

一,前言
对于kubernetes基础性的知识,目前有很多资料,于是不会重复展开,想做一个对每个模块都深入讲解的系列,包括基础使用,源码解读,和实践中遇到的问题等,所以篇幅很比较长。
二,HPA模块
1,相关说明
(1) kubernetes版本:v1.9.2
(2) 适合对kubernetes基础有一定了解的人群
2,基本概念和使用
(1) 概念
HPA是kubernetes中自动水平扩展模块,基于用户设定和获取到的指标(CPU,Memory,自定义metrics),对Pod进行伸缩(不是直接操作pod)。HPA controller属于Controller Manager的一个controller。
(2) 基本使用
我们可以在pkg/apis/autoscaling 下可以看到,目前是有两个版本:v1(仅支持CPU指标),v2beta1(支持CPU和Memory和自定义指标)。下面看一下,一个比较全面的hpa的写法。
kind: HorizontalPodAutoscaler
apiVersion: autoscaling/v2beta1
metadata:
name: example-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: example-app
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 50
- type: Resource
resource:
name: memory
targetAverageUtilization: 50
- type: Pods
pods:
metricName: receive_bytes_total
targetAverageValue: 100
- type: Object
object:
target:
kind: endpoints
name: example-app
metricName: request_total
targetValue: 500m
3,源码分析
kubernetes中的代码都是有一定的“套路”(后面会专门写一篇来深入分析这种“套路”),我们首先从api入手,再到controller
(1) api
这是一个标准的kubernetes的api写法(可使用官方工具生成),register.go中添加了三个type:HorizontalPodAutoscaler/HorizontalPodAutoscalerList/Scale。接下来看types.go中关于这几个的定义。对应上面的yaml定义来看。
// 1,HorizontalPodAutoscaler
type HorizontalPodAutoscaler struct {
......
Spec HorizontalPodAutoscalerSpec
Status HorizontalPodAutoscalerStatus
......
}
// 用户设置的值
type HorizontalPodAutoscalerSpec struct {
MinReplicas *int32 //设置的最小的replicas
MaxReplicas int32 //设置的最大的replicas
Metrics []MetricSpec
}
// hpa的目前的状态
type HorizontalPodAutoscalerStatus struct {
ObservedGeneration *int64 //观察的最近的generaction
LastScaleTime *metav1.Time //上次伸缩的时间
CurrentReplicas int32 //目前的replicas数量
DesiredReplicas int32 //期望的replicas数量
CurrentMetrics []MetricStatus //最近一次观察到的metrics数据
Conditions []HorizontalPodAutoscalerCondition //在某个特定点的hpa状态
}
// Metrics定义
type MetricSpec struct {
Type MetricSourceType //metrics type
Object *ObjectMetricSource // Object类型的metrics定义
Pods *PodsMetricSource // pods类型的metrics定义
Resource *ResourceMetricSource // Resource类型的metrics定义
}
// 2,Scale 是resources的一次scaling请求,最后hpa都是要使用这个来实现
type Scale struct {
Spec ScaleSpec // 期望到达的状态
Status ScaleStatus // 目前的状态
}
(2) controller
api定义完后,需要有一个controller来保证系统的状态能符合我们定义的要求,这时候就需要hpa controller了,hpa controller通过从apiserver中获取各个指标的值,根据特定的伸缩算法,来维持在预期的状态。
上面说过,hpa controller属于controller manager,于是我们去cmd/kube-controller-manager下,经过一路跟踪,可以看到hpa controller的启动逻辑在options/autoscaling.go中
func startHPAController(ctx ControllerContext) (bool, error) {
// 需要包含v1版本
if !ctx.AvailableResources[schema.GroupVersionResource{Group: "autoscaling", Version: "v1", Resource: "horizontalpodautoscalers"}] {
return false, nil
}
// 如果要使用自定义metrics,需要开启该选项
if ctx.Options.HorizontalPodAutoscalerUseRESTClients {
return startHPAControllerWithRESTClient(ctx)
}
// 从Heapster拉取数据
return startHPAControllerWithLegacyClient(ctx)
}
func startHPAControllerWithMetricsClient(ctx ControllerContext, metricsClient metrics.MetricsClient) (bool, error) {
.......
// 核心参数,根据metrics计算相应的replicas
replicaCalc := podautoscaler.NewReplicaCalculator(
metricsClient,
hpaClient.CoreV1(),
ctx.Options.HorizontalPodAutoscalerTolerance,
)
// 新建HorizontalController
go podautoscaler.NewHorizontalController(
hpaClientGoClient.CoreV1(),
scaleClient, // scale相关客户端,实现最终的pod伸缩
hpaClient.AutoscalingV1(),
restMapper,
replicaCalc, // 副本计算器
ctx.InformerFactory.Autoscaling().V1().HorizontalPodAutoscalers(), //infomer
ctx.Options.HorizontalPodAutoscalerSyncPeriod.Duration, // hpa获取数据的间隔
ctx.Options.HorizontalPodAutoscalerUpscaleForbiddenWindow.Duration, // hpa扩容最低间隔
ctx.Options.HorizontalPodAutoscalerDownscaleForbiddenWindow.Duration, // hpa缩容最低间隔
).Run(ctx.Stop)
return true, nil
}
// 接下来看HorizontalController的定义
type HorizontalController struct {
scaleNamespacer scaleclient.ScalesGetter // 负责scale的get和update
hpaNamespacer autoscalingclient.HorizontalPodAutoscalersGetter // 负责HorizontalPodAutoscaler的Create, Update, UpdateStatus, Delete, Get, List, Watch等
mapper apimeta.RESTMapper
replicaCalc *ReplicaCalculator // 负责根据指标计算replicas
eventRecorder record.EventRecorder //event记录
upscaleForbiddenWindow time.Duration
downscaleForbiddenWindow time.Duration
// 从informer中list/get数据
hpaLister autoscalinglisters.HorizontalPodAutoscalerLister
hpaListerSynced cache.InformerSynced
queue workqueue.RateLimitingInterface
}
开始Run后,就是controller开发的那一套流程了,设计到相关的informer,workerqueue就不展开了,最关键的是下面的reconcileAutoscaler,其实就是通过一系列算法调节当前副本数,期望副本数,边界(最大最小)副本数三者的关系。(接下来分析可能比较长,只截取部分关键代码,注意看注释)
func (a *HorizontalController) reconcileAutoscaler(hpav1Shared *autoscalingv1.HorizontalPodAutoscaler) error {
// 通过namespace和name获取对应的scale
scale, targetGR, err := a.scaleForResourceMappings(hpa.Namespace, hpa.Spec.ScaleTargetRef.Name, mappings)
// 获取当前副本
currentReplicas := scale.Status.Replicas
rescale := true
// 副本为0,则不进行scale操作
if scale.Spec.Replicas == 0 {
desiredReplicas = 0
rescale = false
// 当前副本大于期望的最大副本数量,不进行操作
} else if currentReplicas > hpa.Spec.MaxReplicas {
rescaleReason = "Current number of replicas above Spec.MaxReplicas"
desiredReplicas = hpa.Spec.MaxReplicas
// 当前副本数小于期望的最小值
} else if hpa.Spec.MinReplicas != nil && currentReplicas < *hpa.Spec.MinReplicas {
rescaleReason = "Current number of replicas below Spec.MinReplicas"
desiredReplicas = *hpa.Spec.MinReplicas
}
// 当前副本为0也不进行操作
else if currentReplicas == 0 {
rescaleReason = "Current number of replicas must be greater than 0"
desiredReplicas = 1
}
// 当前副本数量处于设置的Min和Max之间才进行操作
else {
// 根据metrics指标计算对应的副本数
metricDesiredReplicas, metricName, metricStatuses, metricTimestamp, err = a.computeReplicasForMetrics(hpa, scale, hpa.Spec.Metrics)
rescaleMetric := ""
// 这里是防止扩容过快,限制了最大只能扩当前实例的两倍
desiredReplicas = a.normalizeDesiredReplicas(hpa, currentReplicas, desiredReplicas)
// 限制扩容和缩容间隔,默认是两次缩容的间隔不得小于5min,两次扩容的间隔不得小于3min
rescale = a.shouldScale(hpa, currentReplicas, desiredReplicas, timestamp)
}
// 如果上面的限制条件都通过,则进行扩容,扩容注意通过scale实现
if rescale {
scale.Spec.Replicas = desiredReplicas
_, err = a.scaleNamespacer.Scales(hpa.Namespace).Update(targetGR, scale)
} else {
desiredReplicas = currentReplicas
}
}
(3) 整套流程如下
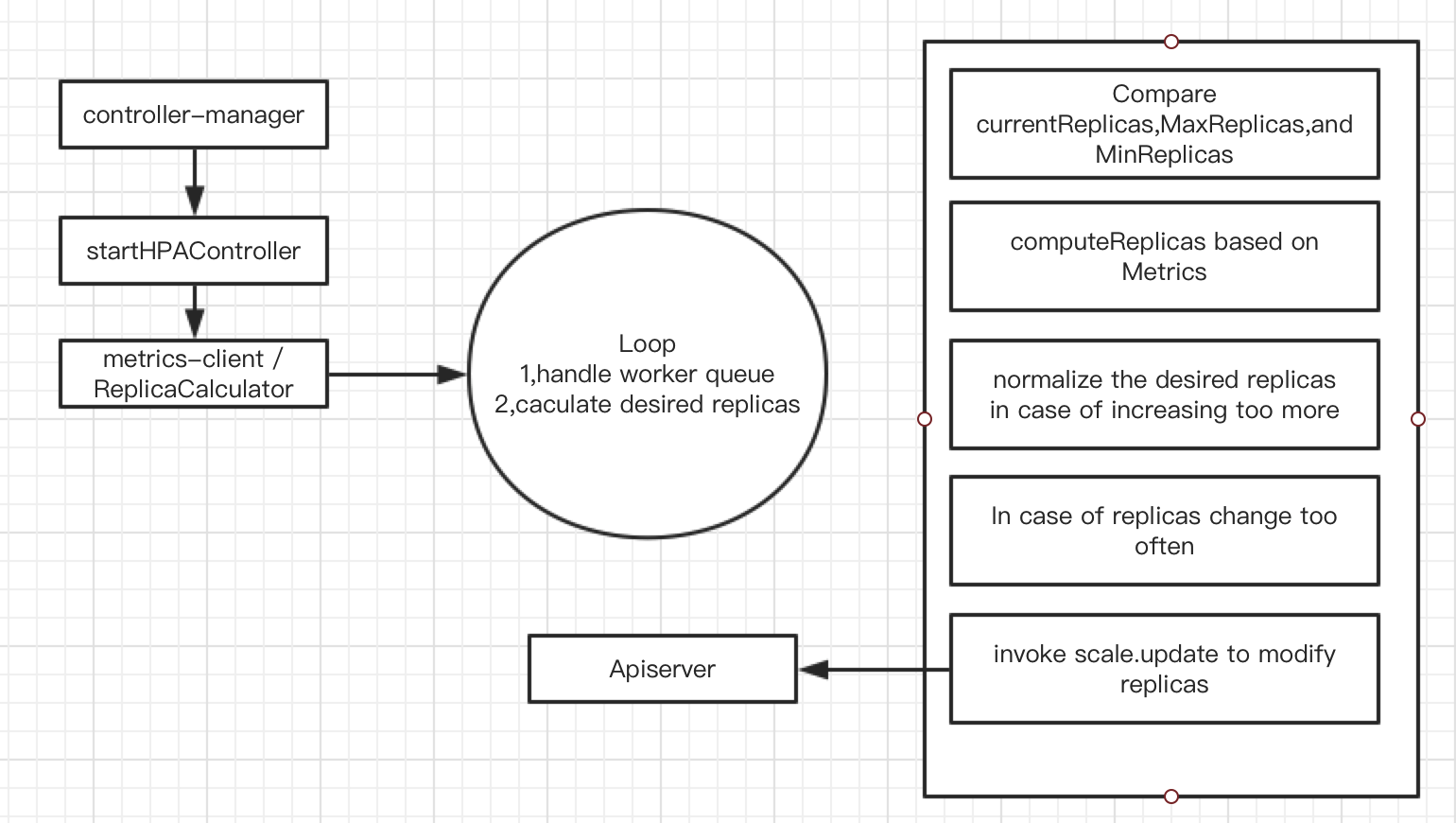
4,HPA实战经验
虽然说hpa能根据指标对pod进行弹性伸缩,达到根据使用量扩展机器的功能,但是,在实际运用中,我发现了以下的问题,希望能给要使用该模块的人带来一些启发。
(1) 问题详情
我们遇到了这样的一个业务场景:在某个时间段会突然流量剧增十倍,此时由于之前是处于低流量状态,replicas一直处于较低值,那么此时扩容由于扩容算法的限制(最多为2倍),此时扩容的数量是不足够的。然后,同样由于扩容算法的限制,两次扩容周期默认为不低于三分钟,那么将无法在短期内到达一个理想的副本数。此时从监控上看pod的数量图如下:
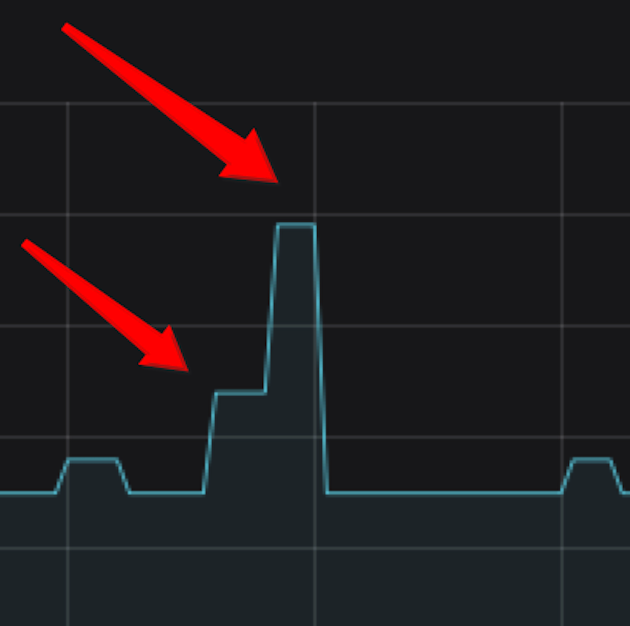
那么这样将会造成很大的问题,无法及时处理这种实时性高的业务场景。同时,我们还遇到了这样的业务情况,在一次大量扩容后,流量剧减,pod数量降到了一个极低值,但是由于出现业务流量的抖动,在接下来很短时间内,再一次出现大流量,此时pod数量无法处理如此高的流量,影响业务的SLA等。
(2) 问题解决思路
1,利用多指标 如果只使用单一指标,例如CPU,整个hpa将严重依赖于这项指标,该指标的准确性等直接影响整个hpa。在这里,我们使用CRD进行了多指标的开发,结合某个业务的具体场景,开发合适的指标,然后结合着CPU等指标一起使用。
2,调整默认参数 默认的扩容和缩容周期不一定是最合适你们的业务的,所以可以根据业务自身的情况进行调整。
3,自行开发hpa controller 这里还有一个思路是修改hpa controller,但是这样将会不利于以后的升级。所以可以自行开发hpa controller,自行定义最使用你们业务的扩容缩容算法即可。但是这样的开发成本就稍微有点大。
三,注意事项
(1) 支持deployment的滚动升级,不支持RC的滚动升级
四,总结
(1) 如果是我,会如何来设计
提出自己的愚蠢的思路:如果我是hpa这块的负责人,那么我将会将扩容和缩容算法这块写成是可扩展的,用户可自定义的扩容缩容步长,可针对每个hpa自定义扩容缩容的时间间隔,这样将会大大方便使用。
五,新版本特性研究(持续更新)
(1) v1.12.1
该版本对hpa这块改动挺大,总之增加了很多灵活性和可用性
1,可通过设置HorizontalPodAutoscalerDownscaleStabilizationWindow来防止流量抖动造成pod突然的减少。该版本中会记录HorizontalPodAutoscalerDownscaleStabilizationWindow时间内的每次扩展pod数量,每次取该时间内最大值,然后尝试尽量到达该值
2,目前对扩容这块还是有所限制,还是存在两倍大小的限制,但是取消了扩容和缩容的时间间隔限制
3,可自行设定误差容忍度
4,增加了pod readiness和missing metrics的考量。如何pod处于not ready状态或者有丢失的metrics,那么会将该pod闲置不处理。处理逻辑如下:如果是Resource和Pods的类型,那么判断pod是否ready的时候,首先pod的startTime加上cpuInitializationPeriod(可设置)大于当前时间,再判断pod的状态和metric获取的时间,从而来判断pod是否ready。pod的startTime加上cpuInitializationPeriod小于当前时间的情况下,则根据pod的状态和pod的启动时间加上readiness-delay(可设置)来判断pod是否ready。对于Object和External类型,则直接判断pod的状态
