


 扫码关注微信公众号~"Kooola大数据"~一起聊人生
| 聊技术
扫码关注微信公众号~"Kooola大数据"~一起聊人生
| 聊技术
架构(Architecture)
如下图所示,Cloudera Manager 的核心是 Cloudera Manager Server(以下简称Server)。Server 托管管理控制台 web 服务和应用程序逻辑,并负责软件的安装、配置、服务的启动与关闭以及管理集群。
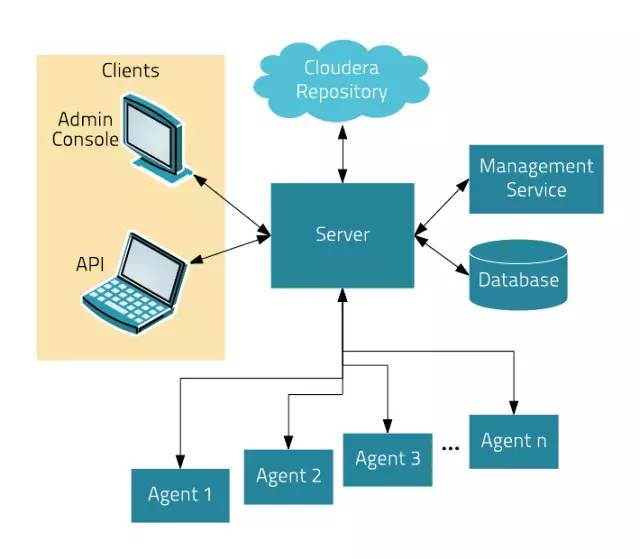
Server 和其他一些组件共同工作:
-
Agent - 安装在每台主机上。Agent 负责进程的启动和停止,解压配置,触发安装以及监视主机。
-
Management Service - 由一组角色组成的服务,这些角色执行各种监视,警报和报告功能。
-
Database - 存储配置以及监控信息。通常情况下,多个逻辑数据库运行在一个或多个数据库服务器上。例如,Cloudera Manager Server 和 monitoring roles 使用不同的逻辑数据库。
-
Cloudera Repository - Cloudera Manager分发软件的存储库。
-
Clients - 与Server交互的接口
-
Admin Console - 管理员 web 界面版
-
API - 用于开发者创建 Cloudera Manager 程序
心跳(Heartbeating)
Heartbeats是Cloudera Manager中的主要通信机制。默认情况下,Agent 每15秒发送一次心跳给 Server。当然,这个心跳频率可以进行调整。
通过这个心跳机制,Agent 向 Server 汇报自己的活动。反过来,Server 会响应 Agent 的活动。Agent 和 Server 最终都会进行一些对帐。例如,如果你启动一个服务, Agent 尝试启动相应的进程,如果这个进程启动失败,Server会标记这个失败的启动命令。
状态管理(State Management)
Server 维护集群的状态。这个状态可以划分为两类:model 和 runtime, 二者都保存在 Server 的数据库中。
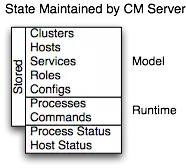
Cloudera Manager 为 CDH 建模以及管理服务:角色、配置以及内部依赖。模型告诉我们应该在什么地方运行什么以及使用什么样的配置。例如,模型状态捕获了一个事实,即一个集群包含17个主机,每个主机应该运行一个DataNode。你可以使用管理控制台的配置页或者 API 来操作模型,例如 "Add Service"。
Runtime 状态这个概念可以理解为:进程在哪里运行,什么命令正在运行等。在管理控制台页面中选择“启动”时,服务器将收集相关服务和角色的所有配置,对其进行验证,生成配置文件并将其存储在数据库中。
当你更新配置(例如更改 Hue Server 的 web 端口),你就更新了 Model 状态。然后, 当 Hue 正在运行时改变端口,它仍然会使用老的端口。当这种情况发生时,角色会被标记为拥有一个“过时的配置”。为了达到同步,你必须重启角色(触发配置文件重新生成以及进程重启)。
配置管理(Configuration Management)
Cloudera Manager 定义了几个配置级别:
-
服务级别(service level): 针对整个服务实例的配置,例如 HDFS 服务默认的复制因子(dfs.replication)。
-
角色组级别(role group level): 应用到角色成员的配置,例如 Datanode 的句柄数(dfs.datanode.handler.count)。针对不同的 Datanode,这个设置可能不同。例如,在性能更好的硬件上,这个值可以设置更大一些。
-
角色实例级别(role instance level): 这个级别的配置会覆盖继承自角色组的配置。这里需要谨慎使用,因为会导致与角色组配置之间存在差异。在一些特殊情况下可以使用,比如零时打开 debug 日志级别以发现并解决一些问题。
-
主机也有一些配置,比如配置监控、软件管理以及资源管理等。
-
Cloudera Manager本身具有与其自身管理操作相关的配置。
角色组(Role Groups)
你可以给服务实例(例如 HDFS)进行配置,也可以个角色实例(例如 host17上的 Datanode)进行配置。单个角色的配置从服务级别继承,并且如果角色上进行了配置,它将覆盖这个继承。这种机制提供了配置的灵活性,用户也不需要为每一个角色单独进行配置,减少繁杂的配置工作。
Cloudera Manager 支持角色组配置,这是一种将配置分配给一个角色组的机制。这样,组中各个角色都会继承这个配置。例如,在一个拥有不同性能主机组成的集群中,因为性能不同,我们可以为部署在其上的 Datanode 构建不同的配置组(性能好的配置高点,差的配置低点)。在性能高的一些主机上,我们为 Datanode组 运用配置A,性能低的一些主机上,我们运用配置B。
主机模板(Host Templates)
通常情况下,一些主机拥有相同的硬件,并且有相同的服务运行在上面。主机模板在集群中提供了一系列角色组,这样做有两个好处:
-
加入新主机到集群会变得简单 - 应用已经存在的角色组,简单的操作即可完成新主机的加入
-
对一些列主机进行角色的配置修改将变得简单 - 用户不需要一个个进行修改,用户可以快速的修改集群配置来应对不同的性能负载以及不同用户的需求
服务以及客户端配置(Server and Client Configuration)
用户有时会诧异,为什么修改 /etc/hadoop/conf 配置并重启 HDFS后并没有生效。这是因为使用 Cloudera Manager 启动服务实例并不是从默认位置的配置文件中读取。拿 HDFS 举例,不适用 Cloudera Manager 管理的话,通常每个主机上都需要进行配置,配置文件是 /etc/hadoop/conf/hdfs-site.xml。相同主机上的服务进程以及客户端将使用相同的配置。
Cloudera Manager 区分服务配置以及客户端配置。同样拿 HDFS 举例,/etc/hadoop/conf/hdfs-site.xml 文件中配置项适用于 HDFS 客户端。也就是说默认情况下,你运行一个需要跟 Hadoop 交互的程序时,它是从这个路径下拿到 NameNode、JobTracker 以及其他服务的配置项。同样,/etc/hbase/conf 和 /etc/hive/conf 情况也是一样。
对比之下,HDFS 角色实例(例如,Datanode 或 Namenode)则会从每个进程的私有目录中(/var/run/cloudera-scm-agent/process/unique-process-name)获取配置信息。给每个进程提供私有的运行以及配置环境,会使得 Cloudera Manager 能够独立地控制每个进程。例如,下面是 879-hdfs-NAMENODE 进程目录下的内容:
$ tree -a /var/run/cloudera-scm-Agent/process/879-hdfs-NAMENODE/
/var/run/cloudera-scm-Agent/process/879-hdfs-NAMENODE/
├── cloudera_manager_Agent_fencer.py
├── cloudera_manager_Agent_fencer_secret_key.txt
├── cloudera-monitor.properties
├── core-site.xml
├── dfs_hosts_allow.txt
├── dfs_hosts_exclude.txt
├── event-filter-rules.json
├── hadoop-metrics2.properties
├── hdfs.keytab
├── hdfs-site.xml
├── log4j.properties
├── logs
│ ├── stderr.log
│ └── stdout.log
├── topology.map
└── topology.py
区分服务配置和客户端配置有以下几个好处:
-
服务端配置中的一些敏感信息不会暴露给用户,例如用于存储 HIVE 元数据的数据库的密码。
-
一个服务依赖如另外一个服务,有时就需要这个依赖服务提供特定的版本。例如,为了获得 HDFS 更好的读性能,Impala 需要指定版本的 HDFS 客户端配置,但是这样做会影响其他通用的客户端访问。为了解决这个问题,我们可以将 HDFS 配置分为针对普通客户端(/etc/hadoop/conf)以及 Impala 客户端(Impala 进程私有的配置目录)。
-
客户端配置文件更小且更加已读。这也避免了一些不相关的配置项困扰 Hadoop 入门者。
