

- 原文地址:Building a Text Editor for a Digital-First Newsroom
- 原文作者:Sophia Ciocca
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:diliburong
- 校对者:Park-ma
为数字优先新闻编辑室开发文本编辑器
内观一个你可能认为理所当然的技术内部运作

Aaron Krolik / 纽约时报的插图
如果你和美国的大多数人一样,几乎每天都会使用某个文本编辑器。无论是基本的 Apple Notes,还是像 Google Docs、Microsoft Word 或 Mediumz 等更高级的东西,我们的文本编辑器都允许我们记录和呈现我们重要的想法和信息,使我们能够以最吸引人的方式讲述故事。
但是你可能没有想过这些文本编辑器的后台运作原理。每次你按下某个键时,可能会执行数百行的代码来在页面上呈现你想要的字符。看似很小的操作,例如拖动选择文本中的几段文字或将文本转换为标题,这实际上会触发程序系统底层的大量变化。
虽然你可能无需考虑为这些复杂的文本编辑操作提供动力的代码,但我在纽约时报的团队确不断在思考它。我们的主要任务是为新闻工作室创建一个高度定制的报道编辑器。除了输入和呈现内容的基础功能之外,这个新的报道编辑器需要将 Google Docs 的高级特性与 Medium 的直观设计重点结合起来,并且添加新闻室工作流程独有的许多功能特性。
多年以来,纽约时代报新闻编辑室使用了一个传统的自制文本编辑器,它并没有满足其众多需求。虽然我们的旧版编辑器非常适合新闻编辑室的生产工作流程,但它的用户界面还有许多不足:它严重的分隔了工作流程,将报道的不同部分(例如文本、照片、社交媒体和文案编辑)分离成应用程序的完全不同的部分。因此,要在这个较老的编辑器中生成一片文章需要浏览一系列冗长的、非直观的,并且视觉上没有吸引力的标签。
除了使用户的工作流程碎片化之外,传统的编辑器在工程方面也造成很大的痛苦。它依赖于直接操作 DOM 来在编辑器中呈现所有内容,例如添加各种 HTML 标记以表示已删除文本,新文本和注释之间的区别。这意味着其他团队的工程师必须在文章发布并呈现到网站之前对文章进行大量严格的标记清理,将会是一个耗时并且容易出错的过程。
随着新闻编辑室的发展,我们设想了一个新的报道编辑器,它可以直观的将报道的不同组成部分内联,这样记者和编辑都可以在发布前准确的看到报道的样子。另外,理想情况下,新的方法在其代码实现中更加直观和灵活,避免了旧版编辑器的许多问题。
考虑到这两个目标,我的团队开始开发这个新型文本编辑器,并将其命名为 Oak。经过大量研究和数月的原型设计,我们选择在 ProseMirror 的基础上开发它。ProseMirror 是一个用于构建富文本编辑器的强大开源 JavaScript 工具包,它采用了和我们旧版编辑器完全不同的方法,使用它自己的非 HTML 树形结构 来表示文档,该结构由段落、标题、列表和连接等来描述文本的构成。
与我们旧版的编辑器所不同的是,基于 ProseMirror 开发的文本编辑器的输出可以最终可以呈现为 DOM 树、Markdown 文本或任何其他可以表达其编码概念的其他格式,使它非常通用并且解决许多我们在旧版文本编辑器上遇到的问题。
那么 ProseMirror 究竟是如何工作的呢?让我们赶快深入它背后的技术。
一切都是节点
ProseMirror 将其主要元素 — 段落、标题、列表、图片等 — 构造为节点。许多节点都可以具有子节点,例如 heading_basic 节点可以具有包括 heading1 、byline、timestamp 和 image 等子节点。这构成了我上面所提到的属性结构。
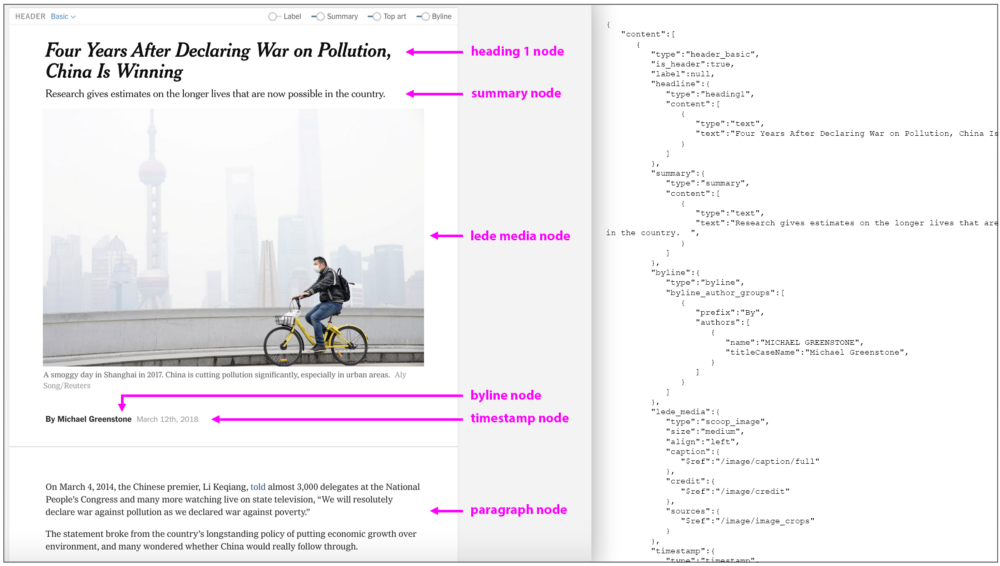
这种树状结构有趣的例外在于段落节点编纂文本的方式。考虑由以下句子组成的段落,“This is strong text with emphasis”。
DOM 会将该句子编成树,如下所示:

句子的传统 DOM 表示 — 其标签以嵌套的树状方式工作。来源:ProseMirror
但是,在 ProseMirror 中,段落的内容表示为一个扁平的内联元素序列,每个元素都有自己的样式

ProseMirror 如何构造相同的句子。来源:ProseMirror
扁平化的段落结构有一个有点:ProseMirror 依据其数字位置来追踪每个节点。因为 ProseMirror 将上面示例中的斜体和粗体字 "emphasis" 识别为其自己的独立节点,所以它可以将节点的位置表示为简单的字符偏移,而不是将其视为文档树中的位置。例如,文本编辑器可以知道 "emphasis" 一词从文档的 63 位开始。这使得选择、查找和使用更加容易。
所有的这些节点 — 段落、标题、图像等 — 具有它们相关联的某些特征,包括大小、占位符和可拖动性。在某些特定节点(如图像或视频),它们还必须包括 ID 以便媒体文件能够在较大的 CMS 环境中被找到。Oak 是如何知道所有这些节点功能的呢?
为了告诉 Oak 特定节点是怎么样的,我们使用“节点规范”来创建它,它是一个定义了文本编辑器需要理解并正确使用节点的自定义方法或行为的类。接着我们定义一个适用于编辑器中所有节点的 schema,并且表明了每个节点在整个文档中能够被允许放置的位置。(例如,我们不希望用户在页眉中放置嵌入式推文,因此我们在模式中禁止它。)在 schema 中我们列出了所有在 Oak 环境中存在的节点以及他们之间的关联方式。
export function nytBodySchemaSpec() {
const schemaSpec = {
nodes: {
doc: new DocSpec({ content: 'block+', marks: '_' }),
paragraph: new ParagraphSpec({ content: 'inline*', group: 'block', marks: '_' }),
heading1: new Heading1Spec({ content: 'inline*', group: 'block', marks: 'comment' }),
blockquote: new BlockquoteSpec({ content: 'inline*', group: 'block', marks: '_' }),
summary: new SummarySpec({ content: 'inline*', group: 'block', marks: 'comment' }),
header_timestamp: new HeaderTimestampSpec({ group: 'header-child-block', marks: 'comment' }),
...
},
marks:
link: new LinkSpec(),
em: new EmSpec(),
strong: new StrongSpec(),
comment: new CommentMarkSpec(),
},
};
}
使用Oak环境中存在的所有节点的列表以及它们彼此之间的关系,ProseMirror 可以在任何时间点创建文档模型。此模型是一个对象,与最顶层插图中示例采用 Oak 编辑的文章旁边显示的 JOSN 结构非常相似。当用户编辑文章时,该对象将不断被包含编辑内容的新对象替换,以确保 ProseMirror 始终知道文档包含的节点信息来在页面上呈现内容。
说到这里,每当 ProseMirror 知道节点在文档树中如何组合之后,它又是如何那些节点是什么样子又或如何实际在页面上显示它们?要将 ProseMirror 的状态映射到 DOM,每个节点都有一个开箱即用的简易方法 toDOM() 用来将节点转化为基本的 DOM 标签。例如,Paragraph 节点的 toDOM() 方法会将它转化为 <p> 标签,而 Image 节点会被转化为 <img> 标签。但是由于 Oak 需要自定义节点来做一些特殊的事务,我们的团队利用 ProseMirror 的 NodeView 功能来设计一个用来以特殊方式渲染节点的自定义 React 组件。
(注意:ProseMirror 与框架无关,NodeView 可以使用任何前端框架创建。我们的团队使用 React)
跟踪文本样式
如果创建的节点具有通过 ProseMirror 从其 NodeView 获取的特定视觉外观,那么其他用户添加的样式(例如粗体和斜体)改如何生效?这里就是 marks 标记的用处,或许你已经在上面的构架代码块中注意到它。
我们声明了 schema 中的所有节点之后,紧接着定义每个节点允许具有的 marks 类型。在 Oak 中我们为一些节点支持某些 marks,而另一些节点却不支持。例如,我们在小标题节点中允许斜体和超链接,但在大型标题节点中都不允许。对给定节点的 marks 将会保存在 ProseMirror 的当前文档状态中。我们也使用 marks 用于实现自定义批注功能,这将在下文介绍。
编辑功能的幕后工作原理?
为了在任何给定时间呈现文档的准确版本并跟踪版本历史记录,我们记录用户更改文档的几乎所有操作非常重要。例如,按下 “s” 或者回车键,又或插入一张图片。ProseMirror 将每一个这些微小的变化称为一个 step。
为了确保 app 的所有部分同步并显示最新数据,文档的 state 是不可变的。这就意味着通过简单地编辑现有数据对象,不会发生对 state 的更新。ProseMirror 接受旧对象,并将其与 step 对象合并以达到一个全新状态。(对于一些熟悉Flux概念的人来说,这可能很熟悉。)
此流程可以鼓励更加清晰的代码同时也能够留下更新的痕迹,从而实现一些编辑器包括版本比较在内的重要功能。我们在 Redux store 中追踪这些 steps 以及它们的顺序,从而使用户能够在版本之间随意切换,轻松实现回滚或前滚更改,并查看不同用户所做的编辑:
我们的版本比较功能依赖于仔细跟踪在不可变的 Redux state 下的每个事务。
我们开发的一些炫酷的功能
ProseMirror 是有意模块化和可模块化的,这意味着实现其他功能需要大量自定义定制。这对我们来说再好不过了,因为我们的目标就是开发一个满足新闻编辑室特殊需求的文本编辑器。我们团队开发的一些最有趣的功能包括:
跟踪变化
就像上面展示的一样,我们的“跟踪变化”功能可以说是 Oak 最先进最重要的功能。由于新闻编辑室的文章涉及记者和其他各种编辑之间的复杂流程,因此能够跟踪不同用户对文档所做的更改以及何时更改是非常重要的。此功能很大程度上依赖对每个事务的仔细跟踪,并将它们每一个存入数据库中。然后在文档中用绿色来标记新增的内容,红色来标记删除的内容。
自定义标题
Oka 的目标之一是成为一个以设计为中心的文本编辑器,让记者和编辑能够以最适合任何给定故事的方式呈现视觉新闻。为此,我们创建了自定义标题节点,其中包括了水平和垂直的全屏图像。Oak 中的这些标题是有着特殊 NodeViews 和 schemas 的节点来允许它们包含署名、时间戳、图像和其他嵌套的节点。对于用户而言,所编辑时的标题是在面向读者的网站上发表的文章的标题的写照,使记者和编辑尽可能接近地表示文章在实际纽约时报网站上发布时的样子。

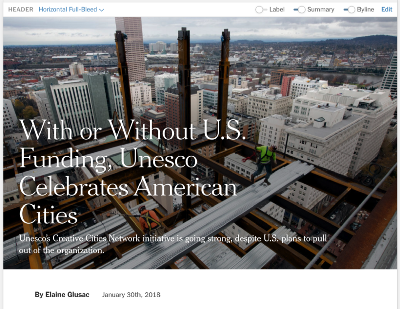
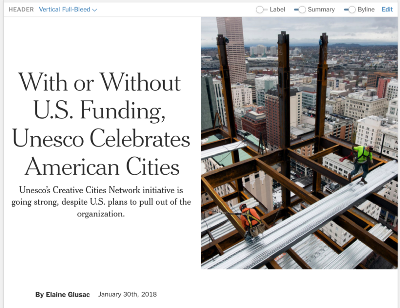
一些 Oak 的标题选项。从左到右:基本标题,水平全屏标题,垂直全屏标题。
批注功能
评注是新闻编辑工作流程的重要组成部分。编辑需要与记者交流,提出问题并给出建议。在我们旧版编辑器中,用户被迫将他们的批注与文章文本一起直接放入文档中,经常会使文章看起来非常杂乱并且容易被遗漏。对于 Oak,我们团队开发了一个复杂的 ProseMirror 插件能够将批注在文章右侧显示。在底层,批注实际上使一种 mark,它使文本的附注像粗体、斜体、或者超链接一样,区别仅仅在于展现的样式。

在Oak中,批注是一种 mark,不过显示在相关文本或节点的右侧。
自从它的构思以来,Oak已经走过了漫长的道路,我们很高兴能为开始从旧版编辑器转换的新闻工作室继续开发新功能。我们计划开始开发协同编辑功能,能够允许多个用户同时编辑文章,这将从根本上改善记者和编辑的合作方式。
文本编辑器的复杂程度比许多人所知道的都要高。我为能够成为 Oak 团队的一员来开发这样的工具感到荣幸。作为作者,我觉得这个编辑器非常有趣,并且它对世界上最大和最有影响力的新闻编辑室之一的运作也非常重要。感谢我的经理 Tessa Ann Taylor 和 Joe Hart,以及在我来到这之前已经在 Oak 工作的我们团队:Thomas Rhiel、Jeff Sisson、Will Dunning、Matthew Stake、Matthew Berkowitz、Dylan Nelson、Shilpa Kumar、Shayni Sood 以及 Robinson Deckert。我很幸运能有这么棒的队友让 Oak 这一魔术编辑器诞生。谢谢。
如果发现译文存在错误或其他需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
