

欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~
正文
本文介绍Metal和Metal Shader Language,以及Metal和OpenGL ES的差异性,也是实现入门教程的心得总结。
一、Metal
Metal 是一个和 OpenGL ES 类似的面向底层的图形编程接口,可以直接操作GPU;支持iOS和OS X,提供图形渲染和通用计算能力。(不支持模拟器)
图片来源 www.invasivecode.com/weblog/meta…
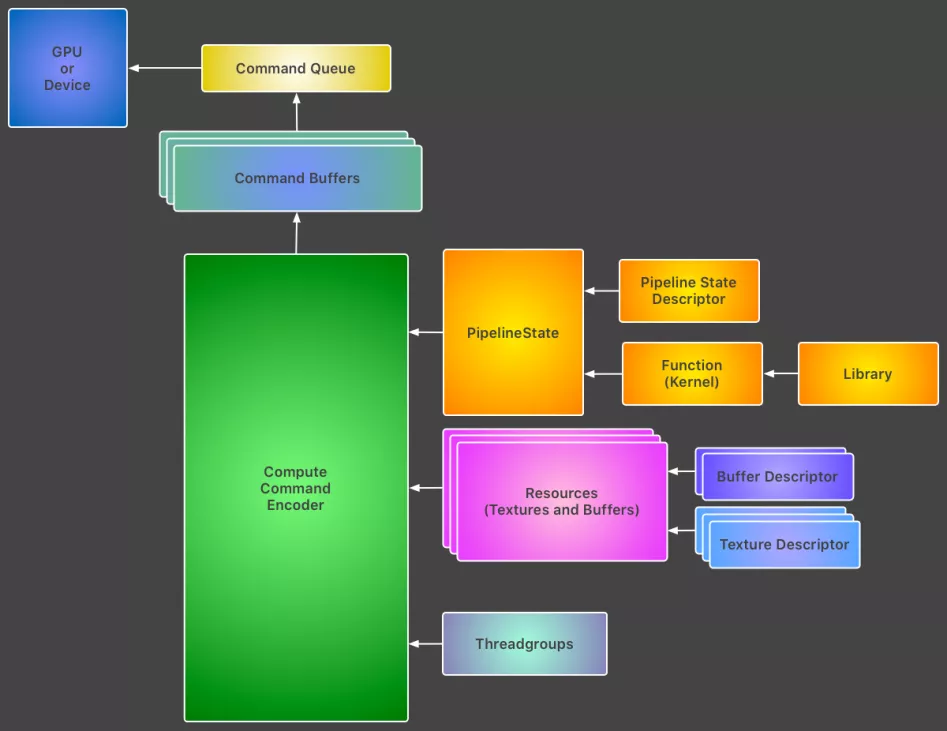
MTLDevice 对象代表GPU,通常使用MTLCreateSystemDefaultDevice获取默认的GPU; MTLCommandQueue由device创建,用于创建和组织MTLCommandBuffer,保证指令(MTLCommandBuffer)有序地发送到GPU;MTLCommandBuffer会提供一些encoder,包括编码绘制指令的MTLRenderCommandEncoder、编码计算指令的MTLComputeCommandEncoder、编码缓存纹理拷贝指令的MTLBlitCommandEncoder。对于一个commandBuffer,只有调用encoder的结束操作,才能进行下一个encoder的创建,同时可以设置执行完指令的回调。 每一帧都会产生一个MTLCommandBuffer对象,用于填放指令; GPUs的类型很多,每一种都有各自的接收和执行指令方式,在MTLCommandEncoder把指令进行封装后,MTLCommandBuffer再做聚合到一次提交里。 MTLRenderPassDescriptor 是一个轻量级的临时对象,里面存放较多属性配置,供MTLCommandBuffer创建MTLRenderCommandEncoder对象用。
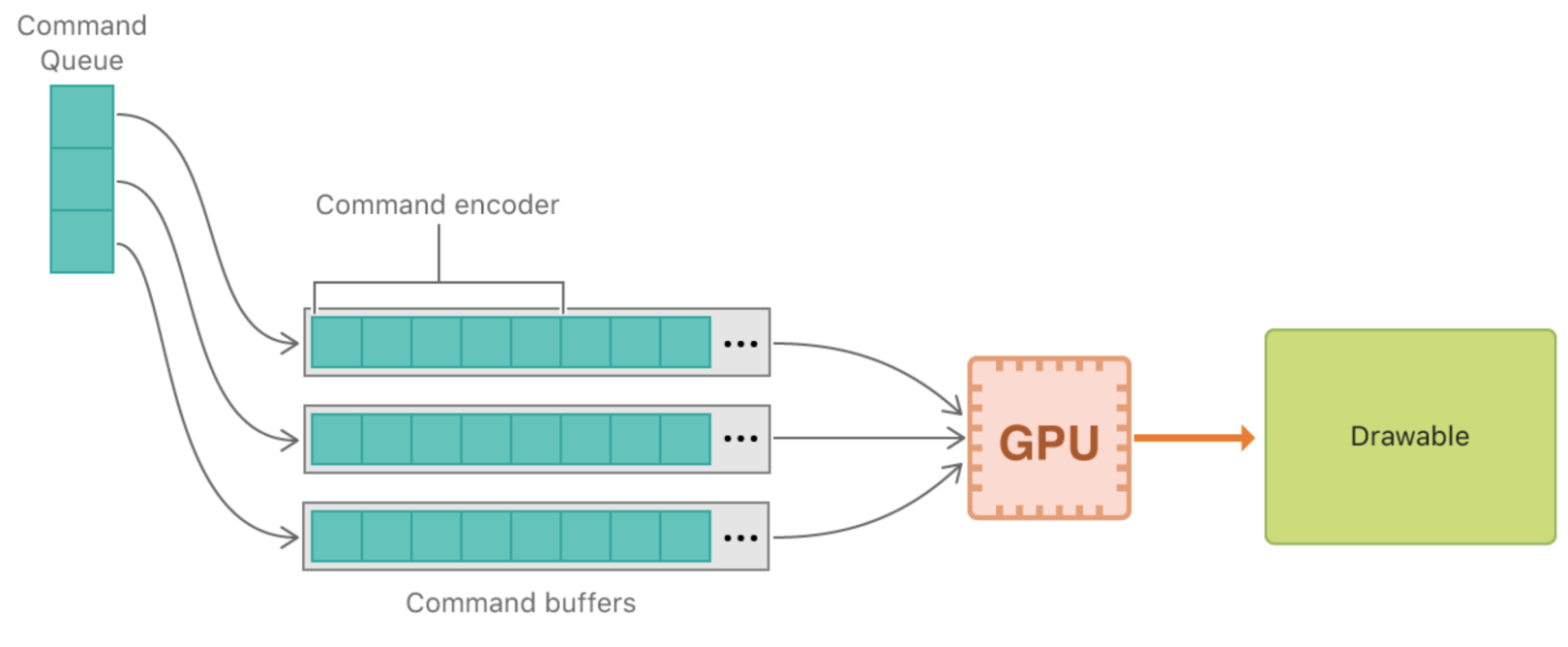
MTLRenderPassDescriptor 用来更方便创建MTLRenderCommandEncoder,由MetalKit的view设置属性,并且在每帧刷新时都会提供新的MTLRenderPassDescriptor;MTLRenderCommandEncoder在创建的时候,会隐式的调用一次clear的命令。 最后再调用present和commit接口。
Metal的viewport是3D的区域,包括宽高和近/远平面。
深度缓冲最大值为1,最小值为0,如下面这两个都不会显示。
// clipSpacePosition为深度缓冲
out.clipSpacePosition = vector_float4(0.0, 0.0, -0.1, 1.0);
out.clipSpacePosition = vector_float4(0.0, 0.0, 1.1, 1.0);
渲染管道
Metal把输入、处理、输出的管道看成是对指定数据的渲染指令,比如输入顶点数据,输出渲染后纹理。 MTLRenderPipelineState 表示渲染管道,最主要的三个过程:顶点处理、光栅化、片元处理:

转换几何形状数据为帧缓存中的颜色像素,叫做点阵化(rasterizing),也叫光栅化。其实就是根据顶点的数据,检测像素中心是否在三角形内,确定具体哪些像素需要渲染。 对开发者而言,顶点处理和片元处理是可编程的,光栅化是固定的(不可见)。 顶点函数在每个顶点被绘制时都会调用,比如说绘制一个三角形,会调用三次顶点函数。顶点处理函数返回的对象里,必须有带[[position]]描述符的属性,表面这个属性是用来计算下一步的光栅化;返回值没有描述符的部分,则会进行插值处理。
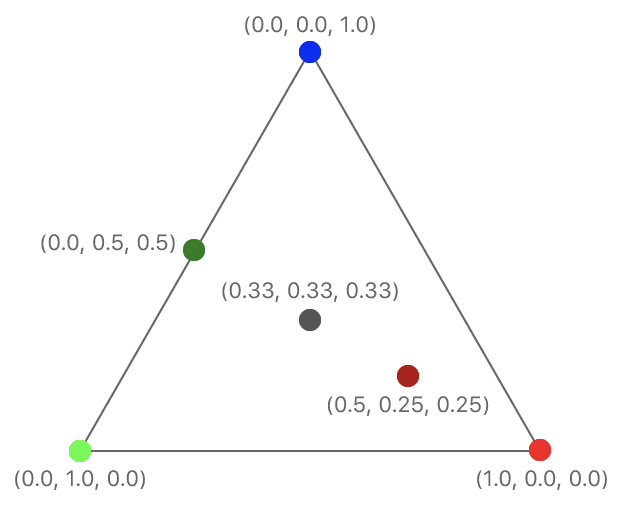
插值处理
像素处理是针对每一个要渲染的像素进行处理,返回值通常是4个浮点数,表示RGBA的颜色。
在编译的时候,Xcode会单独编译.metal的文件,但不会进行链接;需要在app运行时,手动进行链接。 在包里,可以看到default.metallib,这是对metal shader的编译结果。
MTLFunction可以用来创建MTLRenderPipelineState对象,MTLRenderPipelineState代表的是图形渲染的管道; 在调用device的newRenderPipelineStateWithDescriptor:error接口时,会进行顶点、像素函数的链接,形成一个图像处理管道; MTLRenderPipelineDescriptor包括名称、顶点处理函数、片元处理函数、输出颜色格式。
setVertexBytes:length:atIndex:这接口的长度限制是4k(4096bytes),对于超过的场景应该使用MTLBuffer。MTLBuffer是GPU能够直接读取的内存,用来存储大量的数据;(常用于顶点数据) newBufferWithLength:options:方法用来创建MTLBuffer,参数是大小和访问方式;MTLResourceStorageModeShared是默认的访问方式。
纹理
Metal要求所有的纹理都要符合MTLPixelFormat上面的某一种格式,每个格式都代表对图像数据的不同描述方式。 例如MTLPixelFormatBGRA8Unorm格式,内存布局如下:

每个像素有32位,分别代表BRGA。 MTLTextureDescriptor 用来设置纹理属性,例如纹理大小和像素格式。 MTLBuffer用于存储顶点数据,MTLTexture则用于存储纹理数据;MTLTexture在创建之后,需要调用replaceRegion:mipmapLevel:withBytes:bytesPerRow:填充纹理数据;因为图像数据一般按行进行存储,所以需要每行的像素大小。
[[texture(index)]] 用来描述纹理参数,比如说 samplingShader(RasterizerData in [[stage_in]], texture2d<half> colorTexture [[ texture(AAPLTextureIndexBaseColor) ]]) 在读取纹理的时候,需要两个参数,一个是sampler和texture coordinate,前者是采样器,后者是纹理坐标。 读取纹理其实就把对应纹理坐标的像素颜色读取出来。 纹理坐标默认是(0,0)到(1,1),如下:
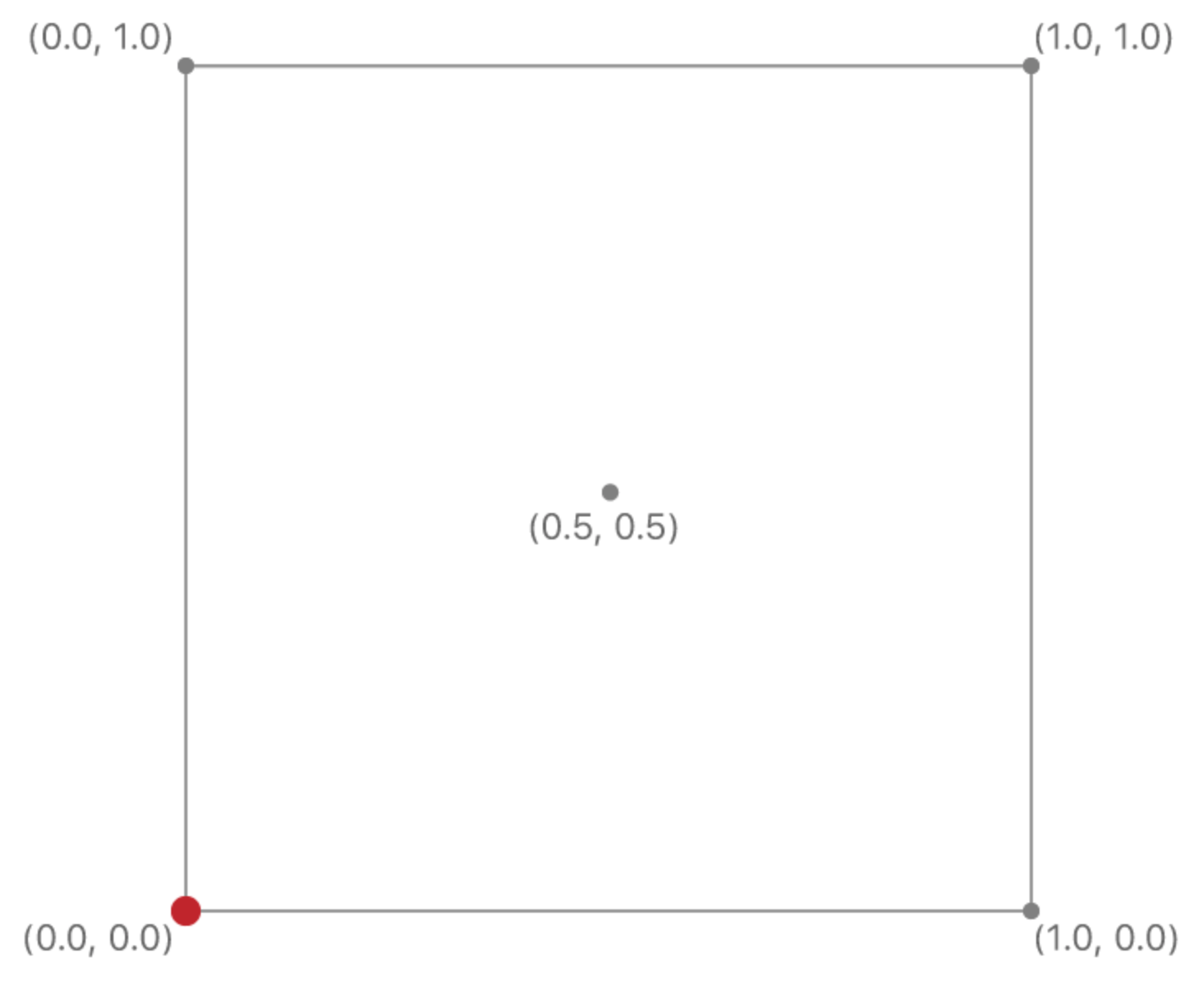
有时候,纹理的坐标会超过1,采样器会根据事前设置的mag_filter::参数进行计算。
通用计算
通用图形计算是general-purpose GPU,简称GPGPU。 GPU可以用于加密、机器学习、金融等,图形绘制和图形计算并不是互斥的,Metal可以同时使用计算管道进行图形计算,并且用渲染管道进行渲染。
计算管道只有一个步骤,就是kernel function(内核函数),内核函数直接读取并写入资源,不像渲染管道需要经过多个步骤; MTLComputePipelineState 代表一个计算处理管道,只需要一个内核函数就可以创建,相比之下,渲染管道需要顶点和片元两个处理函数;
每次内核函数执行,都会有一个唯一的gid值; 内核函数的执行次数需要事先指定,这个次数由格子大小决定。
threadgroup 指的是设定的处理单元,这个值要根据具体的设备进行区别,但必须是足够小的,能让GPU执行; threadgroupCount 是需要处理的次数,一般来说threadgroupCount*threadgroup=需要处理的大小。
性能相关
临时对象(创建和销毁是廉价的,它们的创建方法都返回 autoreleased对象) 1.Command Buffers 2.Command Encoders 代码中不需要持有。
高消耗对象(在性能相关的代码里应该尽量重用它,避免反复创建) 1.Command Queues 2.Buffers 3.Textures 5.Compute States 6.Render Pipeline States 代码中需长期持有。
Metal常用的四种数据类型:half、float、short(ushort)、int(uint)。 GPU的寄存器是16位,half是性能消耗最低的数据类型;float需要两次读取、消耗两倍的寄存器空间、两倍的带宽、两倍的电量。 为了提升性能,half和float之间的转换由硬件来完成,不占用任何开销。 同时,Metal自带的函数都是经过优化的。 在float和half数据类型混合的计算中,为了保持精度会自动将half转成float来处理,所以如果想用half节省开销的话,要避免和float混用。 Metal同样不擅长处理control flow,应该尽可能使用使用三元表达式,取代简单的if判断。
此部分参考自WWDC
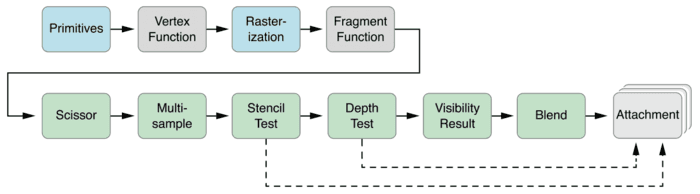
常见的图形渲染管道
二、Metal Shader Language
Metal Shader Language的使用场景有两个,分别是图形渲染和通用计算;基于C++ 14,运行在GPU上,GPU的特点:带宽大,并行处理,内存小,对条件语句处理较慢(等待时间长)。 Metal着色语言使用clang和 LLVM,支持重载函数,但不支持图形渲染和通用计算入口函数的重载、递归函数调用、new和delete操作符、虚函数、异常处理、函数指针等,也不能用C++ 11的标准库。
基本函数
shader有三个基本函数:
- 顶点函数(vertex),对每个顶点进行处理,生成数据并输出到绘制管线;
- 像素函数(fragment),对光栅化后的每个像素点进行处理,生成数据并输出到绘制管线;
- 通用计算函数(kernel),是并行计算的函数,其返回值类型必须为void;
顶点函数相关的修饰符:
- [[vertex_id]] vertex_id是顶点shader每次处理的index,用于定位当前的顶点
- [[instance_id]] instance_id是单个实例多次渲染时,用于表明当前索引;
- [[clip_distance]],float 或者 float[n], n必须是编译时常量;
- [[point_size]],float;
- [[position]],float4;
如果一个顶点函数的返回值不是void,那么返回值必须包含顶点位置; 如果返回值是float4,默认表示位置,可以不带[[ position ]]修饰符; 如果一个顶点函数的返回值是结构体,那么结构体必须包含“[[ position ]]”修饰的变量。
像素函数相关的修饰符:
- [[color(m)]] float或half等,m必须是编译时常量,表示输入值从一个颜色attachment中读取,m用于指定从哪个颜色attachment中读取;
- [[front_facing]] bool,如果像素所属片元是正面则为true;
- [[point_coord]] float2,表示点图元的位置,取值范围是0.0到1.0;
- [[position]] float4,表示像素对应的窗口相对坐标(x, y, z, 1/w);
- [[sample_id]] uint,The sample number of the sample currently being processed.
- [[sample_mask]] uint,The set of samples covered by the primitive generating the fragmentduring multisample rasterization.
以上都是输入相关的描述符。像素函数的返回值是单个像素的输出,包括一个或是多个渲染结果颜色值,一个深度值,还有一个sample遮罩,对应的输出描述符是[[color(m)]] floatn、[[depth(depth_qualifier)]] float、[[sample_mask]] uint。
struct LYFragmentOutput {
// color attachment 0
float4 color_float [[color(0)]];// color attachment 1
int4 color_int4 [[color(1)]];// color attachment 2
uint4 color_uint4 [[color(2)]];};
fragment LYFragmentOutput fragment_shader( ... ) { ... };
需要注意,颜色attachment的参数设置要和像素函数的输入和输出的数据类型匹配。
Metal支持一个功能,叫做前置深度测试(early depth testing),允许在像素着色器运行之前运行深度测试。如果一个像素被覆盖,则会放弃渲染。使用方式是在fragment关键字前面加上[[early_fragment_tests]]:
[[early_fragment_tests]] fragment float4 samplingShader(..)使用前置深度测试的要求是不能在fragment shader对深度进行写操作。 深度测试还不熟悉的,可以看LearnOpenGL关于深度测试的介绍。
参数的地址空间选择
Metal种的内存访问主要有两种方式:Device模式和Constant模式,由代码中显式指定。 Device模式是比较通用的访问模式,使用限制比较少,而Constant模式是为了多次读取而设计的快速访问只读模式,通过Constant内存模式访问的参数的数据的字节数量是固定的,特点总结为:
- Device支持读写,并且没有size的限制;
- Constant是只读,并且限定大小;
如何选择Device和Constant模式? 先看数据size是否会变化,再看访问的频率高低,只有那些固定size且经常访问的部分适合使用constant模式,其他的均用Device。
// Metal关键函数用到的指针参数要用地址空间修饰符(device, threadgroup, or constant) 如下
vertex RasterizerData // 返回给片元着色器的结构体
vertexShader(uint vertexID [[ vertex_id ]], // vertex_id是顶点shader每次处理的index,用于定位当前的顶点
constant LYVertex *vertexArray [[ buffer(0) ]]); // buffer表明是缓存数据,0是索引
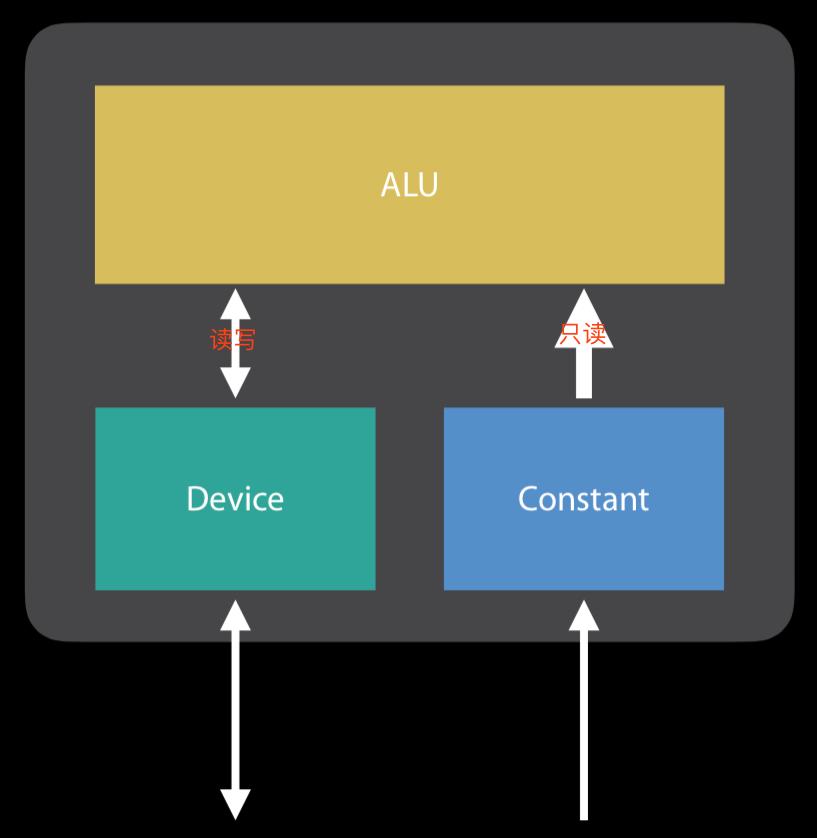
地址空间的修饰符共有四个,device、threadgroup、constant、thread。 顶点函数(vertex)、像素函数(fragment)、通用计算函数(kernel)的指针或引用参数,都必须带有地址空间修饰符号。 对于顶点函数(vertex)和像素函数(fragment),其指针或引用参数必须定义在device或是constant地址空间; 对于通用计算函数(kernel),其指针或引用参数必须定义在device或是threadgroup或是constant地址空间; void tranforms(device int *source_data, threadgroup int *dest_data, constant float *param_data) {/*...*/}; 如上使用了三种地址空间修饰符,因为有threadgroup修饰符,tranforms函数只能被通用计算函数调用。
constant地址空间用于从设备内存池分配存储的缓存对象,是只读的。constant地址空间的指针或引用可以做函数的参数,向声明为常量的变量赋值会产生编译错误,声明常量但是没有赋予初始值也会产生编译错误。 在shader中,函数之外的变量(相当于全局变量),其地址空间必须是constant。
device地址空间用于从设备内存池分配出来的缓存对象,可读也可写。一个缓存对象可以被声明成一个标量、向量或是用户自定义结构体的指针或是引用。缓存对象使用的内存实际大小,应该在CPU侧调用时就确定。 纹理对象总是在device地址空间分配内存,所以纹理类型可以省略修饰符。
threadgroup地址空间用于通用计算函数变量的内存分配,变量被一个线程组的所有的线程共享,threadgroup地址空间分配的变量不能用于图形绘制函数。
thread地址空间用于每个线程内部的内存分配,被thread修饰的变量在其他线程无法访问,在图形绘制或是通用计算函数内声明的变量是thread地址空间分配。 如下一段代码,包括device、threadgroup、thread的使用:
typedef struct
{
half3 kRec709Luma; // position的修饰符表示这个是顶点
} TransParam;
kernel void
sobelKernel(texture2d<half, access::read> sourceTexture [[texture(LYFragmentTextureIndexTextureSource)]],
texture2d<half, access::write> destTexture [[texture(LYFragmentTextureIndexTextureDest)]],
uint2 grid [[thread_position_in_grid]],
device TransParam *param [[buffer(0)]], // param.kRec709Luma = half3(0.2126, 0.7152, 0.0722); // 把rgba转成亮度值
threadgroup float3 *localBuffer [[threadgroup(0)]]) // threadgroup地址空间,这里并没有使用到;
{
// 边界保护
if(grid.x <= destTexture.get_width() && grid.y <= destTexture.get_height())
{
thread half4 color = sourceTexture.read(grid); // 初始颜色
thread half gray = dot(color.rgb, half3(param->kRec709Luma)); // 转换成亮度
destTexture.write(half4(gray, gray, gray, 1.0), grid); // 写回对应纹理
}
}
数据结构
Metal中常用的数据结构有向量、矩阵、原子数据类型、缓存、纹理、采样器、数组、用户自定义结构体。
half 是16bit是浮点数 0.5h float 是32bit的浮点数 0.5f size_t 是64bit的无符号整数 通常用于sizeof的返回值 ptrdiff_t 是64bit的有符号整数 通常用于指针的差值 half2、half3、half4、float2、float3、float4等,是向量类型,表达方式为基础类型+向量维数。矩阵类似half4x4、half3x3、float4x4、float3x3。 double、long、long long不支持。
对于向量的访问,比如说vec=float4(1.0f, 1.0f, 1.0f, 1.0f),其访问方式可以是vec[0]、vec[1],也可以是vec.x、vec.y,也可以是vec.r、vec.g。(.xyzw和.rgba,前者对应三维坐标,后者对应RGB颜色空间) 只取部分、乱序取均可,比如说我们常用到的color=texture.bgra。
数据对齐 char3、uchar3的size是4Bytes,而不是3Bytes; 类似的,int是4Bytes,但int3是16而不是12Bytes; 矩阵是由一组向量构成,按照向量的维度对齐;float3x3由3个float3向量构成,那么每个float3的size是16Bytes; 隐式类型转换(Implicit Type Conversions) 向量到向量或是标量的隐式转换会导致编译错误,比如
int4 i; float4 f = i; // compile error,无法将一个4维的整形向量转换为4维的浮点向量。 标量到向量的隐式转换,是标量被赋值给向量的每一个分量。float4 f = 2.0f; // f = (2.0f, 2.0f, 2.0f, 2.0f)标量到矩阵、向量到矩阵的隐式转换,矩阵到矩阵和向量及标量的隐式转换会导致编译错误。
纹理数据结构不支持指针和引用,纹理数据结构包括精度和access描述符,access修饰符描述纹理如何被访问,有三种描述符:sample、read、write,如下:
kernel void
sobelKernel(texture2d<half, access::read> sourceTexture [[texture(LYFragmentTextureIndexTextureSource)]],
texture2d<half, access::write> destTexture [[texture(LYFragmentTextureIndexTextureDest)]],
uint2 grid [[thread_position_in_grid]])
Sampler是采样器,决定如何对一个纹理进行采样操作。寻址模式,过滤模式,归一化坐标,比较函数。 在Metal程序里初始化的采样器必须使用constexpr修饰符声明。 采样器指针和引用是不支持的,将会导致编译错误。
constexpr sampler textureSampler (mag_filter::linear,
min_filter::linear); // sampler是采样器
运算符
- 矩阵相乘有一个操作数是标量,那么这个标量和矩阵中的每一个元素相乘,得到一个和矩阵有相同行列的新矩阵。
- 右操作数是一个向量,那么它被看做一个列向量,如果左操作数是一个向量,那么他被看做一个行向量。这个也说明,为什么我们要固定用mvp乘以position(左乘矩阵),而不能position乘以mvp!因为两者的处理结果不一致。
三、Metal和OpenGL ES的差异
OpenGL的历史已经超过25年。基于当时设计原则,OpenGL不支持多线程,异步操作,还有着臃肿的特性。为了更好利用GPU,苹果设计了Metal。 Metal的目标包括更高效的CPU&GPU交互,减少CPU负载,支持多线程执行,可预测的操作,资源控制和同异步控制;接口与OpenGL类似,但更加切合苹果设计的GPUs。
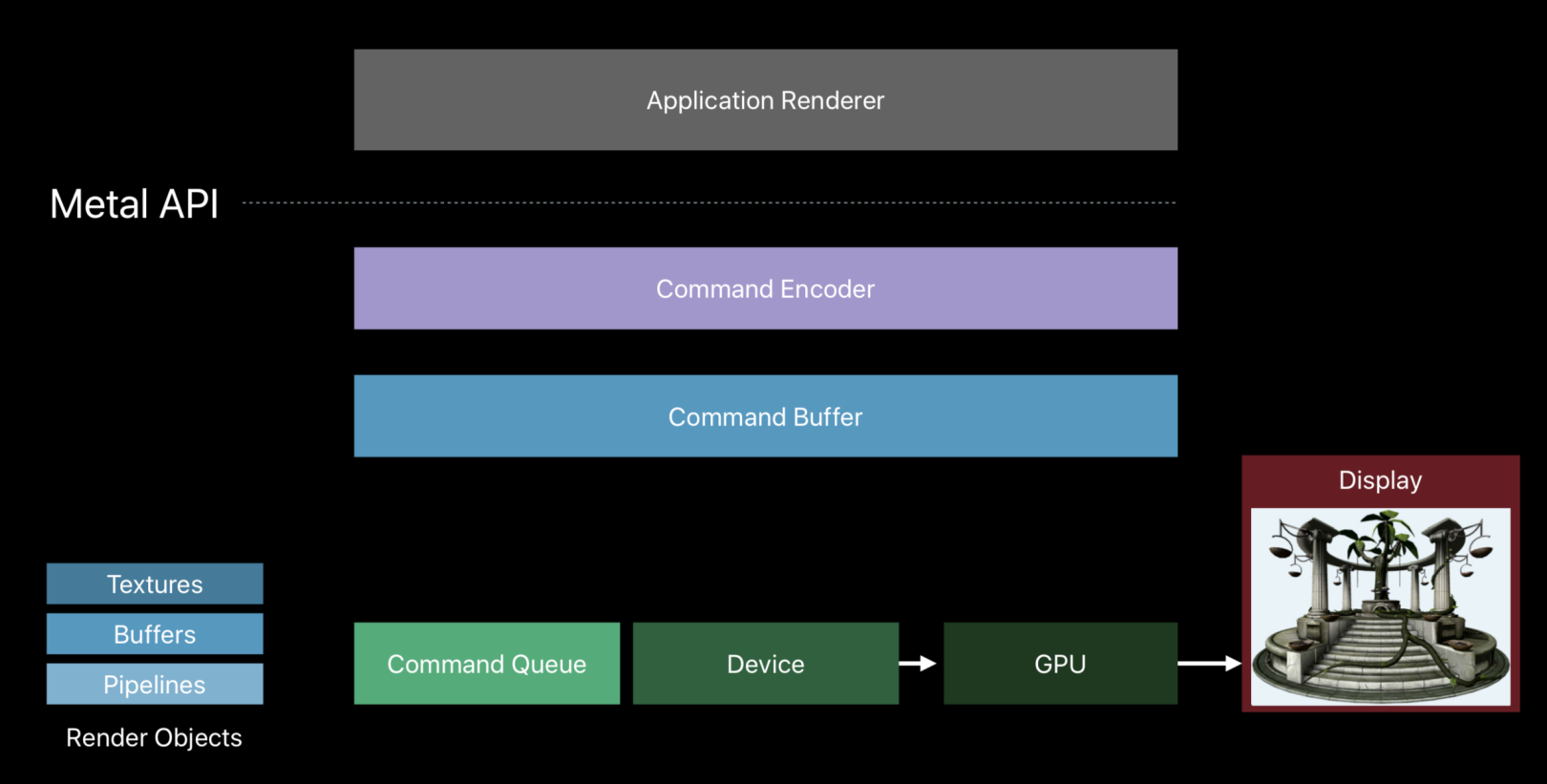
Metal的关系图
Metal的关系图如上,其中的Device是GPU设备的抽象,负责管道相关对象的创建:
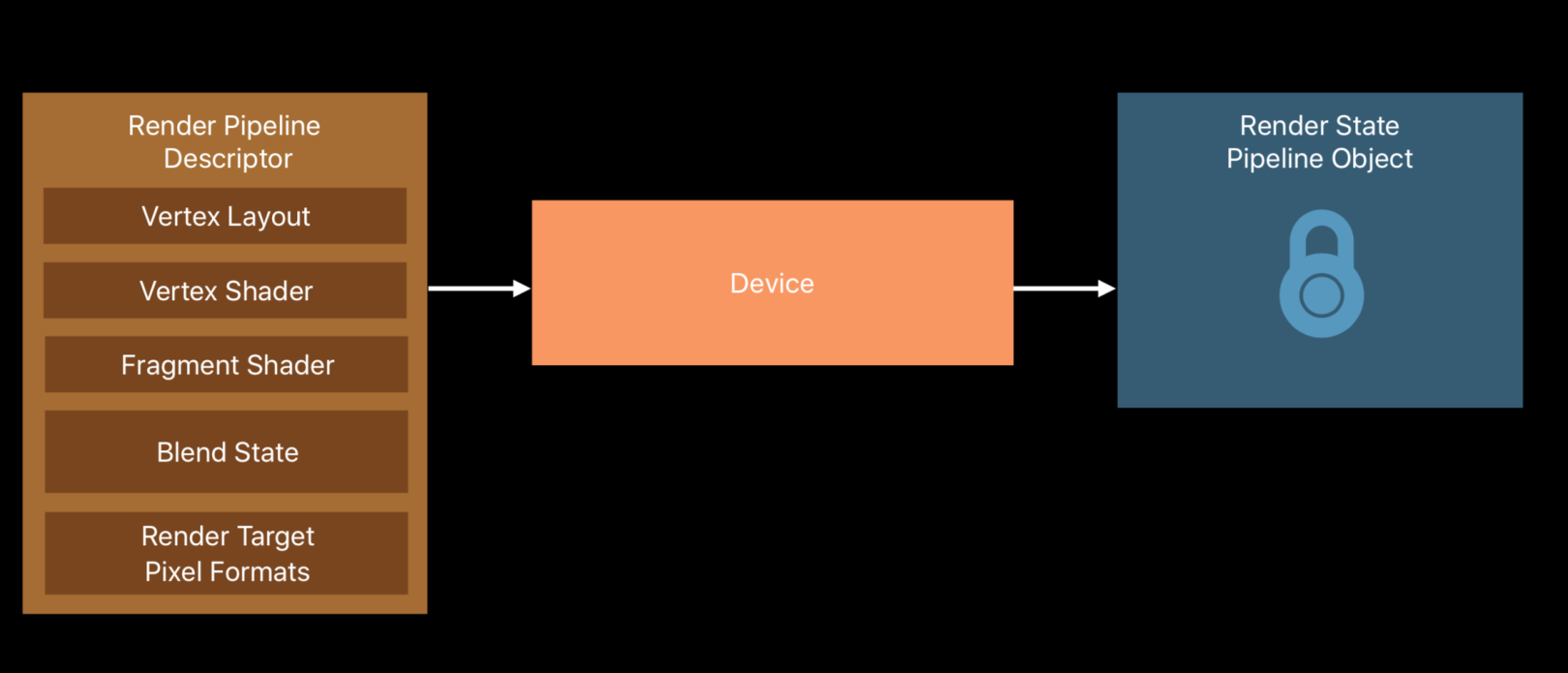
Device
Metal和OpenGL ES的代码对比
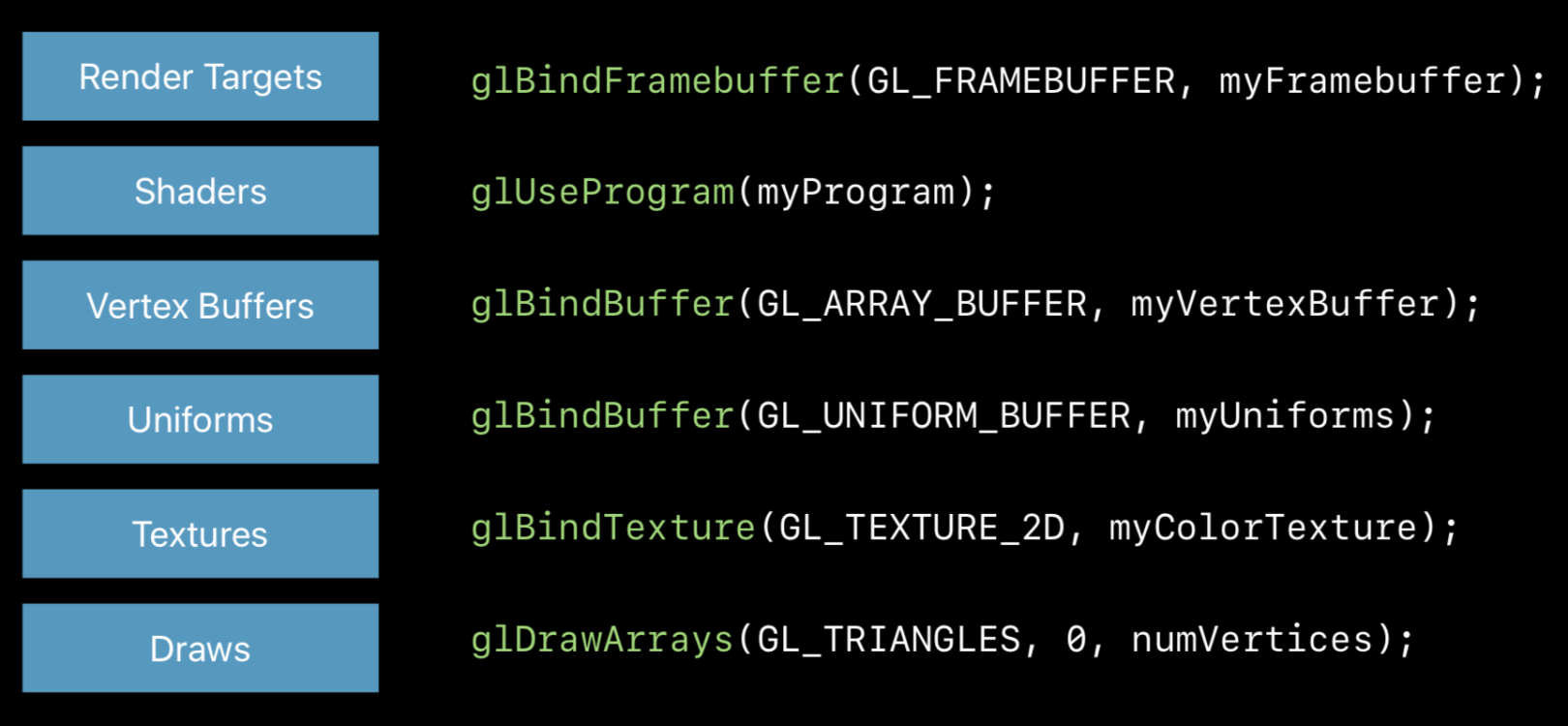
我们先看一段OpenGL ES的渲染代码,我们可以抽象为Render Targets的设定,Shaders绑定,设置Vertex Buffers、Uniforms和Textures,最后调用Draws指令。
glBindFramebuffer(GL_FRAMEBUFFER, myFramebuffer);
glUseProgram(myProgram);
glBindBuffer(GL_ARRAY_BUFFER, myVertexBuffer);
glBindBuffer(GL_UNIFORM_BUFFER, myUniforms);
glBindTexture(GL_TEXTURE_2D, myColorTexture);
glDrawArrays(GL_TRIANGLES, 0, numVertices);
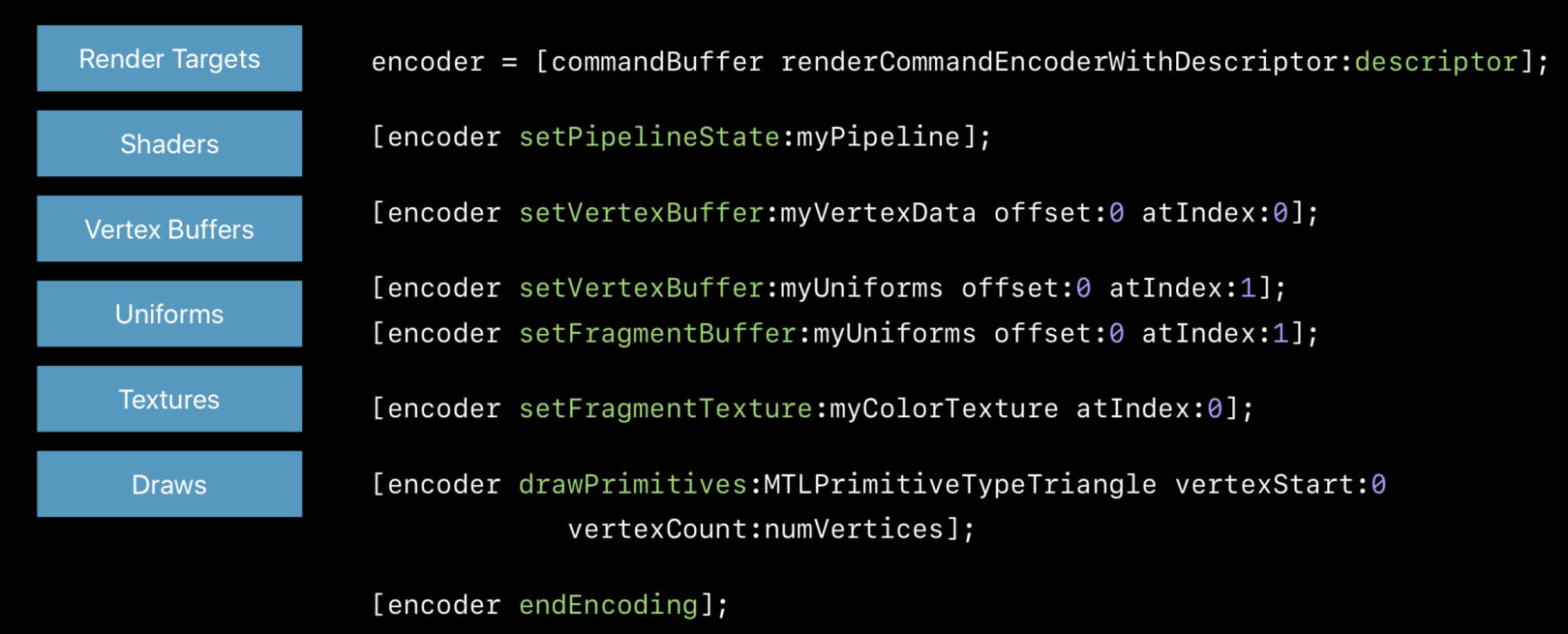
再看Metal的渲染代码: Render Targets设定 是创建encoder; Shaders绑定 是设置pipelineState; 设置Vertex Buffers、Uniforms和Textures 是setVertexBuffer和setFragmentBuffer; 调用Draws指令 是drawPrimitives; 最后需要再调用一次endEncoding。
encoder = [commandBuffer renderCommandEncoderWithDescriptor:descriptor]; [encoder setPipelineState:myPipeline];
[encoder setVertexBuffer:myVertexData offset:0 atIndex:0];
[encoder setVertexBuffer:myUniforms offset:0 atIndex:1];
[encoder setFragmentBuffer:myUniforms offset:0 atIndex:1];
[encoder setFragmentTexture:myColorTexture atIndex:0];
[encoder drawPrimitives:MTLPrimitiveTypeTriangle vertexStart:0 vertexCount:numVertices];
[encoder endEncoding];
Metal和OpenGL ES的同异步处理
如下图,是用OpenGL ES实现一段渲染的代码。CPU在Frame1的回调中写入数据到buffer,之后GPU会从buffer中读取Frame1写入的数据。
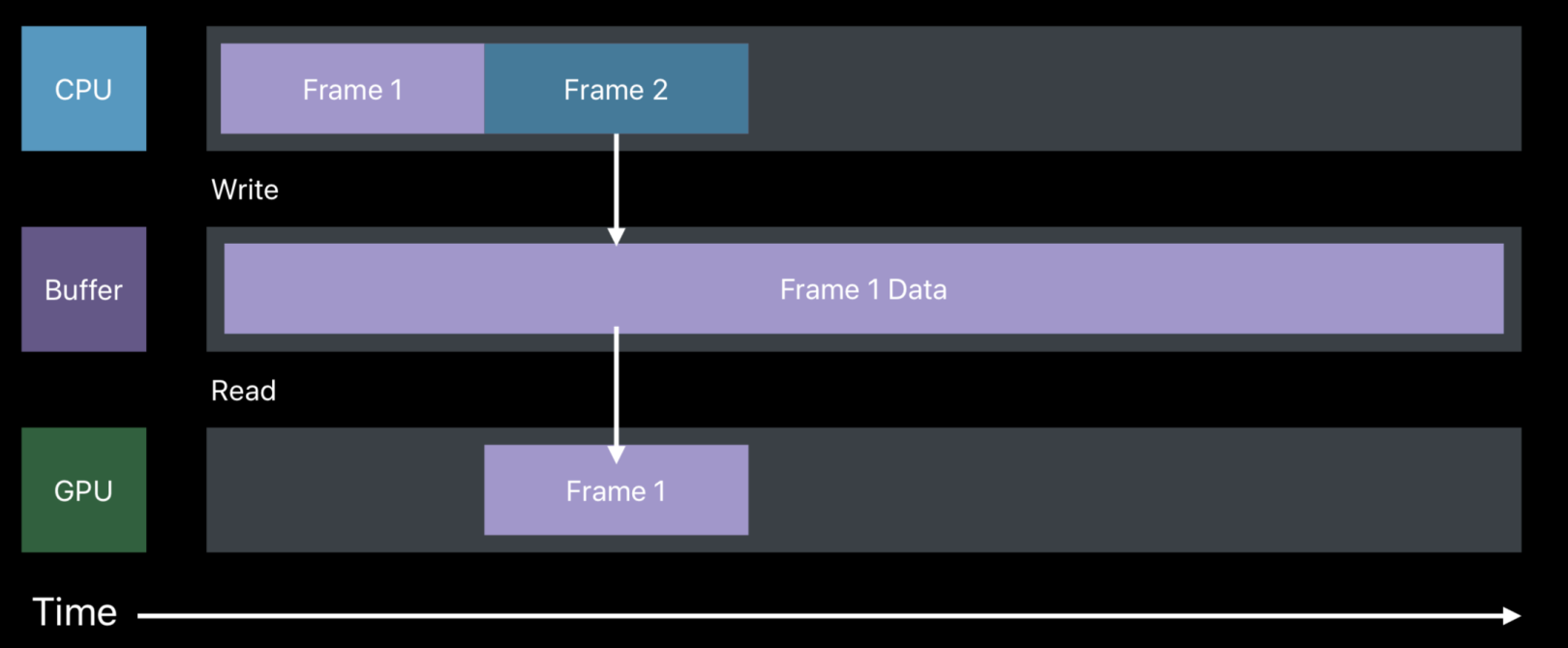
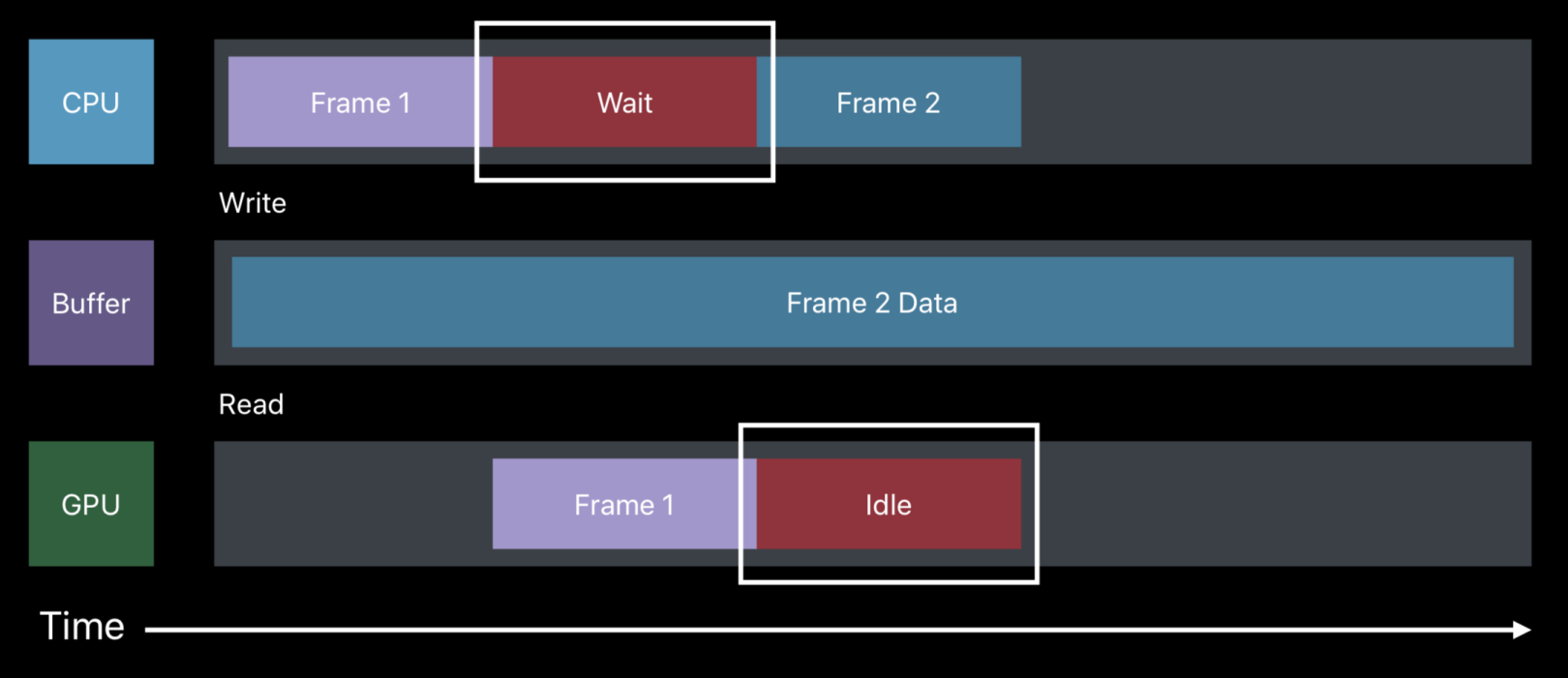
但在Frame2 CPU在往Buffer写入数据时,Buffer仍存储着Frame1的数据,且GPU还在使用该buffer,于是Frame2必须等待Frame1渲染完毕,造成阻塞。如下,会产生CPU的wait和GPU的idle。
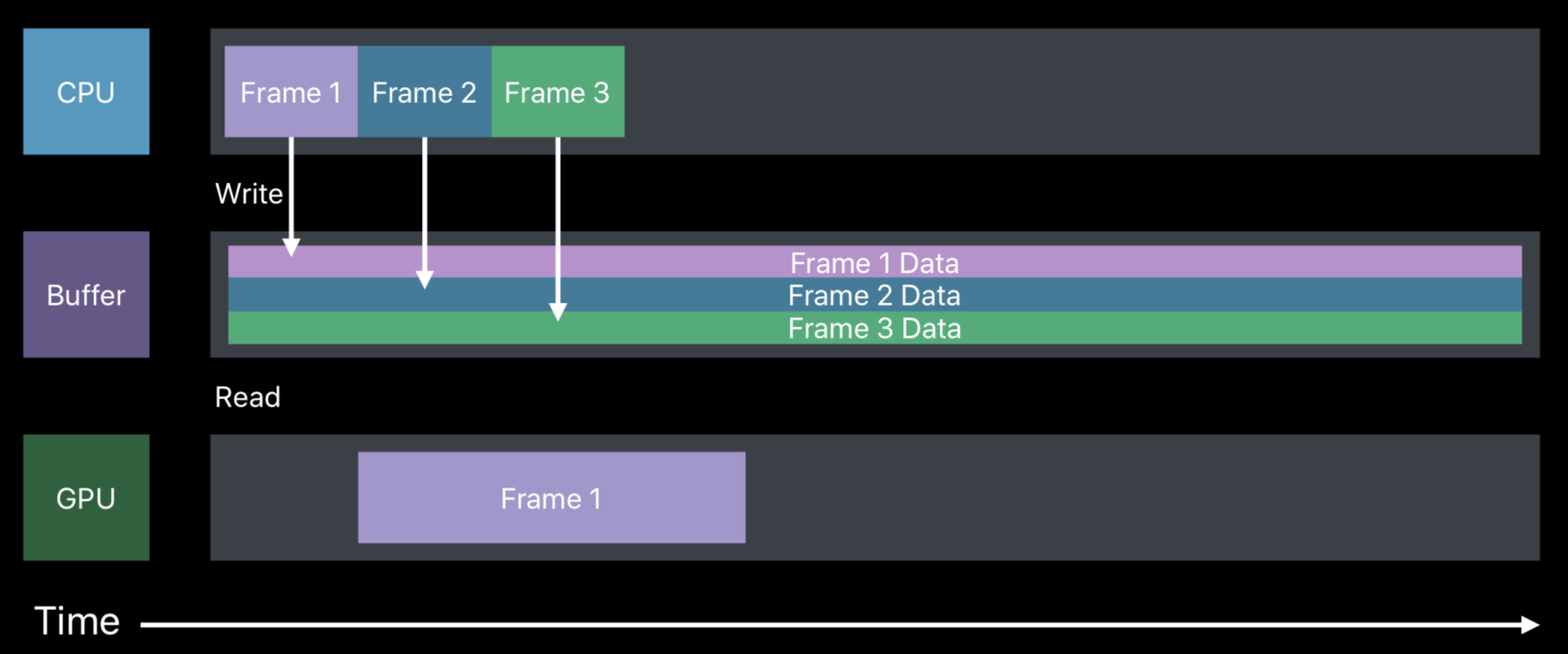
Metal的处理方案会更加高效。如下图,Metal会申请三个buffer对应三个Frame,然后根据GPU的渲染回调,实时更新buffer的缓存。 在Frame2的时候,CPU会操作Buffer2,而GPU会读取Buffer1,并行操作以提高效率。
总结
Metal系列入门教程介绍了Metal的图片绘制、三维变换、视频渲染、天空盒、计算管道、Metal与OpenGL ES交互。结合本文的总结,能对Metal产生基本的认知,看懂大部分Metal渲染的代码。 接下来的学习方向是Metal进阶,包括Metal滤镜链的设计与实现、多重colorAttachments渲染、绿幕功能实现、更复杂的通用计算比如MPSImageHistogram,Shader的性能优化等。
此文已由作者授权腾讯云+社区发布,更多原文请点击
搜索关注公众号「云加社区」,第一时间获取技术干货,关注后回复1024 送你一份技术课程大礼包!
海量技术实践经验,尽在云加社区!
