

几周之前,我开始了一个系列旨在深入 JavaScript 及它到底是如何工作的:我们认为通过了解构成 JavaScript 的块以及这些块之间是如何协作的,这样你才能写出更好的代码和应用。
这个系列的第一篇文章关注引擎的概述,运行时和调用栈。第二篇将会深入到Google V8 JavaScript 应用的部分内部。我们也提供了一些关于如何写出 JavaScript 代码的小技巧 。
概述
JavaScript 引擎 是一个程序或者执行 JavaScript 代码的解释器。一个JavaScript 引擎可以作为一个单独的解释器实现或者通过某种方式将 JavaScript 编译为字节码的即时编译器。
下面是一系列 JavaScript 引擎实现的一些项目:
- V8 - Google 开发的,开源,用 C++ 实现的
- Rhino - 被 Mozilla 基金会管理的,开源,完全通过 java 开发的
- SpiderMonkey - 第一个 JavaScript 引擎,支持 Netscape Navigator,和今天的 Firfox
- JavaScriptCore - 开源,Apple 开发用于 Safari
- KJS - KDE 的引擎,Harri porten 开发的,用于 KDE 项目的 Konqueror 的web 浏览器
- Chakra(JScript9) - internet explorer
- Chakra(JavaScript)- Miscrosoft Edge
- Nashorn,开源,作为 OpenJDK 的一部分,Oracle 的 Java 语言和工具组开发的
- JerryScript - 轻量级的物联网引擎
为什么创建 V8 引擎?
Google 开发的 V8 引擎,是通过 C++ 实现的。这个引擎被用于 Google 的 Chrome 浏览器中。不像其余的引擎,V8 也被用于流行的 Node.js 运行时。
期初设计 V8 是用于提升 JavaScript 在 web 浏览器内的执行性能的。为了获得速度 ,V8 不使用解释器,而是将 JavaScript 代码转换成更高效的机器码。在执行期间,它通过被一个 JIT 编译器执行将 JavaScript 代码编译成机器码,像大多数现代的 JavaScript 引擎(比如,SpiderMonkey 或者 Rhino)那样。唯一不同的地方是V8 不产生字节码或者任意中间码。
V8 使用两个编译器
在 V8 5.9 版本之前,引擎使用两个编译器:
- full-codegen - 一个简单,快速的编译器,生产简单的,相对较慢的机器码。
- CrankShaft - 一个更加复杂(Just-In-Time)优化编译器,生产更高优化的代码。
V8 引擎在内部也是使用几个线程:
- 主线程做你所期望的那样:拉取代码,编译,执行
- 还有一个独立的用于编译的线程,让主线程可以继续执行,然而这个线程编译的是优化过的代码。
- 一个分析线程将会告诉运行时那些方法使用了多少时间,以便让 Crankshaft 可以优化它们。
- 一些用于处理垃圾收集回收的线程。
当第一次执行 JavaScript 代码的时候,V8 利用 full-codegen ,直接将 JavaScript 解析为机器码没有任何中间码的转换。这允许它非常快速地执行机器码。注意,V8 不使用中间的字节码,因而不用使用一个翻译器。
当你的代码运行一段时间,分析线程已经获取到足够的数据,告诉 CrankShaft 哪些方法应该被优化。
加下来,Crankshaft 在另一个线程开始优化。它将 JavaScript 抽象语法树转换成更高级的被称为 Hydrogen 的静态单赋值(SSA- static single-assignment),并且试着优化 Hydrogen 图。大多数的优化都在这一级别。
内联
第一个优化是提前内联尽可能多的代码。内联是用调用的函数体替代函数调用。这个简单的步骤可以使接下来的优化更有意义。
隐藏类
JavaScript 是一个基于原型的语言:没有类,对象的创建通过克隆的方式。JavaScript 也是一个动态的编程语言意味着对象的属性可以在对象初始化后很容易的添加和删除。
大多数的 JavaScript 的解释器使用类字典的数据结构(基于哈希函数)来存储对象属性的地址。这种结构使得 在JavaScript 中检索属性的值需要更昂贵的计算,相对于非动态编程语言来说(如,java,c#)。在 java 中,所有的属性在编译之前有一个固定的对象布局,在运行时不能动态的添加或者删除(好吧,c# 有动态类型,这又是另一个话题了)。因此属性的值(或者指向属性的指针)可以存储为一个连续的内存中,相互之间是固定的偏移量。具体的偏移量可以很容易地根据属性类型来决定,而这在 JavaScript 中是不可能的,JavaScript 的属性类型在运行时能够改变。
因为使用字典来查找内存中对象属性的位置非常的低效,V8 使用一个不同的方法替代:隐藏类。隐藏类的工作方式和在 java 中使用的固定对象布局有点儿类似,除了它们是在运行时创建的。现在,让我们看下:
function Point(x, y){
this.x = x;
this.y = y;
}
var p1 = new Point(1, 2);
一旦“new Point(1, 2)”调用发生了,V8 将会创建一个叫做 “C0”的隐藏类。
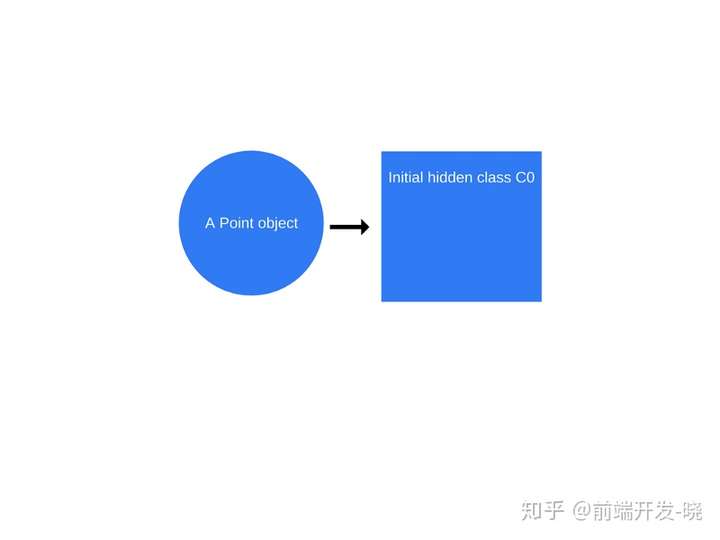
还没有为 Point 定义属性,因此“C0”是空的。
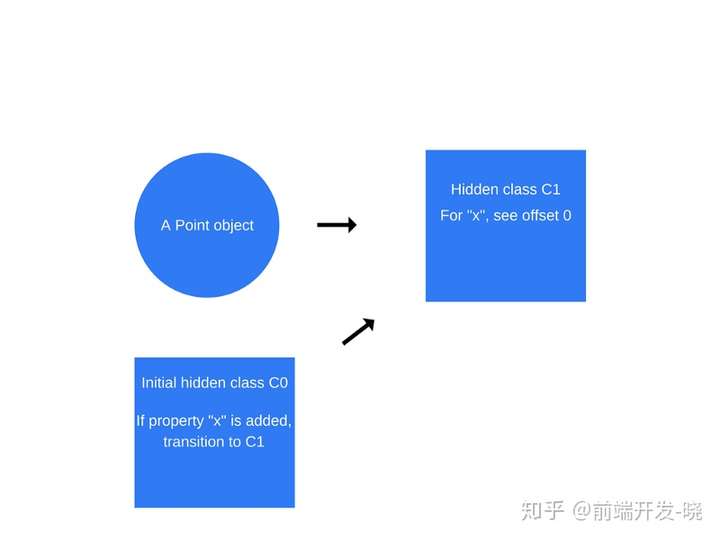
一旦(Point 函数内部)第一个语句“this.x = x”执行了,V8 将会创建第二个基于“C0”称作“C1”的隐藏类,。“C1”描述了相对于对象的指针属性 x 在内存中的位置。在这个例子中,“x”存储的偏移量是 0,意味着当浏览一个 point 对象在内存中是一个连续的缓冲区,第一个偏移量正是属性“x”。V8 将会依据“类过渡(class transition)”更新“C0”,“类过渡”描述了如果一个属性“x”被添加到一个 point 对象中,隐藏类应该从“C0”变为“C1”。下面 point 对象目前的隐藏类是“C1”。
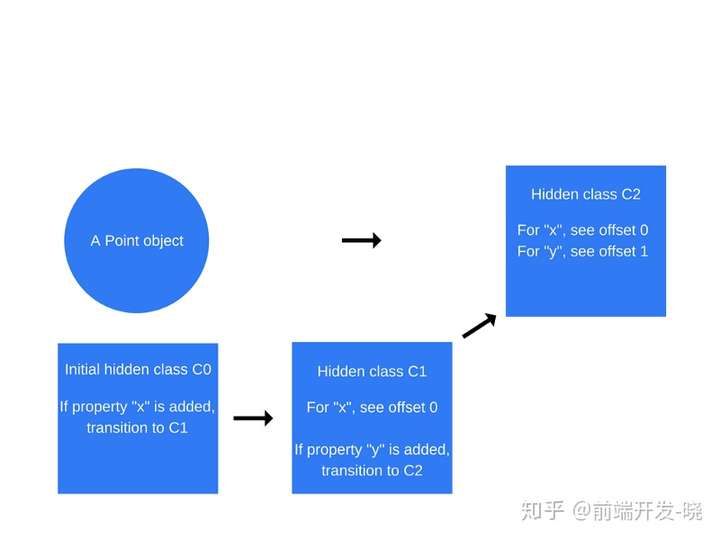
当执行语句“this.y=y”时,再次重复这个过程。
创建了一个新的隐藏类“C2”,“C1”上面添加上类过渡,如果属性“y”添加到 Point 对象中,隐藏类应该变为“C2”,并且point 对象的隐藏类更新到“C2”。
隐藏类的变换依赖于往一个对象中添加属性的顺序。看下下面的代码片段:
function Point(x,y){
this.x = x;
thix.y = y;
}
var p1 = new Point(1, 2);
p1.a = 5;
p1.b = 6;
var p2 = new Point(3, 4);
p2.a = 7;
p2.b = 8;
现在,你可能假设 p1 和 p2 有使用类变换一样的隐藏类。好吧,不完全是,对于“p1”,第一个属性“a”被添加了然后是属性“b”。对于“p2”来说,第一个“b”被添加了,接下来是“a”。因此,“p1”和“p2”因为有不同的类过渡路径而得到不同的隐藏类。在这种情况下,建议以相同的顺序初始化动态属性,便于重用隐藏类。
内联缓存
V8 用来优化动态类型语言的另一种方法称为“内联缓存”。内联缓存依赖于观察,反复调用相同的方法往往发生在相同类型的对象上面。
更深入关于内联缓存的解释可以在这里找到。
我们会触及内联缓存的一般概念(如果你没有时间通过上面的链接深入理解)。
那么,它是如何工作的?V8 在最近的方法调用中,对那些被作为参数传递的对象,维护了一个对象的类型的缓存,使用这些信息来做一个假设,在未来作为参数传递的对象的类型没有发生变化。如果 V8 能够对将会被传递给方法的对象的类型做一个假设,它可以绕过如何访问对象的属性这一过程,取代的是,使用之前存储的信息查找对象的隐藏类。
那么隐藏类和内联缓存有哪些关系呢?无论什么时候调用一个特定对象上面的方法,V8 引擎不得不执行查找对象的隐藏类为了决定访问特定属性的偏移量。经过两次同一个隐藏类上的相同的方法的成功调用,V8 省略了隐藏类的查找并且简单地添加属性的偏移量到一个对象指针上面。今后所有这个方法的调用,V8 引擎假设隐藏类没有发生改变,并且使用查找的偏移量直接跳跃到内存地中查找特定的属性。这大大提高了执行速度。
内联缓存也是为什么相同类型的对象共享隐藏类如此重要的原因。如果你创建了两个一样类型的对象并且不同的隐藏类(正如我们前面的例子),V8 不会使用内联缓存即使两个对象是一样的类型,它们相对应的隐藏类属性分配不同的偏移量。

编译到机器码
一旦 Hydrogen 图优化了,Crankshaft 降低到一个被称为“Lithium”较低级别的表示。大多数的 Lithium 的实现是架构特定的。寄存器分配发生在这个级别。
最后,Lithium 编译为机器码。然后发生了些叫做 OSR 的事情:on-stack replacement。在我们开始编译和优化一个明显长运行时间的方法之前,有可能运行它。V8 不会忘记它就慢慢开始执行优化的版本。相反,它将改变所有的上下文(栈和寄存器),这样我们能够在执行期间切换到优化过的版本。这是一个复杂的任务,记住,除了别的优化,V8 在内部内联化了代码。V8 不是唯一一个有这种能力的引擎。
这里有一种保障措施,如果所做的假设不再适用了,就会有一些"去优化"的操作(做相反的转换),并且回到没有优化时的代码。
垃圾回收
对于垃圾回收,V8 使用了传统的生代标记清除法来清除老生代。标记阶段应该停止 Javascript 的执行。为了控制GC 的消耗并且使执行更加稳定,V8 使用了增量式的标记:而不是遍历整个堆试着标记每个可能的对象,它仅仅遍历堆的一部分,然后返回正常的执行。下一次的 GC 将会从上一次遍历堆停止的地方开始。这允许在正常的执行期间有一些小的停顿。像之前提到,擦除阶段是在独立的线程中执行的。
Ignition 和 TurboFan
随着在 2017 年 V8 5.9 版本的发布,一个新的执行管道(pipeline)被引入了。这个新的执行管道达到更大的性能提升和在实际的 Javascript 中更节省内存。
这个新的执行管道是建立在 Ignition 上的,V8 的解释器,和 V8 最新的优化编译器。
从 V8 的 5.9 版本之后,full-codegen 和 Crankshaft(这两项技术从2010 开始使用)不再被V8 用于Javascript 的执行,V8 团队 一直在努力跟上新的 Javascript 的功能并且为这些新特做所需的优化。
这意味着整个 V8 有更简单和更易维护的架构。
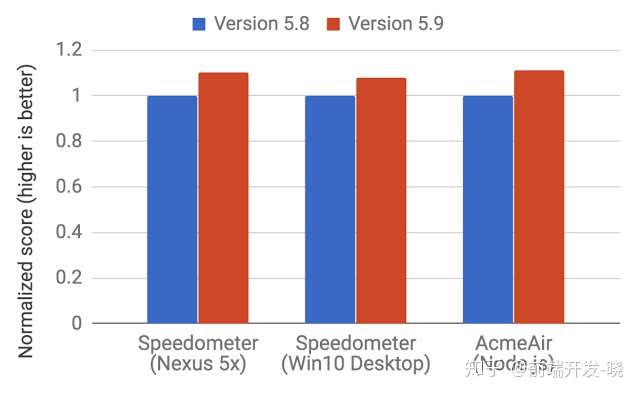
这些提升仅仅是开始。新的 Ignition 和 Turbofan 管道为将来的优化铺设了道路,未来几年在 Chrome 和 Node.js 中将大幅提升 Javascript 的性能和减少 V8 的内存消耗。
最后,这里有一些关于如何书写便于优化的更好的 Javascript 的小技巧和提示。从上面的内容可以很容易地得到这些,然而,为了你的方便,这里有一个总结:
如何书写优化的 Javascript
- 对象属性的顺序:要始终用同样的顺序初始化你的对象的属性,这样可以让隐藏类和后面的代码可以被共享
- 动态属性:向一个初始化后的对象添加属性将会强制隐藏类的变化和减慢之前隐藏类优化的方法,相反在构造函数中分配一个对象所有的属性。
- 方法:多次执行相同的方法的代码将会比执行很多只执行一次的方法要快(由于内联缓存)。
- 数组:避免稀疏数组。没有元素在内部的稀疏数组是一个哈希表。在这样的数组中访问更加昂贵。同时,尽量避免预分配大数组。最后,不要删除数组中的元素,这样会导致稀疏数组。
- 标记的值:V8 用 32 位来表示对象和数字。它需要知道是一个对象(flag=1)还者是一个被称为 Small integer (因为是 31 位)的整数(flag = 0)。如果一个数值比31 位的大,V8 就会封装这个数字,将它变为double 类型的,并且创建一个新的对象将数字放里面。尽量使用31 位 signed 数字避免昂贵的封箱操作为一个 Js 对象。
