配置,如下图所示。
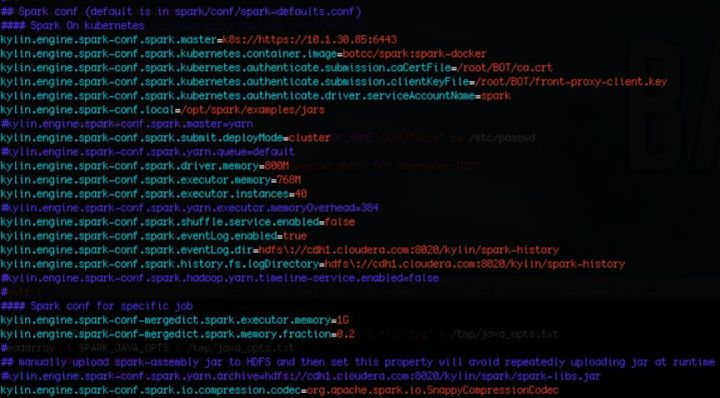
其中 kylin.engine.spark-conf.local是我自定义的一个参数,用以指定容器中所依赖的jar包的home path。
五、微改Kylin代码
我们先对比一下Kylin提交Spark任务on YARN和on K8s之间的区别:
Spark on YARN:
export HADOOP_CONF_DIR=/etc/hadoop/conf && /root/apache-kylin-version-SNAPSHOT-bin/spark/bin/spark-submit --class org.apache.kylin.common.util.SparkEntry
--conf spark.master=yarn
--conf spark.submit.deployMode=cluster
--conf spark.executor.instances=40
--conf spark.yarn.archive=hdfs://cdh1.cloudera.com:8020/kylin/spark/spark-libs.jar
--conf spark.yarn.queue=default
--conf spark.history.fs.logDirectory=hdfs://cdh1.cloudera.com:8020/kylin/spark-history
--conf spark.io.compression.codec=org.apache.spark.io.SnappyCompressionCodec
--conf spark.hadoop.yarn.timeline-service.enabled=false
--conf spark.executor.memory=768M
--conf spark.eventLog.enabled=true
--conf spark.eventLog.dir=hdfs://cdh1.cloudera.com:8020/kylin/spark-history
--conf spark.yarn.executor.memoryOverhead=384
--conf spark.driver.memory=800M
--conf spark.shuffle.service.enabled=true
--jars /root/apache-kylin-version-SNAPSHOT-bin/lib/kylin-job-version-SNAPSHOT.jar, /root/apache-kylin-version-SNAPSHOT-bin/lib/kylin-job-version-SNAPSHOT.jar
-className org.apache.kylin.engine.spark.SparkFactDistinct
……
Spark on K8s:
export HADOOP_CONF_DIR=/etc/hadoop/conf && /root/apache-kylin-version-SNAPSHOT-bin/spark/bin/spark-submit --class org.apache.kylin.common.util.SparkEntry
--name kylin-spark
--master k8s://https://10.1.30.85:6443
--deploy-mode cluster
--conf spark.kubernetes.container.image=botcc/spark:spark-docker
--conf spark.kubernetes.authenticate.submission.caCertFile=/root/BOT/ca.crt
--conf spark.kubernetes.authenticate.submission.clientKeyFile=/root/BOT/front-proxy-client.key
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark
--conf spark.executor.instances=40
--conf spark.history.fs.logDirectory=hdfs://cdh1.cloudera.com:8020/kylin/spark-history
--conf spark.io.compression.codec=org.apache.spark.io.SnappyCompressionCodec
--conf spark.executor.memory=768M
--conf spark.eventLog.enabled=true
--conf spark.eventLog.dir=hdfs://cdh1.cloudera.com:8020/kylin/spark-history
--conf spark.driver.memory=800M
--conf spark.shuffle.service.enabled=true
local:///opt/spark/examples/jars/kylin-job-version-SNAPSHOT.jar,local:///opt/spark/examples/jars/kylin-job-version-SNAPSHOT.jar
-className org.apache.kylin.engine.spark.SparkFactDistinct
……
因此,很自然而然地得出修改思路: 获取配置文件中的master类型,根据master的类型来生成对应格式的Spark参数;如果是提交至K8s,则生成K8s格式的命令;若提交至YARN,则生成YARN格式的命令。提交Spark任务的命令是在SparkExecutable.dowork()方法中生成的,因此在该方法下进行修改。其中,关键代码如下:
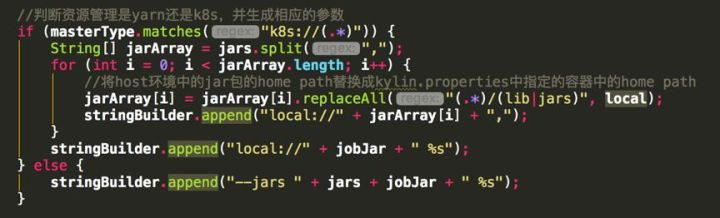
备注:由于此次是“初探”,因此我新建了一个分支,用来进行代码修改和功能验证。待日后功能完善后,再申请PR合入master。
六、效果演示
Step 3时,pod成功创建并运行:
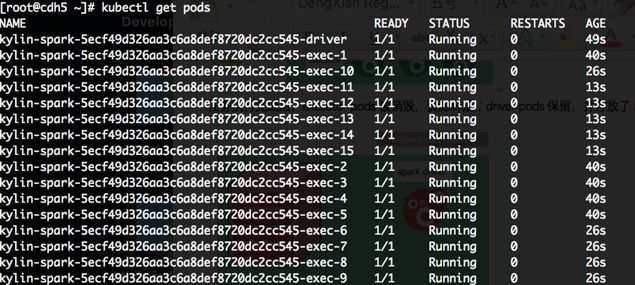
Step7、Step 8同样也能成功创建并运行 Pod。
最终,三个Step全部执行成功:


执行一个测试查询语句,能够成功查出数据:
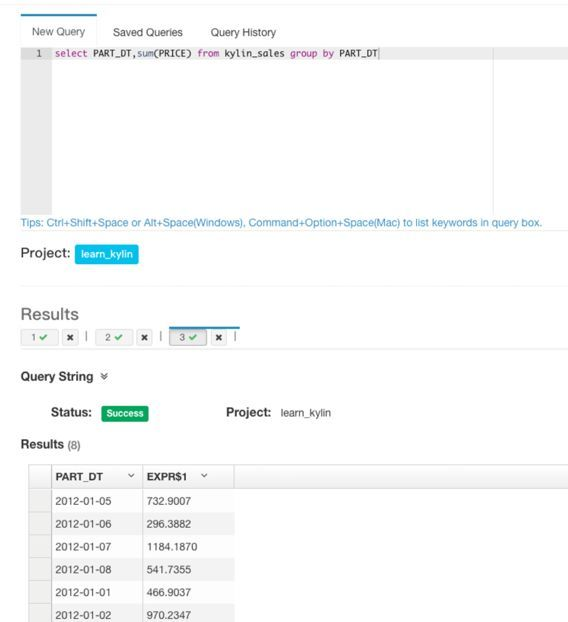
总结
通过实验验证,Apache Kylin 的 Spark 任务引擎,是可以完全运行在 Kubenetes 集群上的,从而将 Kubenetes 的各种益处完全赋予Kylin用户。目前 Spark on Kubernetes 还有一些有待提高的地方,例如尚不支持 external shuffle service、添加jar包依赖比较麻烦、不支持对容器中的 Spark 任务进行管理等;Spark 社区也在持续不断地改进 Spark on Kubernetes 方案,相信在不远的将来这些问题都会被解决。
目前很多企业已经或者开始将各类服务往 Kubernetes 集群上迁移,例如京东、eBay、Google等,这是未来的趋势,我们会持续对其进行关注。
参考:
作者简介
曹礼俊,开源软件、大数据、IoT爱好者;现就职于 Kyligence, 参与 Kylin 等项目的研究和开发工作。
