


此文已由作者叶富宏授权网易云社区发布。
欢迎访问网易云社区,了解更多网易技术产品运营经验。
昨天一个商务反馈说报价信息导出失败,查看了一下日志发现是导出记录到Excel的时候报了NullpointException异常。报错的是下面这个方法里面,标红的代码(dataRow为null)。
private void MergedRowRegion(Sheet sheet, int endRowNum, int rowNum){ if(endRowNum > rowNum){
Row dataRow = sheet.getRow(rowNum); for(int i=0; i< 8; i++){ Cell cell = dataRow.getCell(i);
if(cell != null){
sheet.addMergedRegion(new CellRangeAddress(rowNum, endRowNum, i, i));
}
}
}
}这个方法的作用是把从rowNum行到endRowNum的第1到第七列进行单元格合并。反复检查了好几遍代码和数据,除了发现数据量比较多以外,并没有发现有什么地方会造成dataRow为null的情况,通过调试终于发现了原因,现在就把这个问题记录一下。
简单说一下导出的业务:导出的信息包含商品、供应商和供应商报价。一个商品可以包含多个供应商信息,每个供应商可以有多个报价。Excel的格式如下:
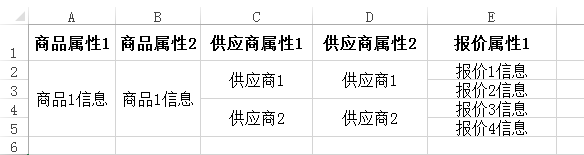
所以当一个商品对应多个供应商和报价的时候,需要对商品和供应商的信息进行合并单元格。往Excel写入数据的步骤是这样的:首先在第rowNum行写入商品信息、再写入供应商信息和报价信息并对供应商信息进单元格合并,然后返回最后所在的行号endRowNum,最后把endRowNum和rowNum传入上面的方法对商品属性进行单元格合并。报异常的那个商品总共有1739条报价,量有点多。
往Excel写入数据的时候,数据会先保存在SXSSFSheet的_rows里面,_rows是一个TreeMap<Integer, SXSSFRow>,Key是行(Row)的索引,从0开始1,2,3...递增,Value是对应的行数据。通过断点发现_rows里面的数据key是从739开始的740,741,742.....一直到1739总共1000条记录。放入1739条数据,里面只有后面的1000条。通过接下去的调试发现,当_rows里面的数据大于等于1000条的时候,如果再往里面插入一条数据,size依旧是1000,但是最前面的那条数据就被挤出去了(先进先出)。
查看了一下SXSSFSheet里面createRow的方法,找到了原因,代码如下:
public SXSSFRow createRow(int rownum) {
......
SXSSFRow newRow = new SXSSFRow(this, initialAllocationSize); this._rows.put(Integer.valueOf(rownum), newRow); this.allFlushed = false; if(this._randomAccessWindowSize >= 0 && this._rows.size() > this._randomAccessWindowSize) { try { this.flushRows(this._randomAccessWindowSize);
} catch (IOException var7) { throw new RuntimeException(var7);
} return newRow;
......
}参数rownum是行的下标,也是_rows的key,通过代码发现创建了新的一行以后,会调用 this.flushRows(this._randomAccessWindowSize);方法,通过方法名就能知道应该是刷新缓存之类的作用,flushRows方法的代码如下:public void flushRows(int remaining) throws IOException { while(this._rows.size() > remaining) { this.flushOneRow();
} if(remaining == 0) { this.allFlushed = true;
}
}flushOneRow方法的代码如下:private void flushOneRow() throws IOException { Integer firstRowNum = (Integer)this._rows.firstKey();//取出最小的key
if(firstRowNum != null) { int rowIndex = firstRowNum.intValue();
SXSSFRow row = (SXSSFRow)this._rows.get(firstRowNum); this._writer.writeRow(rowIndex, row);//
this._rows.remove(firstRowNum); this.lastFlushedRowNumber = rowIndex;
}
}通过代码可以看到,flushOneRow方法里会取出key最小的一条数据,写入文件中,然后从_rows中删除,让_rows一直维持在1000的大小。
这就解释了为什么放入了1739条数据,_rows中只有1000条,并且存在的都是后面的。
所以当调用sheet.getRow(rowNum)去取那些从_rows删掉的数据就会返回null。
从源码中可以看到,默认情况下_rows的size是保持在100的,而非1000.
public static final int DEFAULT_WINDOW_SIZE = 100;
public SXSSFWorkbook(XSSFWorkbook workbook, int rowAccessWindowSize, boolean compressTmpFiles,boolean useSharedStringsTable) { this._sxFromXHash = new HashMap(); this._xFromSxHash = new HashMap(); this._randomAccessWindowSize = 100; this._compressTmpFiles = false; this._sharedStringSource = null; this.setRandomAccessWindowSize(rowAccessWindowSize); this.setCompressTempFiles(compressTmpFiles);
.......可以通过构造函数进行修改:
public SXSSFWorkbook(int rowAccessWindowSize) { this((XSSFWorkbook)null, rowAccessWindowSize);
}更多网易技术、产品、运营经验分享请点击。
相关文章:
【推荐】 分布式存储系统可靠性系列五:副本放置算法 & CopySet Replication
