

这篇文章是以一个实习生的视角对前端网站架构的一点分析和理解
序
最开始接触前端的时候,是从简单的html、css、js开始的,当时盛行的WEB理念是结构样式行为相分离,即html、css、js分离,独立开发,互相之间通过link和script来互相调用。
最开始我所接触到的小项目,都是直接将html、css、js等静态资源直接部署到服务器上,然后根据请求路由响应不同的html文件即可。
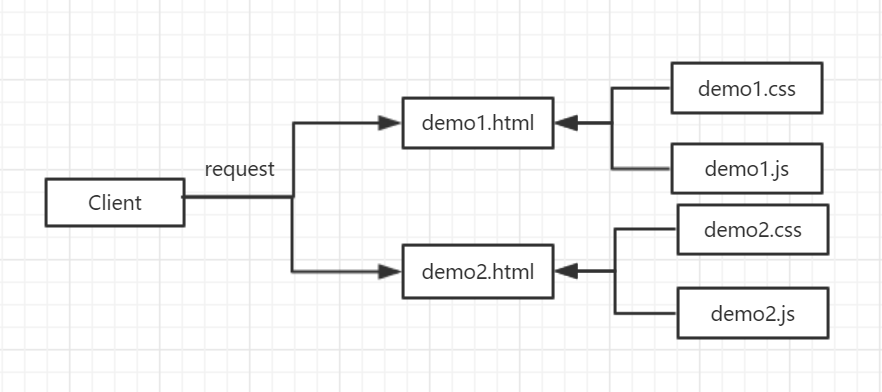
即使学习了webpack之后,我依然认为webpack的作用只是压缩js和css文件,提高服务器响应速度,优化用户体验,而部署到服务器上的依然是压缩后的min.css和min.js文件。
后来进入A公司实习之后,确实也是这种开发模式,当时我们开发h5页面,都是直接书写html、css、js文件,然后部署到服务器上,直接访问html即可。
后来进入B公司工作之后,才慢慢接触到真正的前端工程是什么样子的。
前后端分离
部分传统大型PC网站的业务前端部分都是采用的MVC架构方式,也就是每次立项之后,前后端约定好接口,分别开发,开发完毕之后,前端将开发好的页面交给后端(一般是Java或者PHP),然后由后端响应客户端请求,返回具体的html页面。
这种开发模式的缺点在于费时费力,沟通成本和联调正本非常高,前端有一点小的改动都需要前后端一起联调改动上线,大大增加了总工作量。
因此,现代大型PC网站一般都采用了前后端分离的架构方式,前端和后端的业务功能各自收敛,可以分别开发上线,互不影响,可以极大提高工作效率。
前后端分离一般分为两种:
- 没有中间层的前后端分离;
- 有中间层的前后端分离。 这里以目前最火的三大框架之一的react为主进行介绍。
无中间层 没有web中间层的前后端分离属于比较简单的类型,我们将一个统一的html/pug模板和其他的css、js等静态资源放置到cdn上,每次访问页面的时候,直接将模板返回给用户,然后里面所有的dom节点和其他数据都是由js来执行生成的。
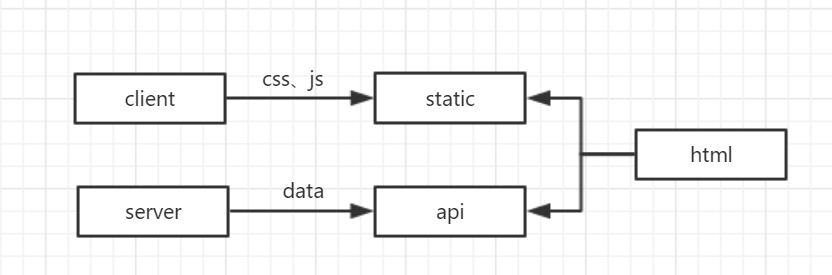
然而这种没有中间层的前后端分离的又有很多劣势:
- 首屏渲染时间过长;
- 对seo不友好。
- 有中间层
有中间层的前后端分离是一般大型项目采用的前后端分离方式。
自从2009年node横空出世之后,前端也逐渐承担了一些后端的业务,但是node由于自身健壮性的限制,又不适合作为大型项目的后端服务器,所以node热过一阵之后,逐渐成为了连接传统前端和后端的中间层,我们也称这种前端+node的架构为“大前端”。
返回模板 在node层中,我们可以做的事情就有很多了,其中最基础的就是返回不同的前端模板。
使用过几款前端模板,其中给我感觉最好的就是pug模板了(以前叫做jade)。
pug中的语法都是js语法,对前端工程师十分友好,而且pug功能很强大,可以作为html-middleware,被node完美支持,这里建议学习使用 Get Started。
数据拼接
其次,当网站发展地越来越大,数据量越来越多,对服务层进行分割的时候,会产生很多的服务模块,或者我们的数据分散在不同的数据库服务器上的时候,或者我们的前端页面中要嵌入第三方广告的一些api的时候,node就可以帮我们完成数据拼接的工作。
因为服务器访问接口的速度要比浏览器快很多个数量级,因此在node中访问多个接口并且拼接起来是非常高效的,拼接后的数据我们就可以直接传入模板中,供js使用了。
但是通常意义上来说,访问基础服务或者从数据服务器访问数据放在后端来做比较合适,但凡事总有例外,在万不得已的情况下,我们可以在node中间层中进行数据拼接。
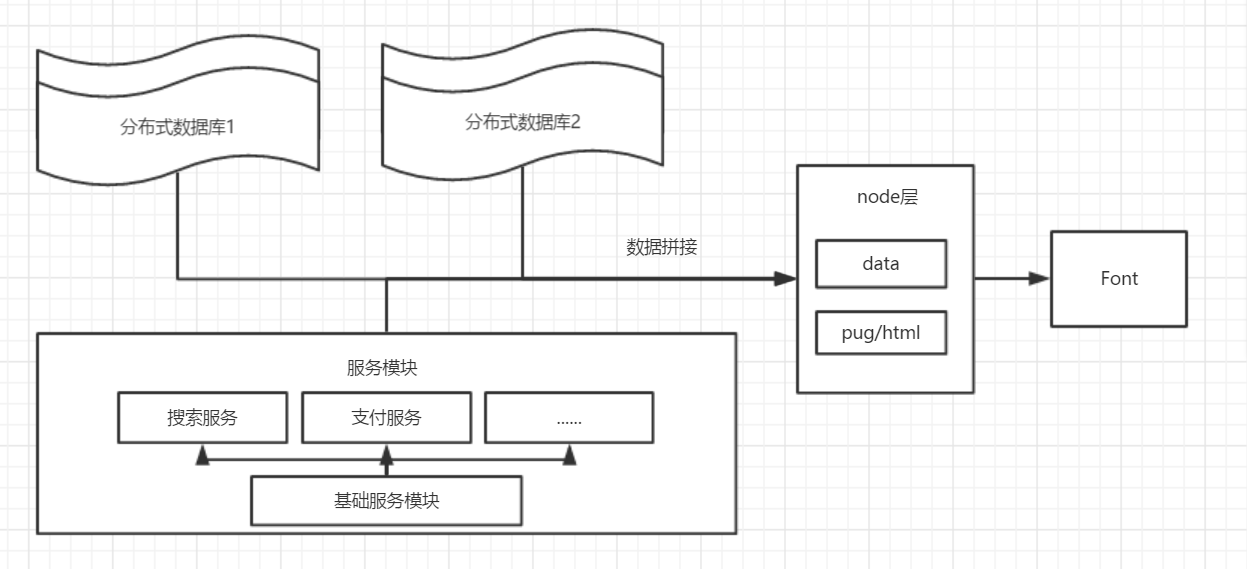
这种模式一般不提倡使用,因为可维护性太差,而且安全性也很低,一般情况下都是后端有一个专门的数据模块去访问数据库和服务,然后将数据拼接起来,我们只需要在node中调用后端的一个API,就可以拿到我们想要的数据了。
监控服务
node层可以捕捉一些异常请求或者事件,上报到我们的第三方监控平台,如Sentry等,同时node还可以承担一部分的数据统计的工作,将一些用户应为打到第三方数据统计平台,供pm和数据分析师查看。
node还可以承担对整个实例进行监控的职责,当出现异常导致cpu使用率或者内存使用率超过阈值之后就可以及时触发报警机制。
但是同样,加上node层就意味这网站又多了一层后端需要监控和oncall,工作的复杂度会上升很多。
服务器端渲染
SSR(server-side-render)可以说是非常重要的功能之一了,它可以帮助我们解决之前提到的首屏渲染时间过长和对seo支持较低的问题。
现代seo爬虫一般分为两种:
- 支持解析js的爬虫,这类数量较少,以Google为代表;
- 不支持解析js的爬虫,大部分都是这类,基本上都是非Google的搜索引擎的爬虫了。 对于Google的爬虫来说,是否使用SSR在seo方面无关紧要,因为最终都可以爬取到正常的页面。
而对于非Google的搜索引擎来说,我们就需要利用SSR,先将具体的dom节点渲染出来,供爬虫爬取。
而且这样同时还有一个优点:用户在网页loading的过程就中可以看到页面内容了,而不是一个空白页面。如果不使用SSR的话,在网页loading资源的过程中,一直呈现给用户一片空白,这就有可能造成用户的流失。
这张图是我在50kb/s的网速下,访问b站第一秒钟看到的内容,若是b站不使用SSR技术的话,可能等到用户能够看到首屏内容之后,时间都过去了五六秒。
这里是一个简单的使用SSR的Node层代码:
// 代码中使用了es6语法,不懂的可以先学习一下阮一峰老师的《ES6入门》
// 这个地方node如果没有使用babel的话,import会报错,可以直接使用require方法替换
import { renderToString } from 'react-dom/server';
import DemoContainer from 'containers/demo';
// 以koa2框架为例
module.exports = (ctx) => {
const props = {...};
// 这里的html就存放着我们组件render完之后的dom节点。
const html = renderToString(<Demo >);
// 这里以返回pug模板为例,第二个参数是要传入pug模板中的数据
ctx.render('demo.pug', {
__props: JSON.stringify(props),
html
});
};
这里是pug的代码片段:
// pug代码片段
body
#root
!{ html }
script.
window.__props = '!{ __props }'
使用SSR的时候要切记保证前端和服务器端的组件props保持一致,因此这里我的习惯是在node层将props直接传入window对象上,然后前端的组件直接从window对象获取props即可。
SSR的时候,React组件只会执行componentWillMount和render两个生命周期用来生成dom结构,其他的生命周期以及方法挂载都是在前端完成的。
node层的功能不止以上这些,这里就不过多展开介绍了。
虽然SSR的有点很多,但是还是有自身的弊端的。使用SSR就意味着你用自己服务器代替了一部分原本属于用户客户端的功能,因此会造成服务器性能降低,成本增高的可能,相对于小团队或者资金不算充裕的团队,要谨慎选择是否使用SSR。
前后端同构
说起SSR,就不得不提一下前后端同构问题。 同构的意思为前端和node用执行同一套代码,首屏使用服务端渲染,将渲染好的html直接交给浏览器去渲染,客户端负责加载js,执行组件剩余生命周期,并挂载自定义事件等。 一套好的前后端同构代码可以大幅减少我们维护代码的工作量,并且有十分高效的执行效率,如何优雅地书写前后端同构的代码也是一项技术活,需要我们提前规划好一套前端架构。
例如:
import React, { Component } from "react";
import { Provider } from "react-redux";
import ReactDOM from "react-dom";
import Loadable from "react-loadable";
import { BrowserRouter, StaticRouter } from "react-router-dom";
// server side render
const SSR = App =>
class SSR extends Component<{
store: any;
url: string;
}> {
render() {
const context = {};
return (
<Provider store={this.props.store} context={context}>
<StaticRouter location={this.props.url}>
<App />
</StaticRouter>
</Provider>
);
}
};
// client side render
const CLIENT = configureState => Component => {
const initStates = window.__INIT_STATES__;
const store = configureState(initStates);
Loadable.preloadReady().then(() => {
ReactDOM.hydrate(
<Provider store={store}>
<BrowserRouter>
<Component />
</BrowserRouter>
</Provider>,
document.getElementById("root")
);
});
};
export default function entry(configureState) {
return IS_NODE ? SSR : CLIENT(configureState);
}
并且在同构方面,阿里有一套降级策略。当服务器压力正常时,由服务器进行SSR,提高用户体验,当用户访问量激增,如双十一时,服务器会自动进行降级处理,node不进行SSR,全部转换成客户端渲染,减轻服务器的压力。
选择框架
了解了前后端分离之后,我们就要对node层进行框架选择了。
目前比较主流的框架有三款:Express、koa1.0、koa2.0。
对于初学者来说,建议直接使用koa2.0进行中间层的学习和开发。
express的缺点在于:
-
太重,有很多模块我们可能都不会用到; 回调地狱,即使使用Promise也只能缓解。 koa1.0的缺点在于:
-
必须配合
co库和generator来使用,配置繁琐。 而自从node升级到7.6版本以上,增加了async/await语法糖之后,我们就可以不需要任何三方库,直接在原生node中使用koa2的语法。
koa2是express的升级版框架,里面很多模块是直接从express中迁移过来的,但是又将以前不经常用到的模块删除,只有开发者在需要使用的时候采取引入那么模块。
并且koa2使用async/await语法糖之后,代码看似变成了同步执行,非常适合前端工程师的逻辑思维。
这里是express、promise、koa2的样例代码:
// express版本
module.exports = (req, res) => {
const data1 = request.get('/api/demo1', (err, res) => {
const data2 = request.get('/api/demo2', (err, res) => {
const data3 = request.get('/api/demo3', (err, res) => {
res.send(data1 + data2 + data3);
})
})
})
}
// promise版本
module.exports = (req, res) => {
new Promise((resolve, reject) => {
request.get('/api/demo1', (err, res) => {
resolve(res);
}).then(res => {
request.get('/api/demo2', (err, res2) => res + res2 );
}).then(res2 => {
request.get('/api/demo3', (err, res3) => res2 + res3)
}).then((data) => {
res.send(data);
});
})
}
看起来虽然整齐了一些,但是依然十分繁琐。
// koa1和koa2在写法上基本相同,区别在于koa1在使用之前要对co库和generator进行繁琐的配置。
// 每一个await的时候最好加上try-catch,防止因为一个异步请求失败而导致node进程崩溃,这里简化了写法。
module.exports = async (ctx) => {
const data1 = await request.get('/api/demo1');
const data2 = await request.get('/api/demo2');
const data3 = await request.get('api/demo3');
ctx.body = {
data: data1 + data2 + data3
};
}
koa2用起来非常的舒服,很适合前端工程师的思维逻辑。
虽然koa2的代码看起来像同步执行,但其实在编译之后只是变成了promise函数,await后面所有的代码都放到了promise的回调中执行了。
开发结构
选择好了框架之后,剩下的就只有开发了,一般的node层都遵循一下的目录结构:
node
- lib // 存放第三方插件
- util // 存放自己编写的工具函数
- middleware // 存放中间件
- routes // 存放路由
- controller // 存放路由处理函数
- app.js // node层入口文件 基本的node层架构这里就介绍差不多了,剩下的前端部分也一般是大家熟悉的东西。 前端目录结构:
public
- static
- src
- js
- components
- containers
- routes
- stores
- actions
- reducers
- pages
- css/scss/less
- static 这里按照正常的React开发逻辑去走即可。
最后还有一些其他的文件夹可以自由发挥,比如template存放模板,scripts存放平时写的脚本等。
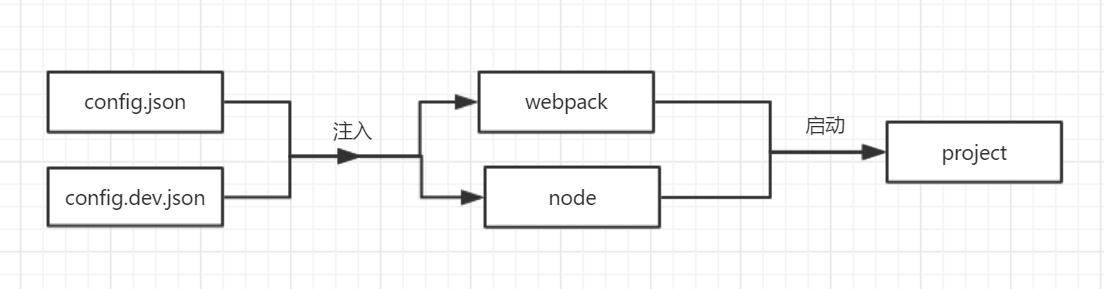
配置
一个线上项目要拥有两套模式——生产模式和开发模式。
生产模式即我们线上运行环境。
开发模式即我们平时本地开发环境。
如果有需要的话甚至可以配置更多的环境。
这两种环境的要求不一样,因此我们会有两套配置文件,将不同的配置文件传入node和webpack中,就可以根据配置的不同启动不同环境了。
自动化测试
自动化测试在一个成熟的大型网站中必不可少。
虽然目前因为前端领域的快速增长,业务层的自动化测试也因为业务的快速迭代而变得不稳定,但是一些基础的测试还是很有必要做的。
平时开发的时候要做好类库单元测试的自动化以及UI组件的单元测试的自动化。
这些测试文件最好存放在单独的test目录下,或者在每一个基础UI组件目录下加上component.test.js文件,这样启动测试的时候会自动找到.test文件进行测试。
每次项目上线之前都要进行一次集成测试,测试路由是否正常,webpack打包和node模块安装是否正常,模拟用户登录访问等操作是否正常。
偶尔我们还需要做压力测试和容灾测试等。
对于初学者来说,测试是一个很重要的概念和习惯,平时要多写一写单元测试。
