

项目仓库
- 项目地址: github.com/sunhailin-L…
- 开发者: sunhailin-Leo
项目简介
-
爬虫的核心代码就移步去Github仓库上看吧~
-
项目功能简介:
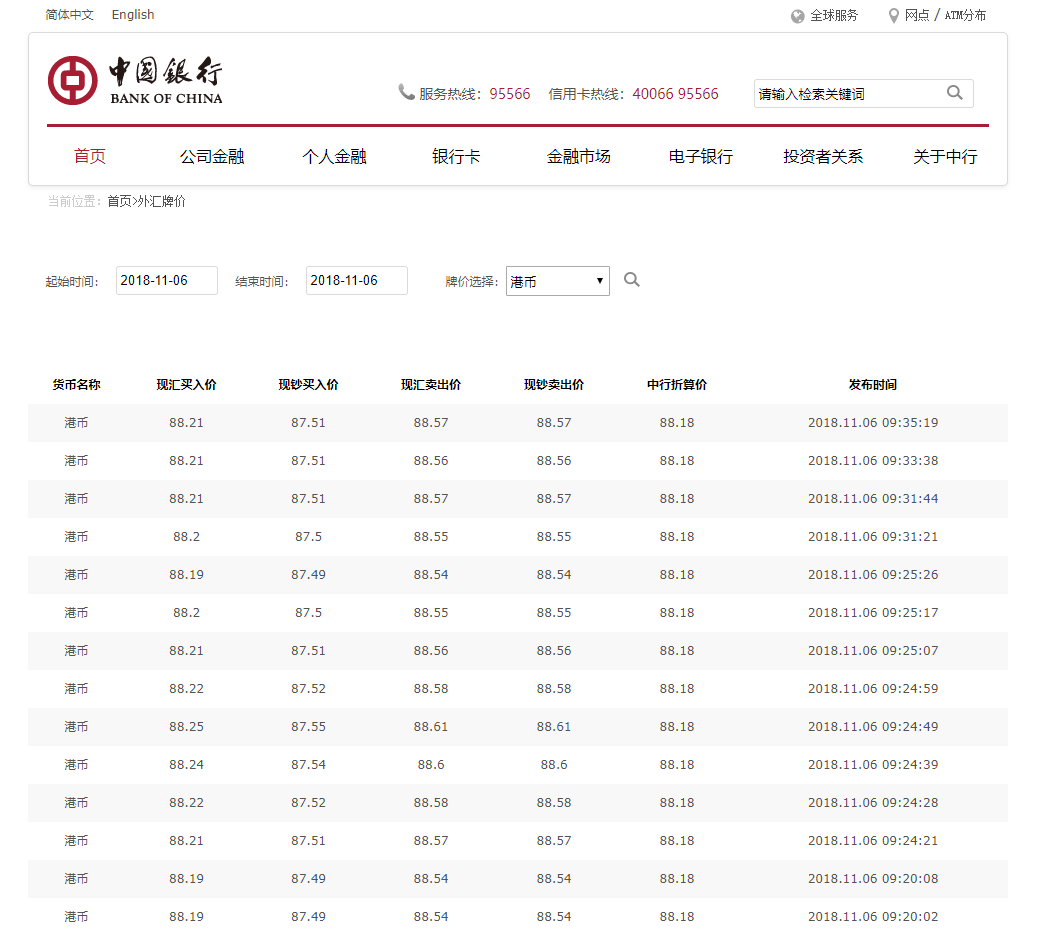
- 获取中国银行外汇牌价的汇率(本项目模板以港币为Base)
- 获取时间可以自定义(设置起始时间不建议跨度太长)
- 爬虫数据支持存储在MySQL、MongoDB和CSV中(通过cmdline_start_spider的启动命令参数进行控制)
- 更新了增量爬取模式(2018-11-12日)
-
爬取目的:
- 纯属一片好奇心想去预测未来的几天的汇率走向
- 顺便做一做可视化
-
项目技术点:
- Scrapy获取源代码解析数据

* 由于页码是通过JS进行加载的,所以暂时解决办法用selenium无头模式进行渲染(后期改为用Scrapy-splash)
讲讲数据方面
- 以下数据使用的是 2018-01-01 ~ 2018-11-06日的汇率数据(去重之后约48000条数据)
- 数据探索:
- 中行网站上有四种不同的牌价(现汇买入价,现钞买入价,现汇卖出价,现钞卖出价,中行折算价), 中行折算价暂时先不考虑。
- 现汇买入价——是指账户内的外汇通过结汇兑换成人民币的银行结算价。
- 现钞买入价——是指外币现钞结汇,兑换成人民币的银行结算价。
- 现汇卖出价——是指购买外汇对外付款,人民币兑换外币的银行结算价。
- 现钞卖出价——是指购买外币现钞,人民币兑换外币的银行结算价。
- 要考虑去香港买买买的话就可以用现汇卖出价或者现钞卖出价进行数据可视化和数据预测了。
- 本人选择了现汇卖出价, 接下来的数据都是用现汇卖出价进行可视化并统计分析了(其他类型只是换了列数据而已)
- 中行网站上有四种不同的牌价(现汇买入价,现钞买入价,现汇卖出价,现钞卖出价,中行折算价), 中行折算价暂时先不考虑。
- 数据清洗:
-
在页面上看或者从抓取回来的数据很容易看出会有部分重复数据(不知道中行为啥允许重复数据的出现)
-
清洗手段:(我选择了后者,在不给数据库施压的情况下,后者相对比较仁慈)
- MySQL:SELECT DISTINCT语句
- Pandas: Dataframe.drop_duplicates(根据发布时间保留第一个值就ok了)
-
代码大致如下:
header = ['现汇买入价', '现钞买入价', '现汇卖出价', '现钞卖出价', '中行折算价', '查询时间'] # dataframe配置 # 显示所有列 pd.set_option('display.max_columns', None) # 显示所有行 # pd.set_option('display.max_rows', None) # 设置value的显示长度为100,默认为50 pd.set_option('max_colwidth', 100) # 从MySQL中获取数据并重置表头 sql = "SELECT buying_rate, cash_buying_rate, selling_rate, cash_selling_rate, boe_conversion_rate, rate_time " \ "FROM exchange_rate.t_exchange_rate " \ "WHERE currency_name = '港币'" df = pd.read_sql(sql=sql, con=sql_conn()) df.columns = header df = df.sort_values(by='查询时间') # 转换数据类型 df['现汇买入价'] = df['现汇买入价'].astype('float') df['现钞买入价'] = df['现钞买入价'].astype('float') df['现汇卖出价'] = df['现汇卖出价'].astype('float') df['现钞卖出价'] = df['现钞卖出价'].astype('float') df['中行折算价'] = df['中行折算价'].astype('float') # 去重 df = df.drop_duplicates(subset='查询时间', keep='first') print(df[['现汇卖出价', '查询时间']]) -
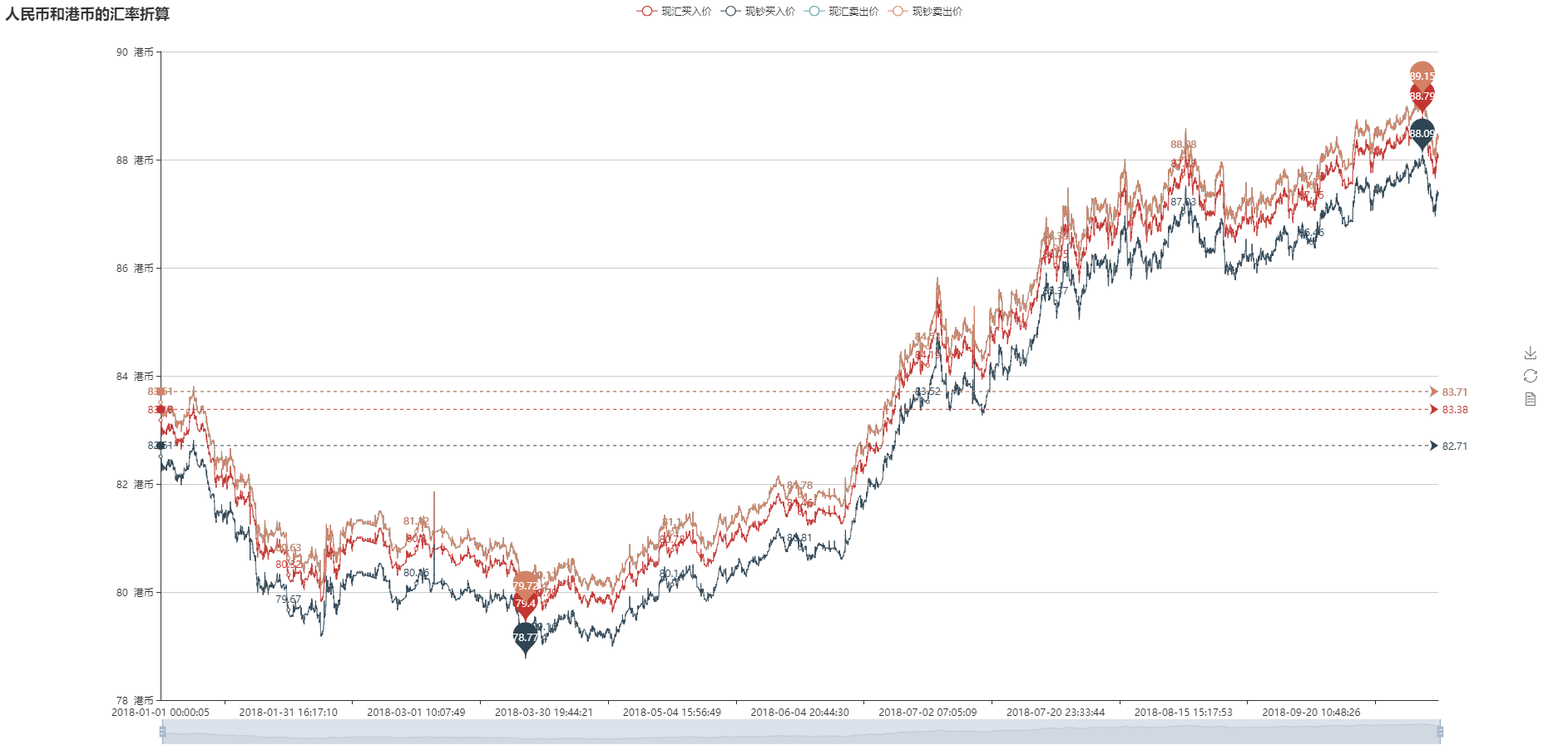
- 数据可视化(折线图和K线图)
- 以下代码均为部分代码使用的库(Pandas, pyecharts)
- 折线图
# 折线图数据
total_data = [
df['现汇买入价'].tolist(), df['现钞买入价'].tolist(), df['现汇卖出价'].tolist(), df['现钞卖出价'].tolist()
]
draw_line_pic(
title="人民币和港币的汇率折算(100港币)",
labels=header[0:4],
data_package=total_data,
x_axis=df['查询时间'].tolist()
)
def draw_line_pic(title: str, labels: list, data_package: list, x_axis: list):
"""
折线图
:param title:
:param labels:
:param data_package:
:param x_axis:
:return:
"""
style = Style(
title_top="#fff",
title_pos="left",
width=1920,
height=900
)
line = Line(title=title, **style.init_style)
for i, d in enumerate(labels):
line.add(d, x_axis, data_package[i],
is_stack=False,
is_label_show=True,
is_smooth=True,
yaxis_min=78,
yaxis_max=90,
yaxis_formatter="元人民币",
mark_point=["max", "min"],
mark_line=['average'],
is_datazoom_show=True,
datazoom_type="both",
datazoom_range=[80, 100])
line.render(path='./file/line.html')
- 画图结果如下:
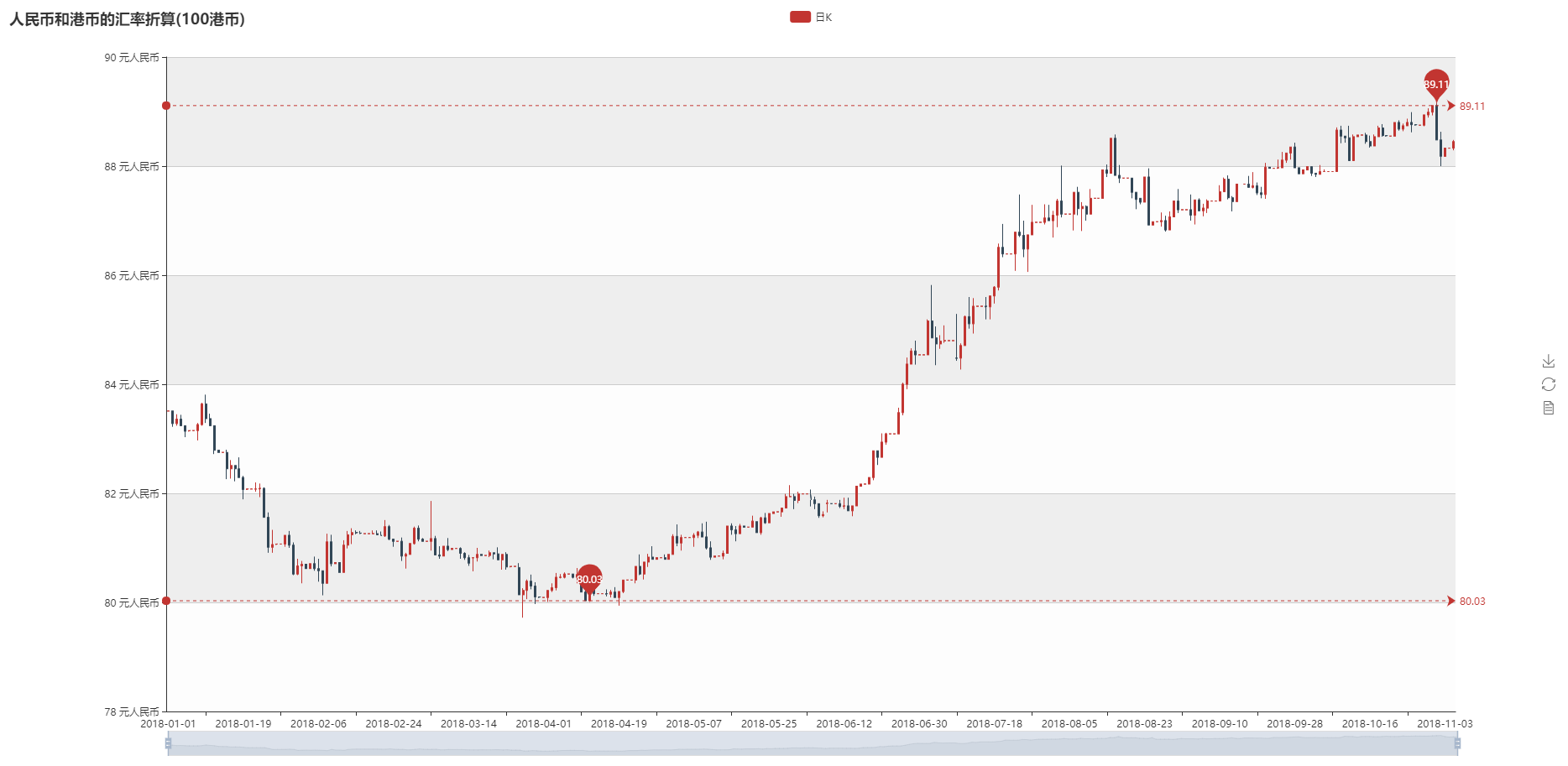
- K线图
- 数据注明: 使用了现汇卖出价,根据数据进行groupby求每日的均值进行可视化
# K线图数据
df['查询时间'] = df['查询时间'].apply(lambda x: x[:-9])
df['查询时间'] = pd.to_datetime(df['查询时间'], format="%Y-%m-%d")
df = df.groupby('查询时间')['现汇卖出价']
labels = []
values = []
for d in df:
temp_data = d[1].tolist()
k_data = [temp_data[0], temp_data[-1], min(temp_data), max(temp_data)]
labels.append(str(d[0])[:-9])
values.append(k_data)
draw_kline_pic(title="人民币和港币的汇率折算(100港币)", labels=labels, data_package=values)
def draw_kline_pic(title: str, labels: list, data_package: list):
"""
K线图
:param title:
:param labels:
:param data_package:
:return:
"""
style = Style(
title_top="#fff",
title_pos="left",
width=1920,
height=900
)
kline = Kline(title=title, **style.init_style)
kline.add('日K', labels, data_package,
yaxis_min=78,
yaxis_max=90,
yaxis_formatter="元人民币",
mark_line=["min", "max"],
mark_point=["min", "max"],
is_datazoom_show=True,
datazoom_type="both",
datazoom_range=[80, 100])
kline.render('./file/k_line.html')
- 画图结果如下:
-
开始预测
- 预测之前各位同学可以先去了解下ARIMA模型(自回归积分滑动平均模型)
- 这部分没什么代码(时序分析的步骤实在太长了,要考虑周期性、自相关性、反自相关性 balabala的~), 那段太凌乱了就没有贴出来了,自己上一个代码 (用的库是pyflux)
def model_training_1(df: pd.DataFrame):
df['查询时间'] = df['查询时间'].apply(lambda x: x[:-9])
df['查询时间'] = pd.to_datetime(df['查询时间'], format="%Y-%m-%d")
df = df.groupby('查询时间')['现汇卖出价'].mean()
df = df.to_frame()
print(df)
# ARIMA
model = pf.ARIMA(data=df, ar=2, ma=2, integ=0, target='现汇卖出价', family=pf.Normal())
x = model.fit("MLE")
x.summary()
model.plot_z(figsize=(15, 5))
model.plot_fit(figsize=(15, 10))
model.plot_predict_is(h=50, figsize=(15, 5))
model.plot_predict(h=2, past_values=50, figsize=(15, 5))
res = model.predict(h=5)
print(res)
- 先看拟合图也就是plot_fit的图
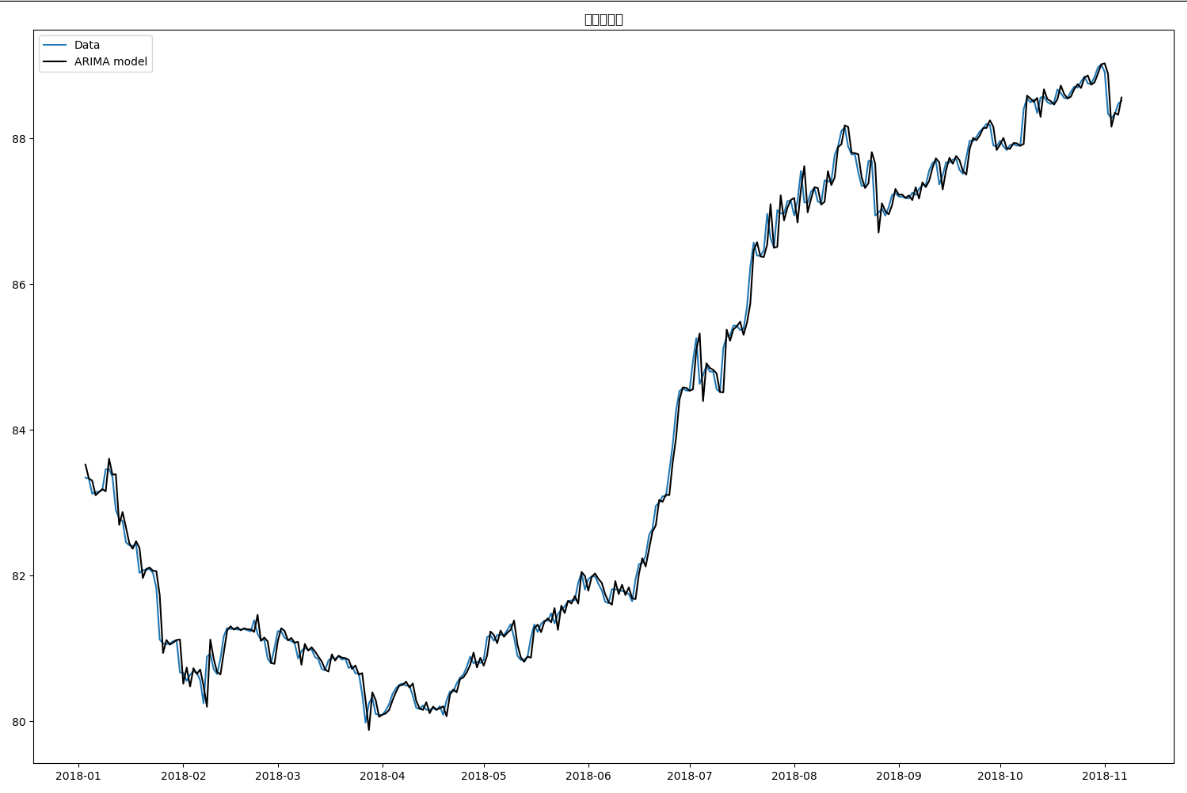
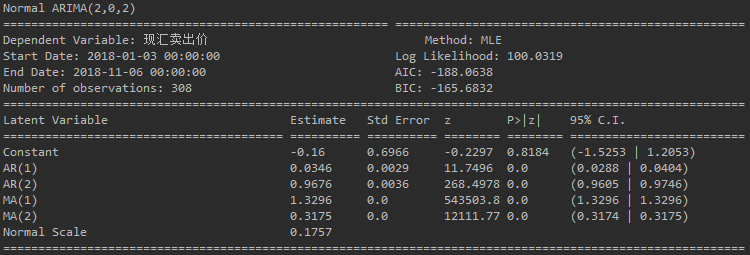
- 再看模型验证参数
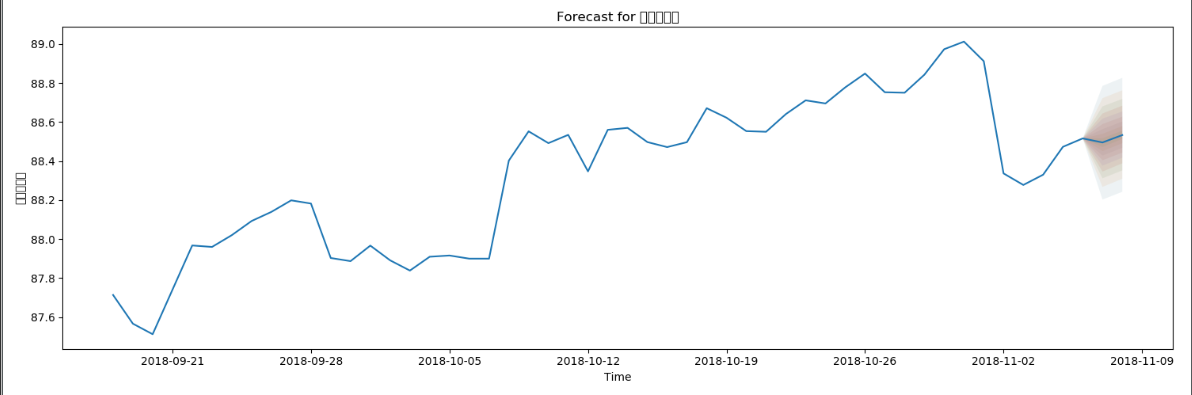
- 预测图(用过去50天数据进行预测后几天的数据)
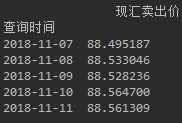
- 预测结果
-
数据校验
- 校验这块暂时还没时间去做,但是看到拟合程度还是很可观的就懒了~
- 有空还是会补上的~
-
题外话
- Pyflux仓库地址: github.com/RJT1990/pyf…
- Pyflux这个库是一个专门做时间序列数据分析的库,很可惜的是他的官网挂了,太久没有维护了
- 原来这开源项目还有个很酷炫的官网, 官网上还有example + 图片现在只剩下git doc了.
- 参考文档: pyflux.readthedocs.io/en/latest/g…
- 注: 文档里头的图基本都没有了,只有剩下公式和代码块,暂且将就着用吧。如果对时序分析预测感兴趣的同学可以考虑用一下statsmodels这个统计学的库,这个文档和工具就比较丰富和科学。
未来开发方向
- 想往哪就往哪~Peace!
