


在RTC 2018 实时互联网大会上,美图云视觉技术总监赵丽丽分享了美图在短视频领域的AI技术应用,内容主要包括三部分:美图短视频的业务场景,基于此业务场景所做的短视频内容分析和检索技术,以及遇到的问题与相应的解决方案。最后是平台构建过程中的一些思考。以下是演讲内容整理。
欢迎访问 RTC 开发者社区,与更多实时音视频开发者交流经验。
美图在短视频领域的代表产品就是2014 年发布的短视频应用“美拍”。近几年也出现了一些竞品,比如抖音、快手。近期美拍也在内容上做了重新的调整和定位,主要是美和教程,希望用户在娱乐的过程中,也能吸取一些有营养的信息和知识。
一个视频所涉及的技术
一个视频在它的生命周期内可能涉及到许多处理技术。从2D 和3D 捕获开始,然后是编解码,这个阶段还涉及到传输、存储,然后是编辑与处理,比如剪辑、滤镜美化、风格转化、背景分割。随后是信息提取,包括物体识别、场景检测、人物分析、行为识别、主题提取、事件检测。以上步骤完成后,我们拿到了海量视频,还要做视频的检索。它有两部分作用,一是通过给定的视频,来检索其中是否有我们想要的内容;另一个是通过给定的视频在海量的数据库中检索出相似视频。
AI 技术在美图短视频业务中的应用主要两个层面,一是工具层面,二是内容层面。
工具层面是用AI 技术对视频进行处理,比如对视频人物的美化,背景的替换,还有视频中人物的瘦身功能。内容层面就是标签化,比如识别视频中的物体,检测视频中的场景,还有对用户行为的一些检测。另外,最重要的是,我们拿到一个视频之后,可以利用AI 对画质、视频内容是否违规进行检测。我们提取视频特征之后进行一些视频检索的工作,以这些工作去支撑围绕短视频的业务,包括用户画像、运营、推荐、搜索。
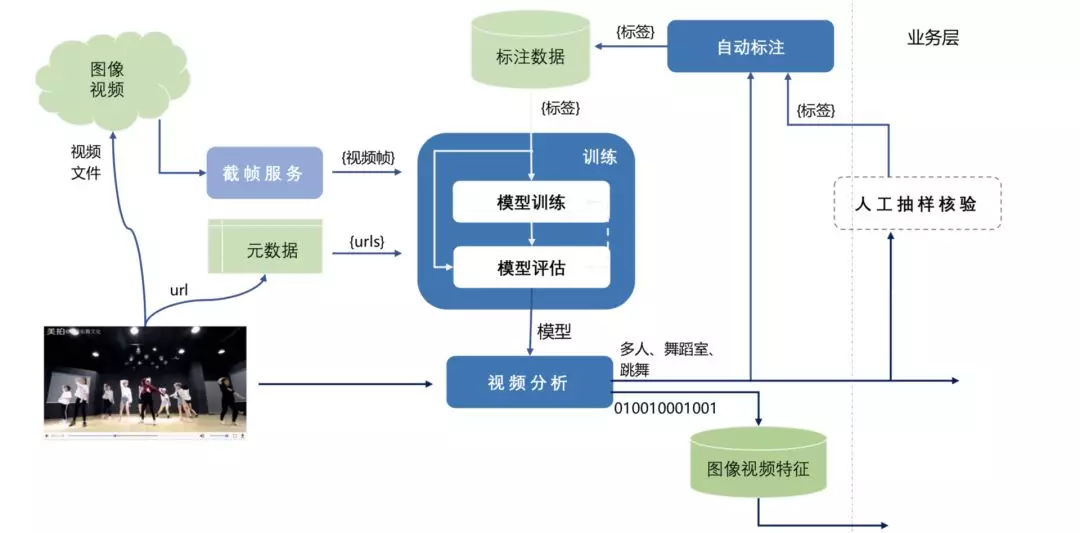
基于以上业务需求我们构建了一个多媒体内容分析和检索的平台,这个平台在基于内容分析算法组建基础之上分为两部分,一是多媒体内容分析平台,它负责分析视频内容特征,并进行标签化。另一个是多媒体数据检索平台。
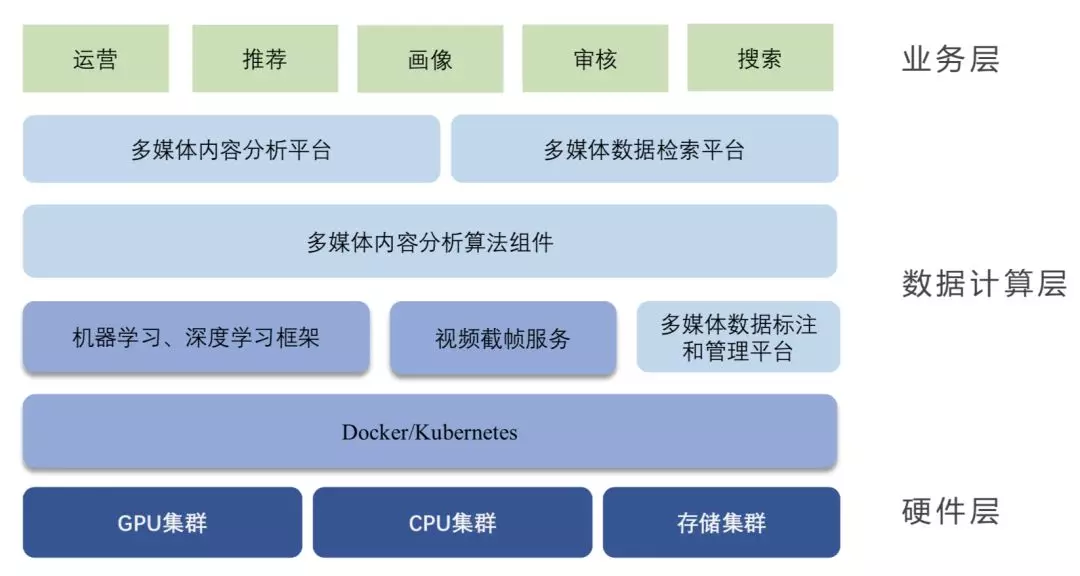
图:美图短视频内容分析与检索平台应用架构
短视频内容分析与检索的技术挑战
在拿到一个视频后,如何了解它的内容,这其实是一个多层面多维度的问题。首先最简单的,我们看到一个视频后,第一反应是它的色调、纹理、风格、画质如何。再更进一步,我们需要了解这个视频包含了哪些物体,发生的场景在哪里,有哪些人物特征,包括性别、年龄、特征、服饰,同时这个内容是否违规。另外,还有更深层次的对视频内容的识别、检测,比如学术界较为前沿的研究就是行为识别。这也是美图分析一个视频内容时候会涉及的几个维度。
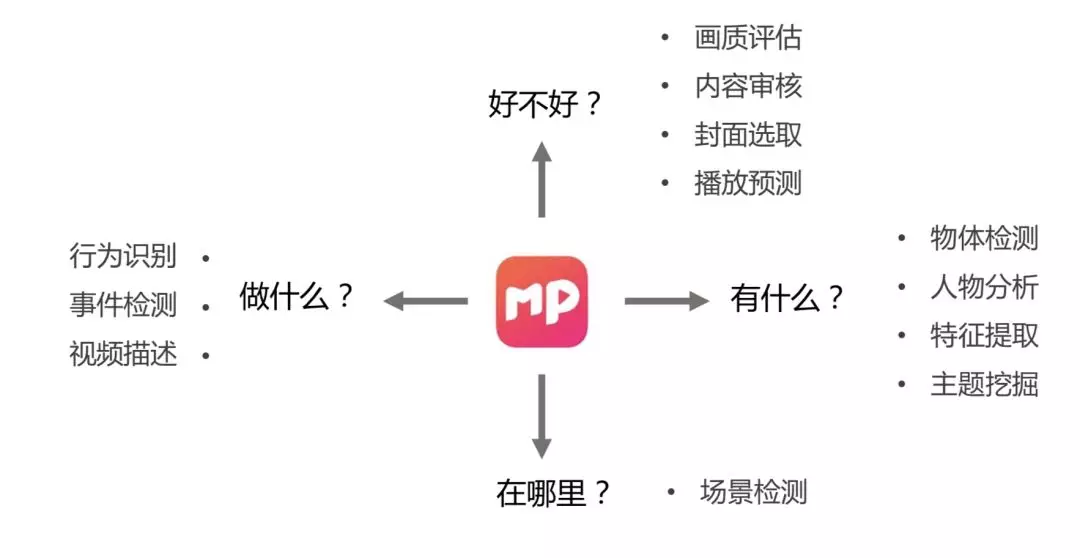
基于以上业务需求,我们通过对视频、音频、图象、文本,进行处理,将其传输给多媒体内容分析平台,然后解析出以下四类信息:
基础特征:色调、纹理、风格、画质;
人物解析:性别、年龄、颜值、发型、服饰风格;
商品解析:商品识别、品牌识别;
通用内容解析:视频分类、特征提取、场景分类、角度检测、物体检测、水印检测、封面选取。
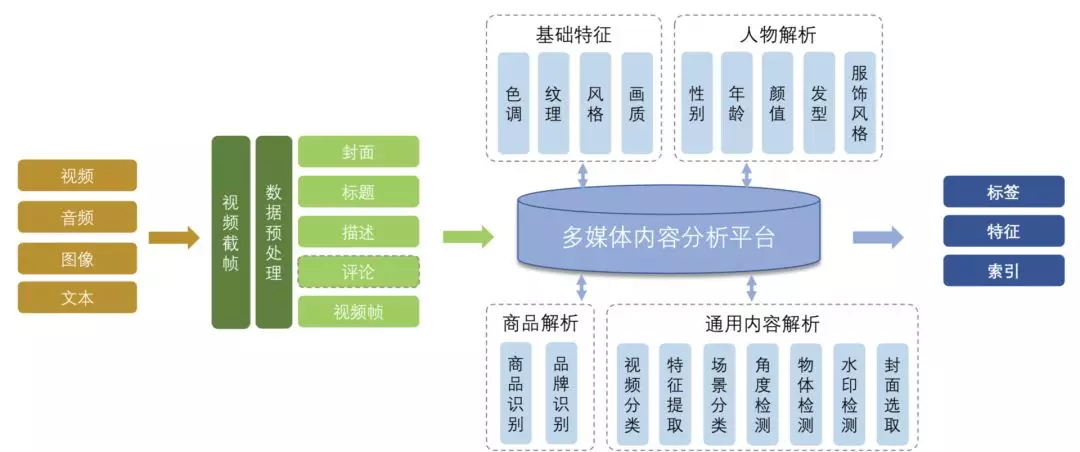
基于此,多媒体内容分析平台会提供出标签、特征、索引,以支持业务需求。
短视频数据有几个特点:
视频来源:手机拍摄;
视频形态:竖屏、人物中心化、特效和滤镜化;
视频结构:同个视频内场景固定;
信息维度:多模态信息、画面和背景音频不一致;
数据量大;
内容未知 ;
时效性;
在构建这个平台的过程中,我们遇到了一系列问题。总结起来有两个比较关键的问题:
一方面是如何有效定义标签体系。前面提到,标签是这个平台的一种输出形式。我们需要先确定输出哪些标签会对业务有所帮助,所以标签的定义非常重要。基于深度学习的算法训练需要有一些训练数据,训练数据中这个标签是怎么制定的,也非常重要。
另一方面是如何提高模型迭代效率。短视频数据有很强的时效性,比如说两个月前训练的模型,可能两个月后效果已然没那么好了,所以我们需要有一种机制能快速进行数据标注,替换到线上,稳定支撑业务。
如何有效定义标签体系
我们有一个热门视频池,运营和产品会手动为一些视频打上标签。你可能会说,我们可以拿这部分标签做模型训练。如果我们将业务标签应用于算法会存在哪些问题呢?
一是业务的标签比较抽象,比如可能会制定像搞笑和幽默这样的一些标签。但一个视频是否算搞笑、幽默,无法仅从视觉或声音、语音等一些信息进行准确判定。
举个例子,一个3岁的小孩在哭,父母上传的可能会是一个搞笑的视频,如果是20多岁或者50多岁的人在哭,那就是一个悲伤的视频。
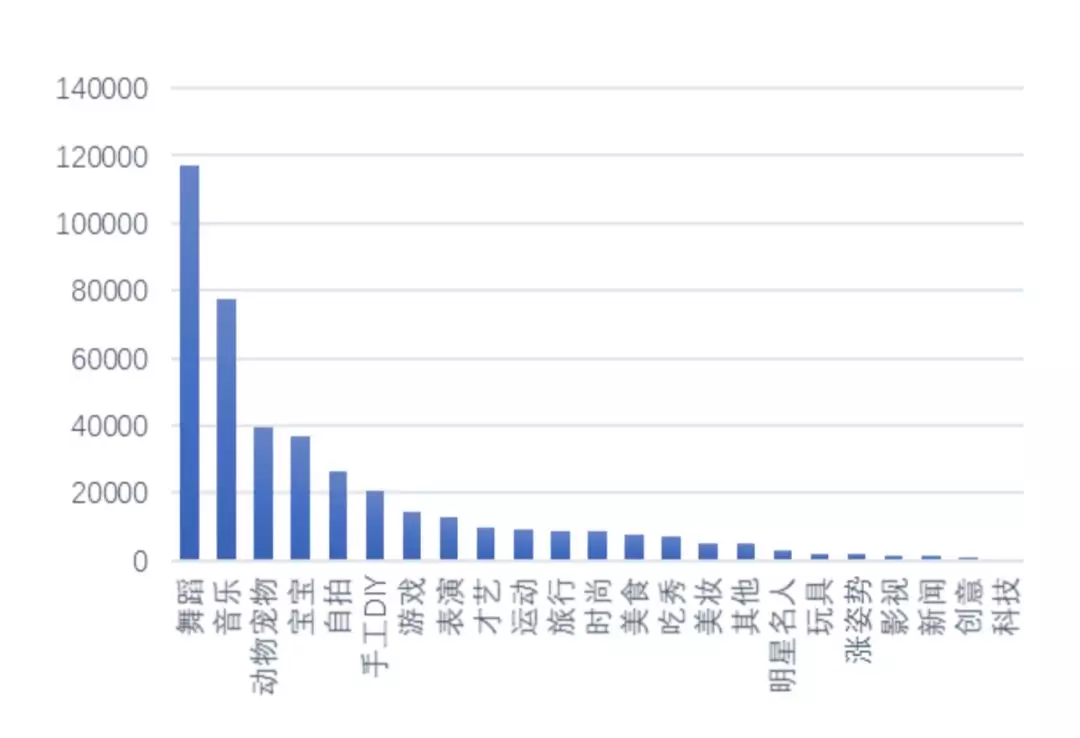
二是训练数据不均衡,上图是我们拿到的一部分业务标签对应的数据量,因为业务人员在定标签的时候不会考虑每个类别是什么样的,所以就会出现训练数据不均衡的问题,这个也会影响算法模型的训练。

另一个问题是类别区分度低。以上图为例,手指舞和自拍,从视觉角度来看没有任何区别,如果训练中强行将其分成两类,也会在训练过程中影响网络模型的学习,会引起一些噪声。
还有一个问题是标签的维度比较单一。通常一个视频,最多给四到五个维度的标签,再多的话,想全面衡量这个视频会变得非常复杂。
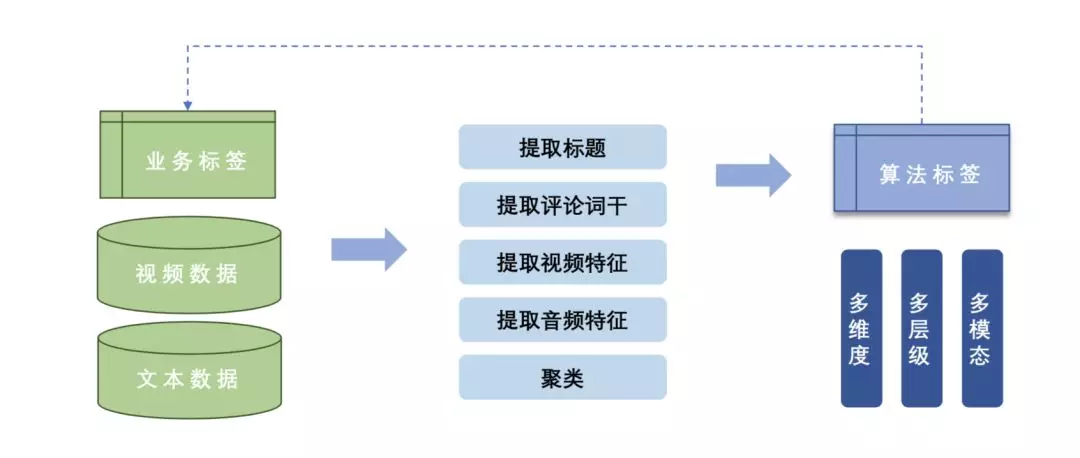
我们的解决方法是,以业务标签作为指引,拿我们的视频数据和文本数据(伴随视频的标题、评论相关信息)去提取视频特征、音频特征进行聚类,然后对聚类进行抽象定义,得出相应的视觉标签元素。这个标签元素就是我们用来训练的标签。最后训练标签输出的结果会反过来映射到业务标签,用这种方法定义的标签是多层级多维度的。
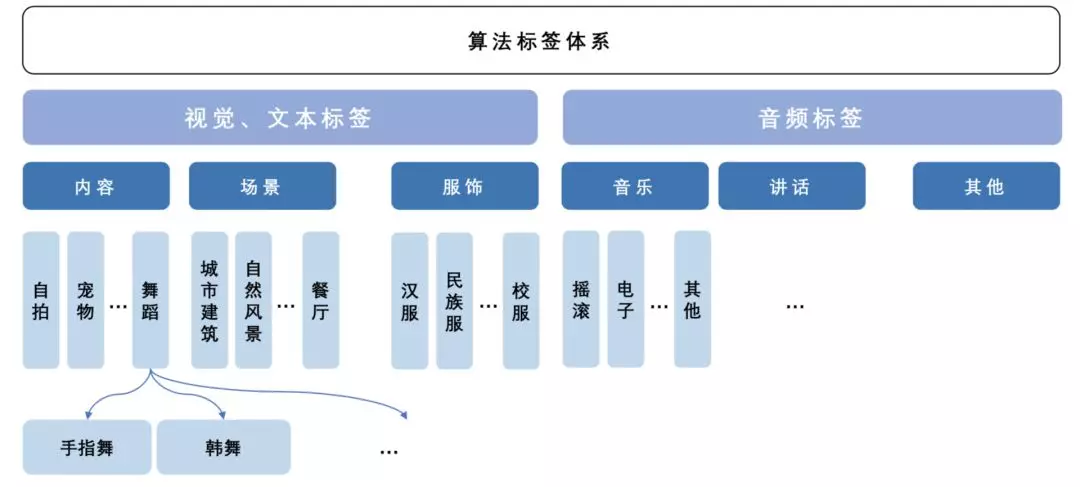
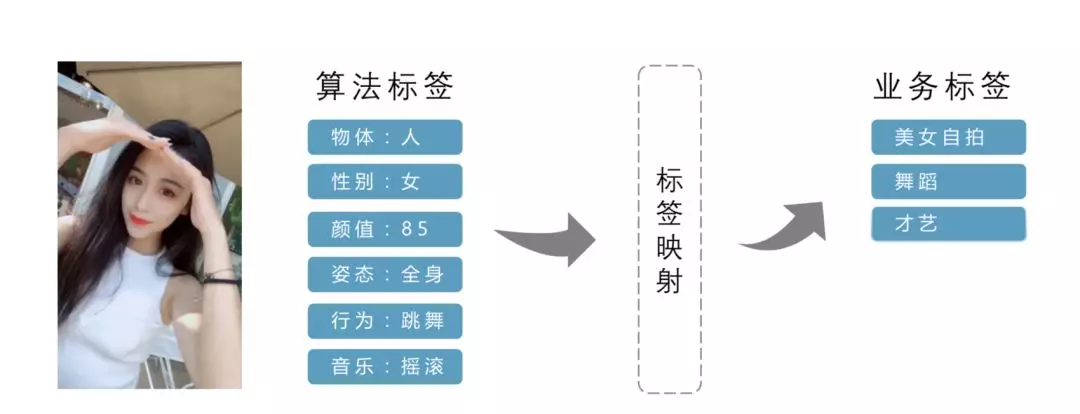
如下图所示,视频中是一个女生,视频中的姿态显示为全身,动作是在摇摆,检测到的音乐风格为摇滚,那么可以判断这个视频是一个美女在自拍,而且在跳舞,属于才艺展示,于是生成的标签就是“美女自拍”、“舞蹈”、“才艺”。这就完成一个算法标签到业务标签的映射。
如何提高线上算法模型的迭代更新效率
这里有三个核心问题:快速的数据标注、有效稳定的模型评估机制、算法运行的性能要有保障。
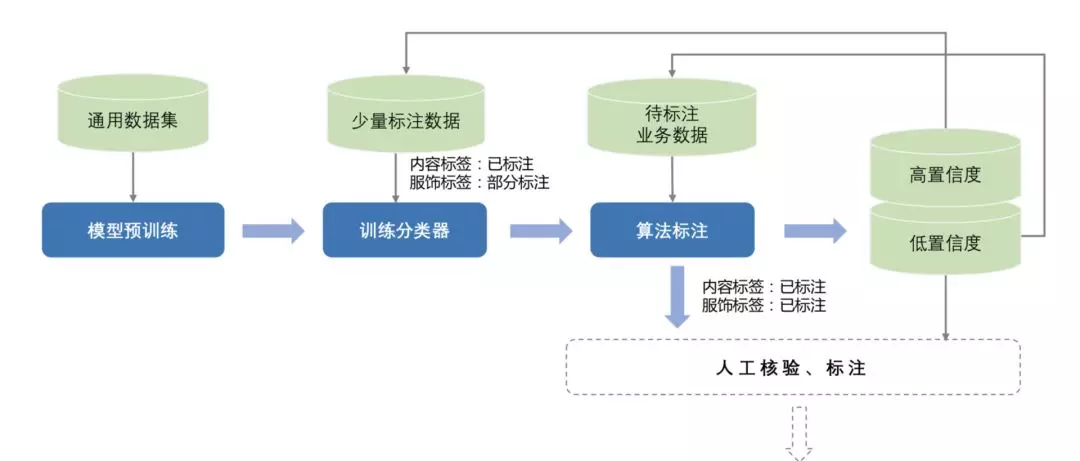
为了进行快速标注,我们也用了一个自动的算法标注,这个算法在无监督和半监督的深度学习的论文中被提到过。我们会预先拿一个通用的数据训练模型,对业务数据进行少量的标注,基于少量的标注数据再训练一个分类器。这个分类器会给其它未标注的进行标注。伴随标签输出会有一些置信度,会把高置信度的数据再拿去进行训练,低置信度的会继续下一次的迭代更新,这个过程会重复多次。这个过程也会根据任务的难度,加入人工的核验和标注。
美图有一套智能标签化服务模型,这个服务模型分两部分,如下图所示,上面是离线过程,下面是线上过程。线上拿到视频,输入相应的标签或者特征。离线过程中的自动标注就是上面提到算法标注,会用到自动标注输出的数据和标签进行一个模型的训练。我们会拿到这个数据进行模型训练,进行模型的评估,评估的时候用的数据也是我们标注好的一部分验证数据。当评估的准确率达到我们的域值之后,我们就认为模型可用了,就会更新到线上。
算法的运行性能,智能视觉分析平台其实包括很多,除了视频之外还有很多其它图象的算法,但相比较而言,视频算法的复杂度较高。这里以视频分类的技术为例,介绍一下我们是怎么做的。
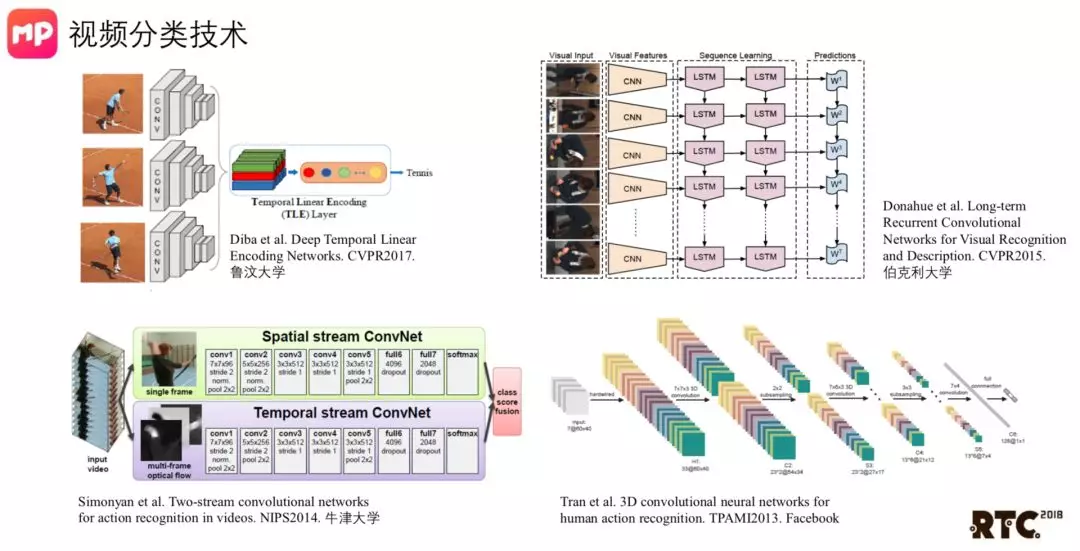
视频分类大部分分这几种形式。第一种是我们简单的对视频进行抽帧,使用CNN网络提取一些特征,进行融合,再对最后的结果进行分类。这种方法没有考虑到视频的时域信息。还有一些其他的算法,如上图所示左下方及右侧两种算法。他们都会考虑到视频的时域信息,但缺点是复杂度太高,很难被应用于实际场景中。
经过对短视频的应用场景的测评,第一种方法已经可以做到很好的准确率,相比较其它方案而言,它的时间复杂度也非常低。
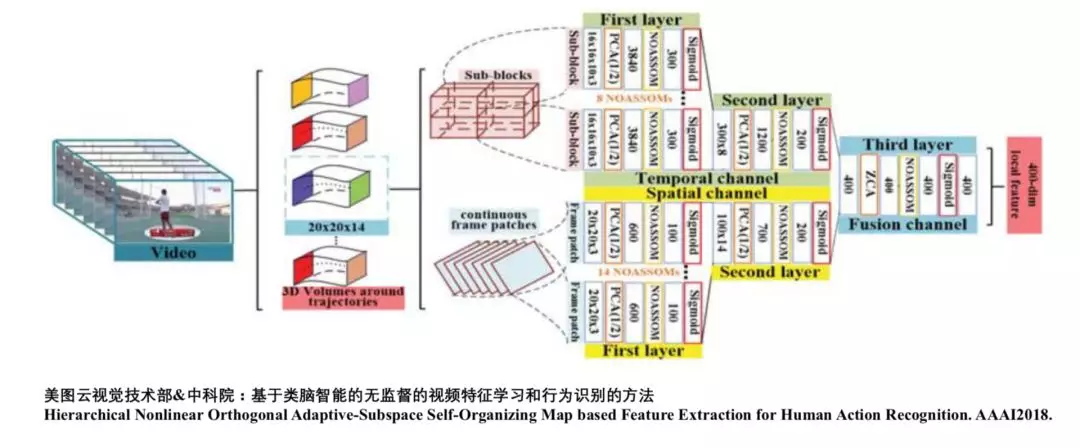
在视频分类方面,美图也有一些前沿的研究成果,我们跟中科院合作提出一个基于类脑智能的无监督的视频特征学习和行为识别的方法。
业界、学术界,有很多种模型,但在实际业务场景中,看似庞大的网络,其效果却不一定那么理想。更重要的是,对于我们来说,怎么能从海量的业务数据中抽取最关键、最重要的数据,用来训练出一个适用于业务场景的模型。我们也在多媒体内容分析平台的构建中总结了几点,我们认为有三个信息非常重要:
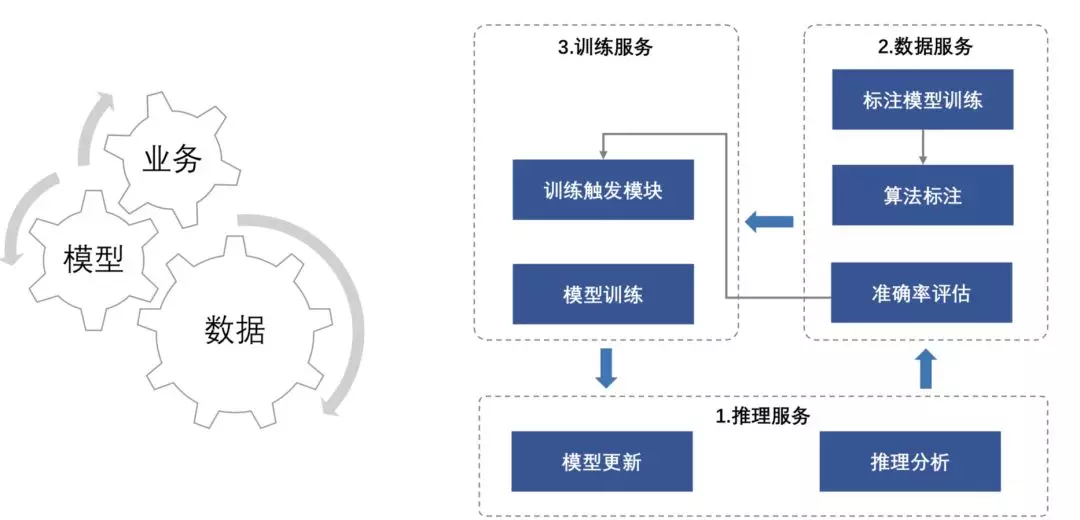
推理服务:一方面对获得的数据进行推理分析,另一方面对完成训练的模型更新上线;
数据服务:提供用于模型训练的标注数据,其核心模块是算法自动标注;
训练服务:它包含训练触发模块,会定期更新模型训练。
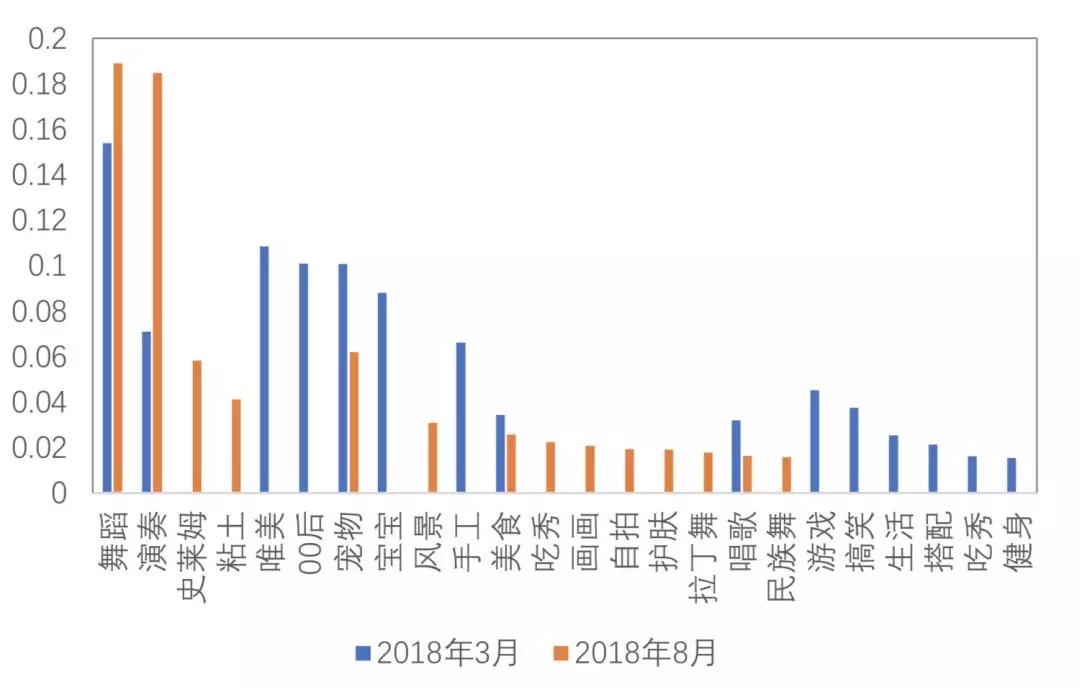
前面提到的都是我们进行一个内容分析,大部分以标签输出为主。其实用标签描述事情是存在一些问题的,一个是时效性,上图是我们分别在3月和8月总结出的一部分标签体系中的标签变化,其实差别还是挺大的。第二个问题是不完备。想用标签去描述一个视频或一张图片的话,需要非常多的维度。如果我们在进行视频的检索,在搜索的时候想比较两个视频的相似度怎么办?如果用标签的话就非常难。
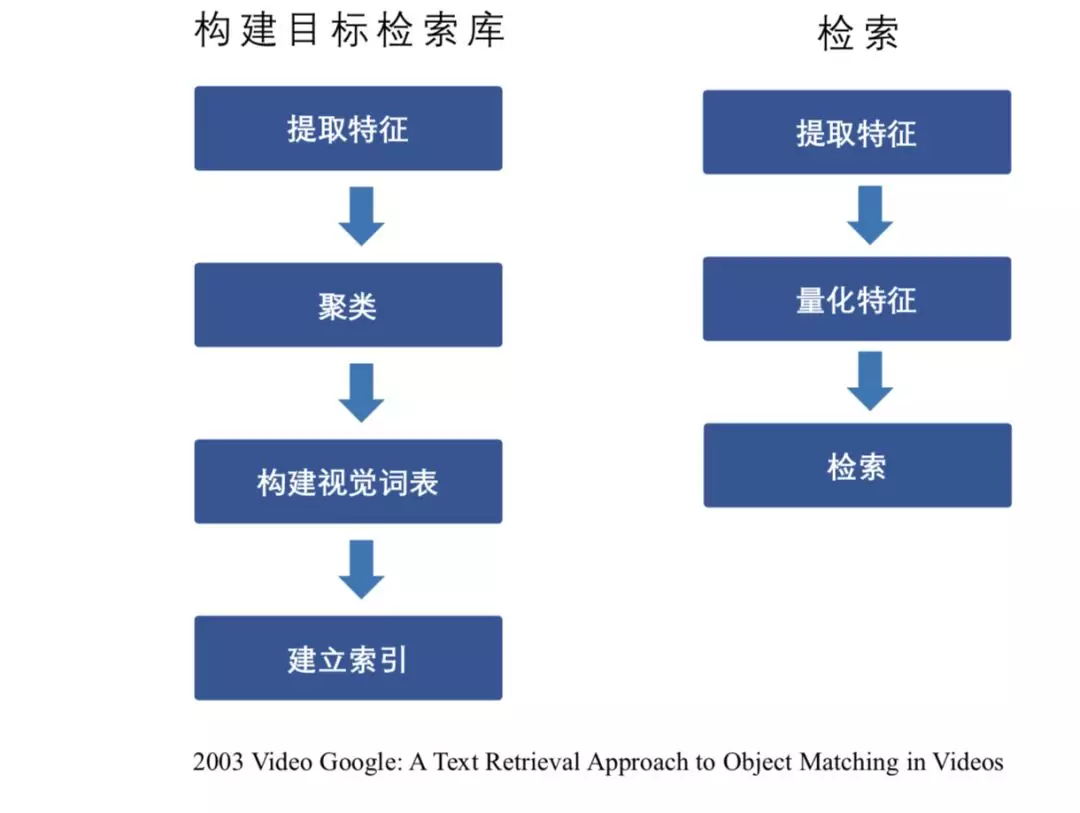
上图是视频检索的流程,是将2003年谷歌提出的文本检索的过程应用到视频的检索方案。它包括两部分,一是构建目标检索库,二是检索。获取到一些视频后,从视频中抽取帧,对这些帧图象提取特征,进行聚类,然后去构建视觉词表。
特征对比有有类,二进制特征和浮点特征,有各自的优缺点。二进制特征一个比较大的优点是存储高效、距离计算高效,缺点是可表征的范围比较小。浮点特征欧式距离、抗极值干扰,距离表征值比较大,理论上讲是从零到无穷的。
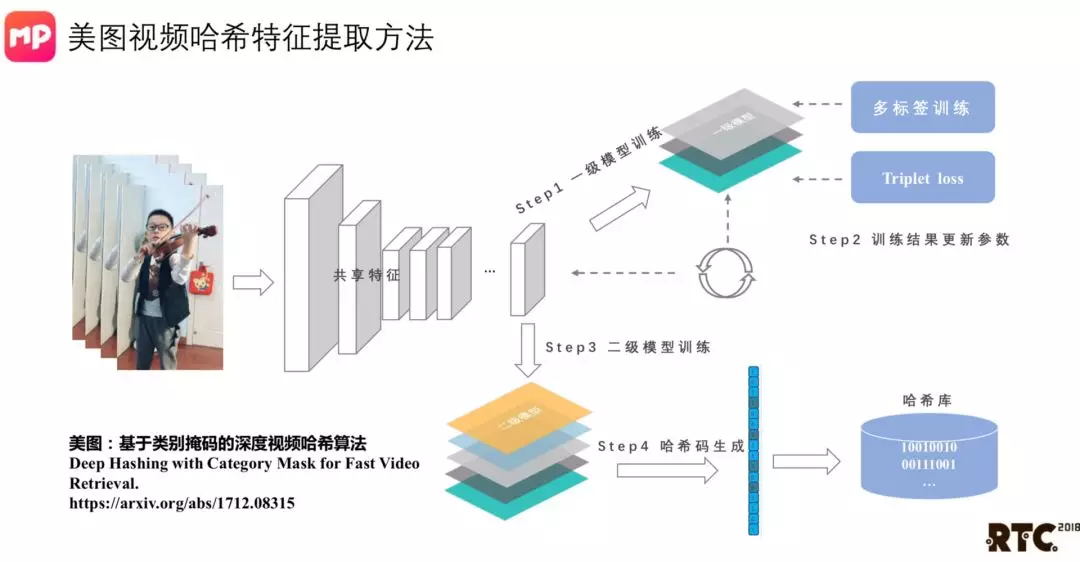
上图我们一个简单的思路。我们会基于前面构建的多层次的变向体系,用多级的标签指引这个网络进行学习。另外会用 triplet loss,对同一个视频,我们会抽取5帧,然后在不同的时间段再抽取5帧,这样形成一个正样本对。从一个视频和其它视频组成负样本对,让他学习到什么样的信息才是视频特拥有的特征。
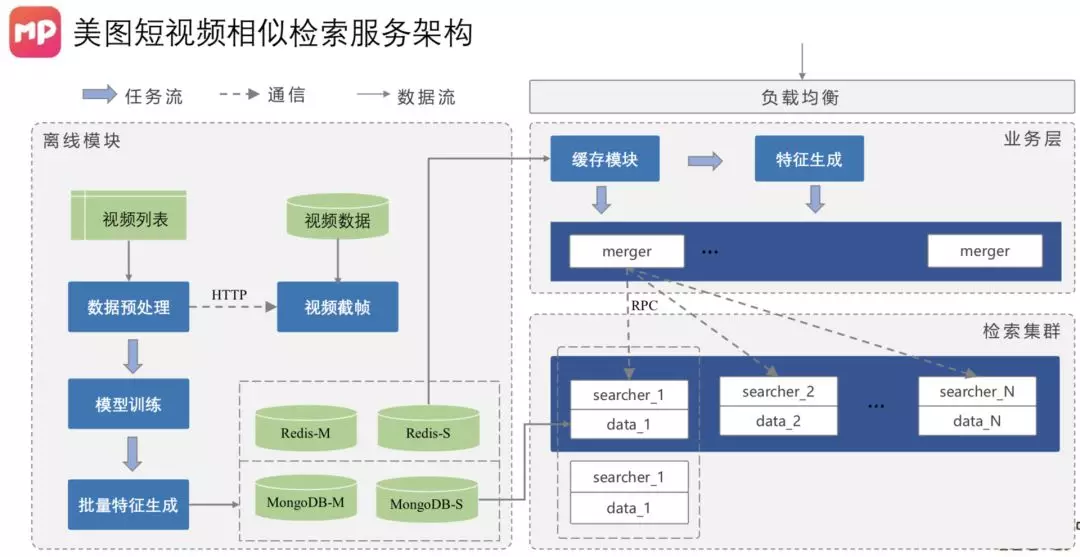
上图是一个短视频相似检索服务的架构,左边是离线模块,右边是在线模块。离线是批量训练,生成哈希值。
总结
在这个平台建设过程中我们也遇到一些问题,也有一些思考。主要是这几点:
AI让多媒体技术有了更大的应用空间,视频领域仍有大量业务场景需要AI助力;
数据仍是当前阶段AI算法有效落地的核心元素,越接近业务场景,领域数据的重要性越明显;
通用算法技术的作用在弱化,需要结合具体业务场景深入优化;
技术领域需要进行持续探索,算法性能问题、细粒度语义理解、互联网多媒体内容智能交互等。


扫码观看演讲视频回顾
想获取更多演讲资料,了解更多 RTC 技术干货,欢迎关注「声网Agora」微信公众号
