

转载请注明出处 leonchen1024.com/2018/08/14/…
二分搜索(binary search),也叫做 折半搜索(half-interval search),对数搜索(logarithmic search),对半搜索(binary chop),是一种在有序数组中查找某一特定元素的搜索算法.
二分搜索有几个变体.特别是,分散层叠(fractional cascading)(将每个数组里的值集合成一个数组,元素为11[0,3,2,0] 的形式,括号内的数字是该值在对应数组中应该返回的数字)提高了在多个数组中查找相同值的效率,高效的解决了一系列计算几何和其他领域的查找问题).指数查找(Exponential search)延伸了二分查找到一个没有边界的 list.binary search tree和B-tree是基于 binary search 延伸的.
原理
搜索时从数组中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果中间元素大于或者小于要查找的元素,则在数组中大于或者小于查找元素的一半中继续查找,重复这个过程直到找到这个元素,或者这一半的大小为空时则代表找不到.这样子每一次比较都使得搜索范围缩小一半.
步骤
给定一个有序数组 A 是 A0,...,An-1并保证 A0<=...<=An-1,以及目标值 T.
- 令 L 为0,R 为 n-1.
- 如果 L>R 则搜索失败
- 令m(中间值元素索引)为最大的小于(L+R)/2的整数
- 如果 Am<T ,令 L=m+1并回到第2步;
- 如果 Am>T ,令 R=m-1并回到第2步;
- 当 Am=T,搜索结束;T 所在的索引位置为m.
变体
- 令 L 为0,R 为 n-1.
- 令 m(中间元素索引) 为上限,也就是最小的大于(L+R)/2的值.
- 如果 Am>T ,设置 R 为 m-1并且返回第2步
- 如果 Am<=T ,设置 L 为m 并且返回第2步.
- 直到 L=R ,搜索完成.这时候如果T=Am,返回 m,否则,搜索失败.
转载请注明出处 leonchen1024.com/2018/08/14/…
在 Am<=T 的时候,这个变体将 L 设置为 m 而不是 m+1.这个方式的比较是更快速的,因为它在每个循环里省略了一次比较.但是平均就会多出来一次循环.在数组包含重复的元素的时候这个变体总是会返回最右侧的元素索引.比如 A 是[1,2,3,4,4,5,6,7]查找的对象是4,那么这个方法会返回 index 4,而不是 index 3.
大致匹配
由于有序数组的顺序性,可以将二分搜索扩展到大致匹配.可以用来计算赋值的排名(或称秩,比它更小的元素的数量),前趋(下一个最小元素),后继(下一个最大元素)以及最近邻.还可以使用两个排名查询来执行范围查询.
- 排名查询可以使用调整后的二分搜索来进行.成功时返回m,失败时返回 L, 这样就等于返回了比目标值小的元素数目.
- 前趋和后继可以使用排名查询来进行.当知道目标值的排名,成功时前趋是排名位置的上一个元素,失败时则是排名位置的元素.它的后继是排名位置的后一个元素,或是前趋的下一个元素.目标值的最近领可能是前趋或后继,取决于哪个更接近目标值.
- 范围查询,一旦知道范围两边的值的排名,那么大于边界最小值且小于边界最大值的元素排名就是他们的范围,是否包含边界值根据需要处理.
性能分析
时间复杂度 二分查找每次把搜索区域减少一半,时间复杂度为
(n 是集合中元素的个数)
最差的情况是 遍历到最后一层,或者是没有找到该元素的时候,复杂度为 .
综合复杂度为
分散层叠(fractional cascading) 可以提高在多数组中查询相同值的效率. k 是数组的数量,在每个数组中查询目标值消耗 的时间.分散层叠可以将它降低到
.
变体效率分析
相对于正常的二分搜索,它减少了每次循环的比对次数,但是它必须做完完整的循环,而不会在中间就得到答案.但是在 n 很大的情况下减少了对比次数的提升不能够抵消多余的循环的消耗.
转载请注明出处 leonchen1024.com/2018/08/14/…
空间复杂度 O(1).尾递归,可以改写为循环.
应用
查找数组中的元素,或用于插入排序.
二分搜索和其他的方案对比
使用二分搜索的有序数组在插入和删除操作效率很低,每个操作消耗 O(n) 的时间.其他的数据结构提供了更高效的插入和删除,并且提供了同样高效的完全匹配.然而,二分搜索适用于很多的搜索问题,只消耗 的时间.
Hashing
对于关联数组 (associative arrays),哈希表 (hash tables),他们是通过hash 函数将键映射到记录上的数据结构,通常情况下比在有序数组的情况下使用二分查找要更快.大部分的实现平均开销都是常量级的.然而, hashing 并不适用于模糊匹配,比如计算前趋,后继,以及最近的键,它在失败的查询情况下能给我们的唯一信息就是目标在记录中不存在.二分查找是这种匹配的理想模式,消耗对数级别的时间.
Trees
二叉搜索树(binary search tree) 是一个基于二叉搜索原理的二叉树(binary tree)数据结构.树的记录按照顺序排列,并且每个树里的每个记录都可以使用类似二叉搜索的方法来搜索,平均耗费对数级的时间.插入和删除的平均时间也是对数级的.这会比有序数组消耗的线性时间要快,并且二叉树拥有所有有序数组可以执行的操作,包含范围和模糊查找.
然而二叉搜索通常情况下比二叉搜索树的搜索更有效率,因为二叉搜索树很可能会完全不平衡,导致性能稍差.这同样适用于 平衡二叉搜索树( balanced binary search trees) , 它平衡了它自己的节点稍微向完全平衡树靠拢.虽然不太可能,但是树有可能只有少数节点有两个子节点导致严重不平衡,这种情况下平均时间损耗和最差的情况差不多都是 O(n) .二叉搜索树比有序数组占用更多的空间.
二叉搜索树因为可以高效的在文件系统中结构化,所以他们可以在硬盘中进行快速搜索.B-tree 泛化了这种树结构的方法.B-tree 常用于组织长时间的存储比如数据库(databases)和文件系统(filesystems).
Linear search
线性搜索( Linear Search)是一种简单的搜索算法,它查找每一个记录直到找到目标值.线性搜索可以在 链表(linked list) 上使用,它的插入和删除会比在数组上要快.二分搜索比线性搜索要快除非数组很短.如果数组必须先被排序,这个消耗必须在搜索中平摊.对数组进行排序还可以进行有效的近似匹配和其他操作.
Set membership algorithms
一个和搜索相关的问题是集合成员(set membership).所有有关查找的算法,比如二分搜索,都可以用于集合成员.还有一些更适用于集合成员的算法,位数组(bit array)是最简单的一个,在键的范围是有限的时候非常有用.它非常快,是需要O(1)的时间.朱迪矩阵(Judy array)可以高效的处理64位键.
对于近似结果,布隆过滤器(Bloom filters)是另外一个基于哈希的概率性数据结构,通过存储使用bit array 和多重 hash 函数编码的键集合. Bloom filters 在大多数情况下空间效率比bit arrays 要高而不会慢太多:使用了 k 重hash 函数,成员查找只需要 O(k) 的时间.然而, Bloom filters 有一定的误判性.
其他的数据结构
转载请注明出处 leonchen1024.com/2018/08/14/…
这里存在一些数据结构在某些情况下比在有序数组上使用二分搜索进行查找或其他的操作更加高效.比如,在van Emde Boas trees, fusion trees, 前缀树(tries), 和位数组 上进行查找,近似匹配,以及其他可用的操作可以比在有序数组上进行二分搜索更加的高效.然而,尽管这些操作可以比在无视键的情况下比有序数组上使用更高效,这样的数据结构通常是因为利用了某些键的属性(键通常是一些小整数),因此如果键缺乏那些属性将会消耗更多的空间或时间.一些结构如朱迪矩阵,使用了多种方式的组合来保证效率和执行近似匹配的能力.
变体
Uniform binary search
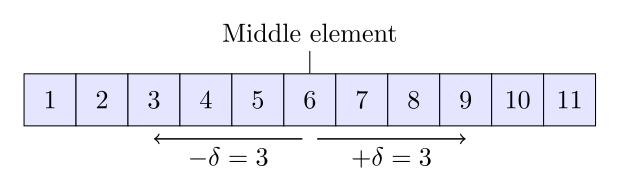
Uniform binary search 不是存储下限和上限的边界值,而是中间元素的索引,和从这次循环的中间元素到下次循环的中间元素的变化.每一步的变化减少一半.比如,要搜索的数组是[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11],中间元素是6.Uniform binary search 同时对左边和右边的子数组进行操作.在这个情况下,左边的子数组([1, 2, 3, 4, 5]) 的中间元素 3 而右边的子数组 ([7, 8, 9, 10, 11]) 的中间元素是 9.然后存储3 作为两个中间元素和 6 的差别.为了减少搜索的空间使用,算法同时加上或减去这个和中间元素的改变.这个算法的好处是可以将每次循环的索引的差别存储到一个表里,在某些系统里可以提高算法的性能.
Exponential search
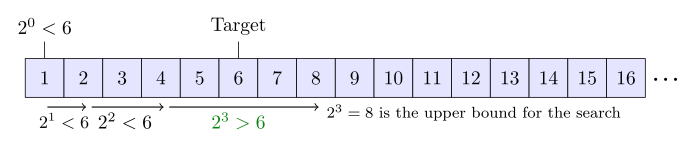
指数查找(Exponential Search)将二分搜索拓展到无边界数组.它最开始寻找第一个索引是2的幂次方并且要比目标值大的元素的索引.然后,它将这个元素索引设置为上边界,然后开始二分搜索.指数查找消耗 次循环 ,然后二分搜索消耗
次循环, x 是目标值的位置.指数查找适用于有界列表,在目标值接近数组开始的位置的时候比二分查找性能有所提高.
转载请注明出处 leonchen1024.com/2018/08/14/…
Interpolation search
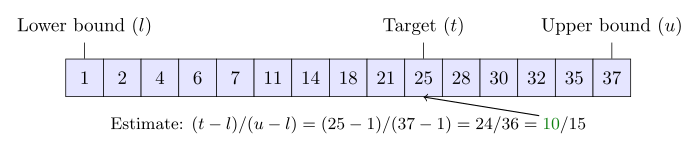
内插搜索(Interpolation search)忽略了目标值的位置,计算数组的最低和最高元素的距离即数组的长度.这只有在数组元素是数字的时候才能使用.它适用于中间值不是最好的猜测选择的情况.比如,如果目标值接近数组的最高元素,最好是定位在数组的末端.如果数组的分布是均匀的或者接近均匀的,它消耗 次比较.
实际上,内插搜索在数组元素较少的情况下是比二分搜索更慢的,因为内插搜索需要额外的计算.尽管它的时间复杂度增长是小于二分搜索的,只有在在大数组的情况下这个计算的损耗可以被弥补.
Fractional cascading
分散层叠(Fractional cascading) 可以提高在多个有序数组里查找相同的元素或近似匹配的效率,分别在每个数组里查找总共需要 的时间, k 是数组的数量.分散层叠通过将每个数组的信息按指定的方式存储起来将这个时间降低到
.
转载请注明出处 leonchen1024.com/2018/08/14/…
它将每个数组里的值集合成一个数组,元素为 11[0,3,2,0] 的形式,括号内的数字是该值在对应数组中应该返回的数字)提高了在多个数组中查找相同值的效率,高效的解决了一系列计算几何和其他领域的查找问题
分散层叠被发明的时候是为了高效的解决各种计算几何学(computational geometry) 问题,但是它同样适用于其他地方,例如 数据挖掘(data mining) 和 互联网协议(Internet Protocal) 等.
实现时的问题
要注意中间值的取值方法,如果使用 (L+R)/2 当数组的元素数量很大的时候回造成计算溢出.所以要使用L+(R-L)/2.
示例
C 版本- 递归
int binary_search(const int arr[], int start , int end , int khey){
if (start > end)
return -1;
int mid = start +(end - start)/2; //直接平均可能会溢位,所以用此算法
if (arr[mid] > khey)
return binary_search(arr , start , mid - 1 , khey);
else if (arr[mid] < khey)
return binary_search(arr , mid + 1 , end , khey);
else
return mid; //最后才检测相等的情况是因为大多数搜寻情况不是大于就是小于
}
C 版本- while 循环
int binary_search(const int arr[], int start, int end, int khey){
int result = -1; //如果没有搜索到数据返回 -1
int mid;
while (start <= end){
mid = start + (end - start)/2 ; //直接平均可能会溢位,所以用此算法
if (arr[mid] > khey)
end = mid-1;
else if (arr[mid] < khey)
start = mid + 1;
else{ //最后才检测相等的情况是因为大多数搜寻情况不是大于就是小于
result = mid;
break;
}
}
return result;
}
Python3 递归
def binary_search(arr, start, end, hkey):
if start > end:
return -1
mid = start + (end - start) / 2
if arr[mid] > hkey:
return binary_search(arr, start , mid - 1,hkey)
if arr[mid] < hkey:
return binary_search(arr, mid + 1, end, hkey)
return mid
Python3 while 循环
def binary_search(arr, start, end, hkey):
result = -1
while start <= end:
mid = start + (end - start) / 2
if arr[mid] > hkey :
end = mid - 1
elif arr[mid] < hkey :
start = mid + 1
else :
result = mid
break
return result
Java 递归
public static int binarySearch(int[] arr, int start, int end, int hkey){
if (start > end)
return -1;
int mid = start + (end - start)/2; //防止溢位
if (arr[mid] > hkey)
return binarySearch(arr, start, mid - 1, hkey);
if (arr[mid] < hkey)
return binarySearch(arr, mid + 1, end, hkey);
return mid;
}
Java while 循环
public static int binarySearch(int[] arr, int start, int end, int hkey){
int result = -1;
while (start <= end){
int mid = start + (end - start)/2; //防止溢位
if (arr[mid] > hkey)
end = mid - 1;
else if (arr[mid] < hkey)
start = mid + 1;
else {
result = mid ;
break;
}
}
return result;
}
References
转载请注明出处 leonchen1024.com/2018/08/14/…
About Me
我的博客 leonchen1024.com
我的 GitHub github.com/LeonChen102…
微信公众号

