

0.背景
公司目前业务系统偏向后台系统,目前包含500W+数据,在许多列表中支持各种条件查询,含有大量的模糊搜索条件。由于在mysql中模糊查询效率低下,目前公司已使用es搜索引擎进行条件搜索。es版本如下:
elasticsearch版本:6.3.2
java client版本:rest-high-level-client 6.3.2
问题:业务需要部分中文字段进行a-z拼音排序。
1.实现方案
网上查阅资料,es使用elasticsearch-analysis-pinyin分词插件可实现排序效果。具体原理是通过拼音分词器将汉字分为只含有首字母的字符串(例如:刘德华----> ldh),之后通过查询此分词字段实现排序。
2.说干就干
2.1下载、安装拼音分词器
elasticsearch-analysis-pinyin下载网址:github.com/medcl/elast…
根据自己的es版本下载对应的拼音分词器版本,由于我的是6.3.2的版本,因此下载master版本的分词器。

解压zip包,命令行移动到解决后的包下,执行mvn 打包命令(没有maven的自行下载):
mvn打包命令: mvn package
看到 BUILD SUCCESS 即为打包成功。
此时,target目录已经生成,进入E:\Elasticsearch\elasticsearch-analysis-pinyin-master\target\releases目录下,解压里面的zip包,生成如下文件:
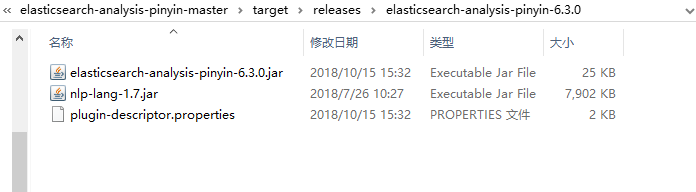
将这三个文件拷贝到es安装目录下的plugins目录下的pinyin文件夹中(pinyin文件夹需要自己创建,可以任意命名):
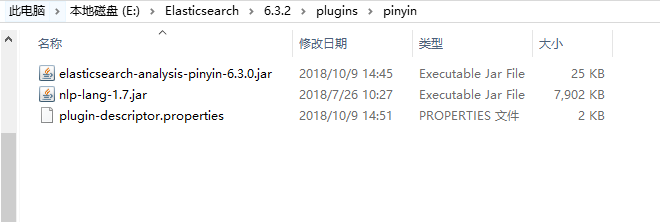
重启es,拼音分词器到此安装完成。
2.2索引setting、mapping设置
首先,创建索引时自定义索引setting:
由于我们需要将拼音分词器和ik分词器同时使用,因此在配置分析器时配置了两个。
PUT /pinyinTestIndex
{
"index" : {
"analysis" : {
"analyzer" : {
"default" : { //默认分词器使用ik分词器
"tokenizer" : "ik_max_word"
},
"pinyin_analyzer" : { //自定义拼音分词器
"tokenizer" : "my_pinyin"
}
},
"tokenizer" : {
"my_pinyin" : { //拼音分词器配置
"type" : "pinyin",
"keep_first_letter":true,
"keep_separate_first_letter" : false,
"keep_full_pinyin" : false,
"limit_first_letter_length" : 20,
"lowercase" : true,
"keep_none_chinese":false
}
}
}
}
}
在拼音分词器配置中含有几个配置,这些配置决定了能不能按照你的要求进行排序。
keep_first_letter:包含首字母,例如:刘德华> ldh,default:true。
keep_separate_first_letter:将字母分割,例如:刘德华> l,d,h,default:false。
keep_full_pinyin:包含全拼拼音,例如:刘德华> [ liu,de,hua],default:true。
limit_first_letter_length:设置first_letter结果的最大长度,default:16。
lowercase:小写非中文字母,default:true。
keep_none_chinese: 不在结果中保留非中文字母或数字,default:true。
因此,我的拼音分词器会有如下效果 -- 如果字符串为刘德华,经过分词后成为ldh,如果字符串为刘德华A,经过分词后成为ldha,如果字符串为刘德华1,经过分词后成为ldh1。此种分词效果满足我们的业务需求,当然还有其他的配置可选,来满足不同的业务需求。
其他配置可参考elasticsearch-analysis-pinyin下载网址中的README.md选项进行选取。
之后,进行索引mapping文件的建立,保证字段使用拼音分词器:
POST /pinyinTestIndex/dev/_mapping
{
"dev": {
"properties": {
"name": { //name字段
"type": "text", //字符串类型支持分词
"analyzer": "pinyin_analyzer", //使用拼音分词
"fields": { //包含的另一种不分词效果
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
到此,索引创建完毕。
2.3 使用java client排序查询
//search api
SearchSourceBuilder source = new SearchSourceBuilder();
//排序字段 SortOrder.ASC 升序 SortOrder.DESC 降序
source.sort("name", SortOrder.ASC);
//索引信息
SearchRequest searchRequest = new SearchRequest("pinyinTestIndex");
searchRequest.types("dev");
searchRequest.source(source);
//查询
SearchResponse response = client.search(searchRequest);
2.4 查看结果
升序效果:
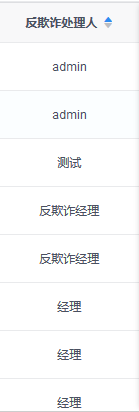
降序效果:
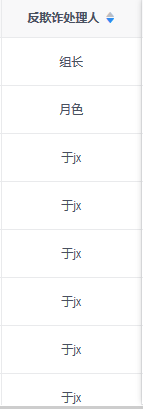
3.总结
实现拼音排序效果主要通过修改拼音分词插件的配置,根据个人不同的业务需求,修改增加配置选项,达到不同的查询效果。祝君好运。
