

JieBa使用
List<SegToken> process = segmenter.process("今天早上,出门的的时候,天气很好", JiebaSegmenter.SegMode.INDEX);
for (SegToken token:process){
//分词的结果
System.out.println( token.word);
}
输出内容如下
今天
早上
,
出门
的
的
时候
,
天气
很
好
分词的执行逻辑
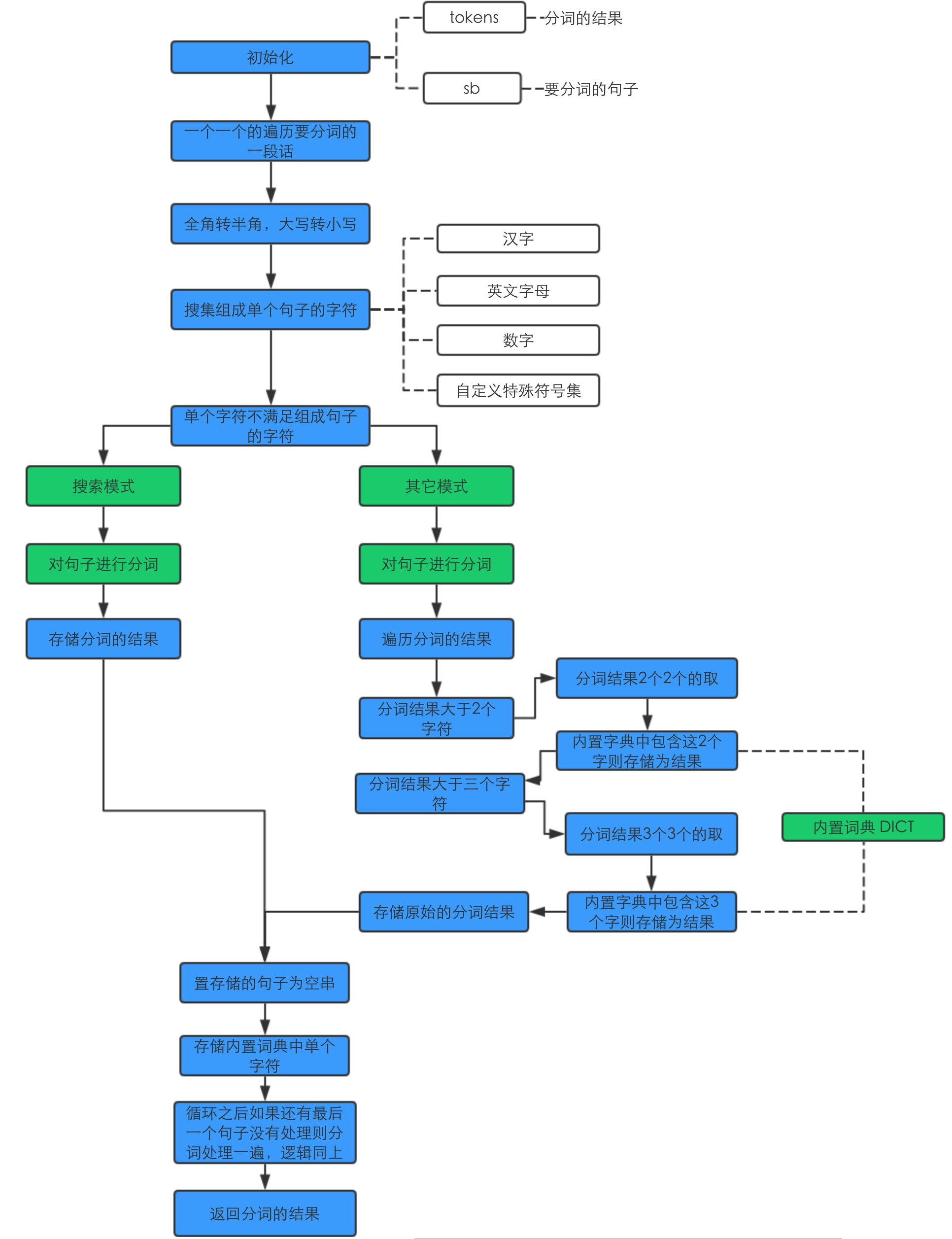
- 内部包含一个字典
- 分词逻辑
- 不同模式的切分粒度
分词的模式
- search 精准的切开,用于对用户查询词分词
- index 对长词再切分,提高召回率
分词流程
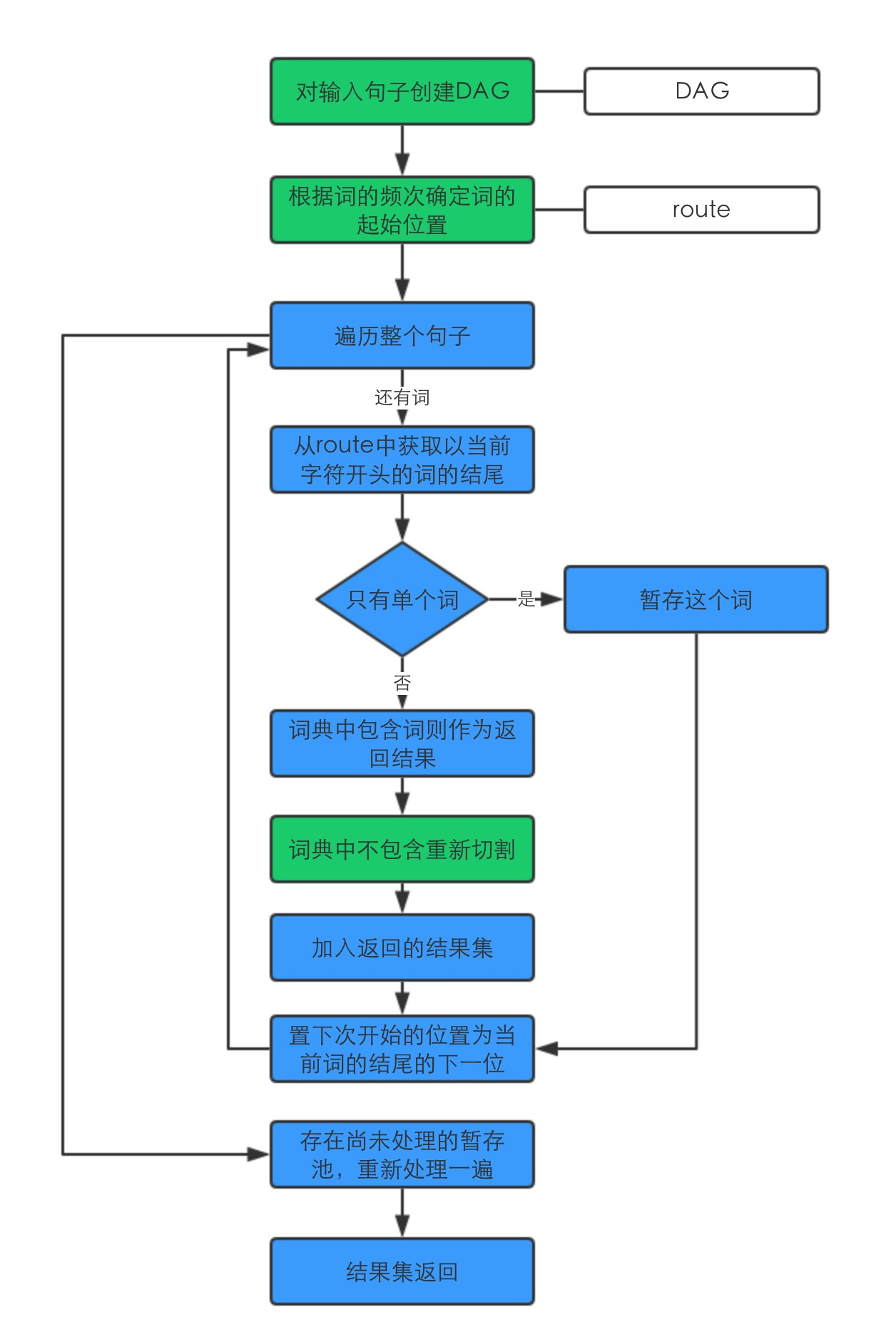
- 根据输入创建DAG
- 选取高频的词
- 词典中不包含的情况下,即未记录词,进行重新识别
创建DAG
- 获取已经加载的trie树
- 从trie树中匹配,核心代码如下
int N = chars.length; //获取整个句子的长度 int i = 0, j = 0; //i 表示词的开始 ;j 表示词的结束 while (i < N) { Hit hit = trie.match(chars, i, j - i + 1); //从trie树中匹配 if (hit.isPrefix() || hit.isMatch()) { if (hit.isMatch()) { //完全匹配 if (!dag.containsKey(i)) { List<Integer> value = new ArrayList<Integer>(); dag.put(i, value); value.add(j); } else dag.get(i).add(j); //以当前字符开头的词有哪些,词结尾的坐标记下来 } j += 1; if (j >= N) { //以当前字符开头的所有词已经匹配完成,再以当前字符的下一个字符开头寻找词 i += 1; j = i; } } else { //以当前字符开头的词已经全部匹配完成,再以当前字符的下一个字符开头寻找词 i += 1; j = i; } } - 补充DAG中没有出现的句子中的字符
DAG结果示例
比如输入的是 "今天早上"
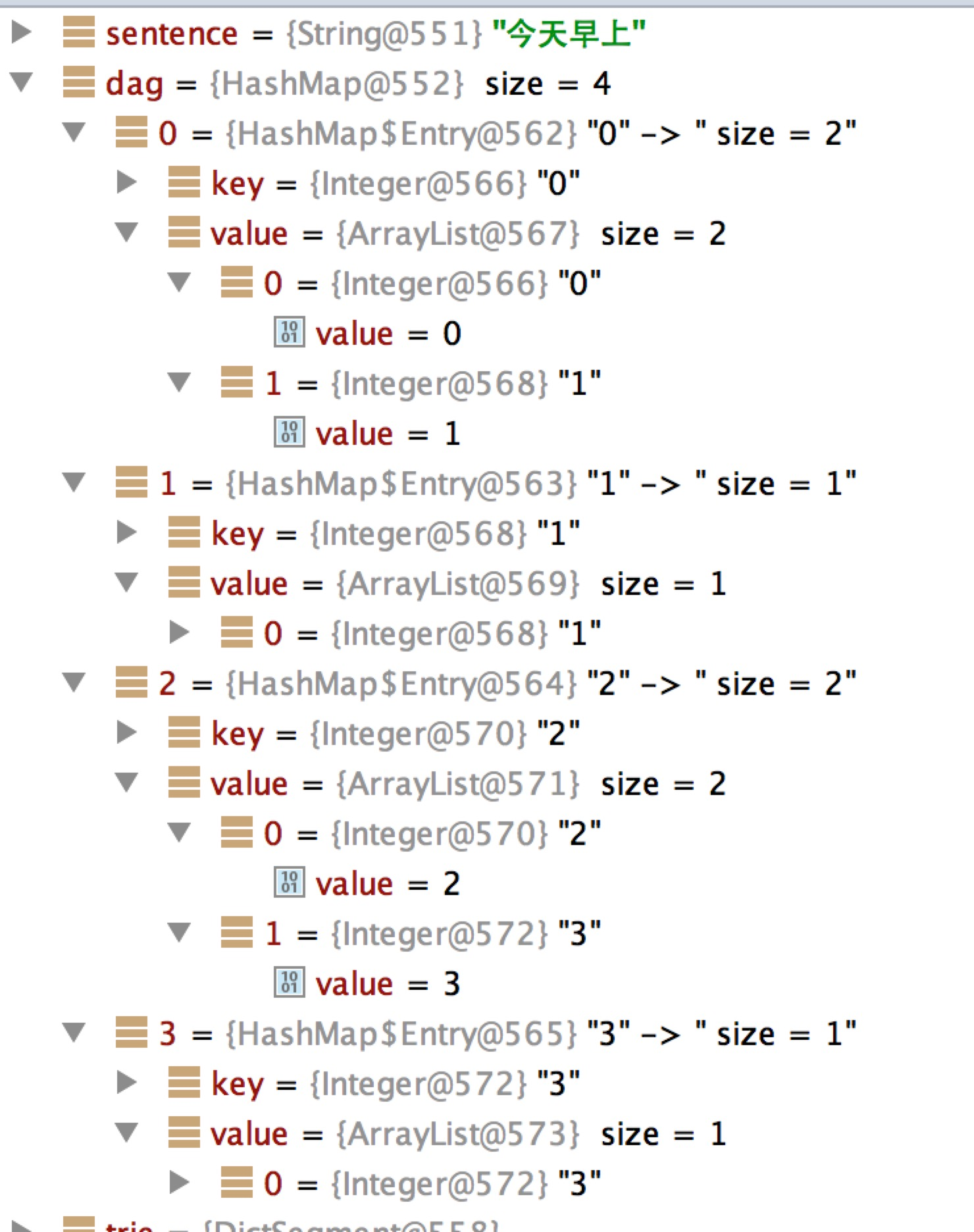
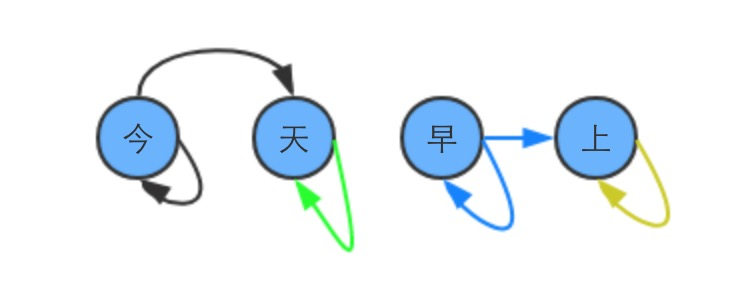
今/今天/早/早上/上
Trie树运用
JieBa内部存储了一个文件dict.txt,比如记录了 X光线 3 n。在内部的存储trie树结构则为
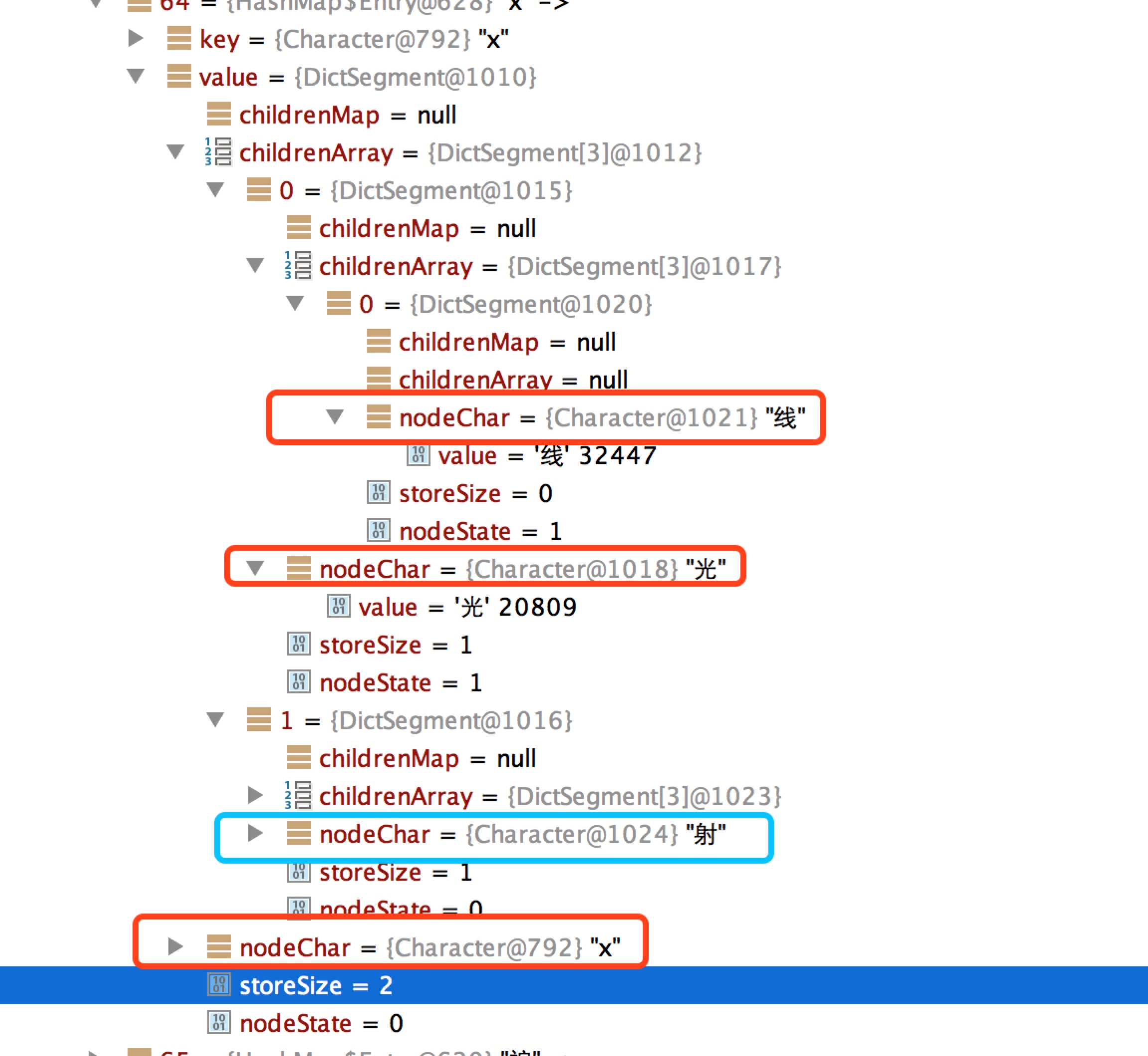
-
nodeState:当前DictSegment状态 ,默认 0 , 1表示从根节点到当前节点的路径表示一个词 ,比如 x光和 x光线
-
storeSize:当前节点存储的Segment数目
比如除了x光线之外,还有x射
- childrenArray和childrenMap用来存储trie树的子节点
storeSize <=ARRAY_LENGTH_LIMIT ,使用数组存储, storeSize >ARRAY_LENGTH_LIMIT,则使用Map存储 ,取值为3
选取高频的词
核心代码如下
for (int i = N - 1; i > -1; i--) {
//从右往左去查看句子,这是因为中文的重点一般在后面
//表示词的开始位置
Pair<Integer> candidate = null;
for (Integer x : dag.get(i)) {
//x表示词的结束位置
// wordDict.getFreq表示获取trie这个词的频率
//route.get(x+1)表示当前词的后一个词的概率
//由于频率本身存储的是数学上log计算后的值,这里的加法其实就是当前这个词为A并且后面紧跟着的词为B的概率,B已经由前面算出
double freq = wordDict.getFreq(sentence.substring(i, x + 1)) + route.get(x + 1).freq;
if (null == candidate) {
candidate = new Pair<Integer>(x, freq);
}
else if (candidate.freq < freq) {
//保存概率高的词
candidate.freq = freq;
candidate.key = x;
}
}
//可见route中存储的数据为key:词头下标 value:词尾下标,词的频率
route.put(i, candidate);
}
高频词选取过程:
- i=N-1: route中仅存了一个初始的值,N=4,freq=0,代表最后一个次后面是没有词的,首先获取词 '上' 在trie中的频率为 -5.45,相加后可得上的概率为 -5.45,由于以 '上' 开头的只有1个词,存入route中 <3,-5.45>
(3,<3,-5.45>) :第一个3是词头,第二个3是 '上' 的词尾下标;-5.45是它出现的概率;
(4,<0,0>):初始概率 - i=N-2: 以 '早' 开头的有两个词,分别为 '早' 和 '早上',首先获取词典中 '早' 的频率为 -8.33,它的后一个词为 '上' ,求和后频率为 -13.78;再获取 '早上',在词典中的频率为 -10.81 ,'早上' 后面没有词,因此频率取值就是 -10.81,对比两个词频大小,'早上'的频率大,因此只保留了 '早上'
此时 route保留了 (3,<3,-5.45>)、(4,<0,0>)和(2, <3,-10.81> )
依此类推,经过route之后的取词如下

分词代码
取完了高频词之后,核心逻辑如下
while (x < N) {
//获取当前字符开头的词的词尾
y = route.get(x).key + 1;
String lWord = sentence.substring(x, y);
if (y - x == 1)
sb.append(lWord); //单个字符成词,先保留
else {
if (sb.length() > 0) {
buf = sb.toString();
sb = new StringBuilder();
if (buf.length() == 1) {
tokens.add(buf);
}
else {
if (wordDict.containsWord(buf)) {
tokens.add(buf); //多个字符并且字典中存在,作为分词的结果
}
else {
finalSeg.cut(buf, tokens);
}
}
}
//保留多个字符组成的词
tokens.add(lWord);
}
x = y; //从当前词的词尾开始找下一个词
}
词提取的过程
- x=0,找到它的词尾为1,此时获取到了 '今天',由于包含多个词,直接作为分词的结果
- x=2,词尾为3,获取到'早上' ,分词结束
至此 '今天早上' 这句话分词结束。可以看到这都是建立在这个词已经存在于字典的基础上成立的。
如果出现了多个单个字成词的情况,比如 '出门的的时候' 中的 '的',一方面它成为了单个的词,另一方面后面紧跟着的 '的'与它一起成为了两个字符组成的词,又在词典中不存在 '的的' ,因而识别为未知的词,调用 finalSeg.cut
Viterbi算法处理未记录词,重新识别
使用的方法为Viterbi算法。首先预加载如下HMM模型的三组概率集合和隐藏状态集合
-
未知的词定义了4个隐藏状态。 B 表示词的开始 M 表示词的中间 E 表示词的结束 S 表示单字成词
-
初始化每个隐藏状态的初始概率
start.put('B', -0.26268660809250016); start.put('E', -3.14e+100); start.put('M', -3.14e+100); start.put('S', -1.4652633398537678); -
初始化状态转移矩阵
trans = new HashMap<Character, Map<Character, Double>>(); Map<Character, Double> transB = new HashMap<Character, Double>(); transB.put('E', -0.510825623765990); transB.put('M', -0.916290731874155); trans.put('B', transB); Map<Character, Double> transE = new HashMap<Character, Double>(); transE.put('B', -0.5897149736854513); transE.put('S', -0.8085250474669937); trans.put('E', transE); Map<Character, Double> transM = new HashMap<Character, Double>(); transM.put('E', -0.33344856811948514); transM.put('M', -1.2603623820268226); trans.put('M', transM); Map<Character, Double> transS = new HashMap<Character, Double>(); transS.put('B', -0.7211965654669841); transS.put('S', -0.6658631448798212); trans.put('S', transS);比如trans.get('S').get('B')表示如果当前字符是 'S',那么下个是另一个词(非单字成词)开始的概率为 -0.721
-
读取实现准备好的混淆矩阵,存入 emit中

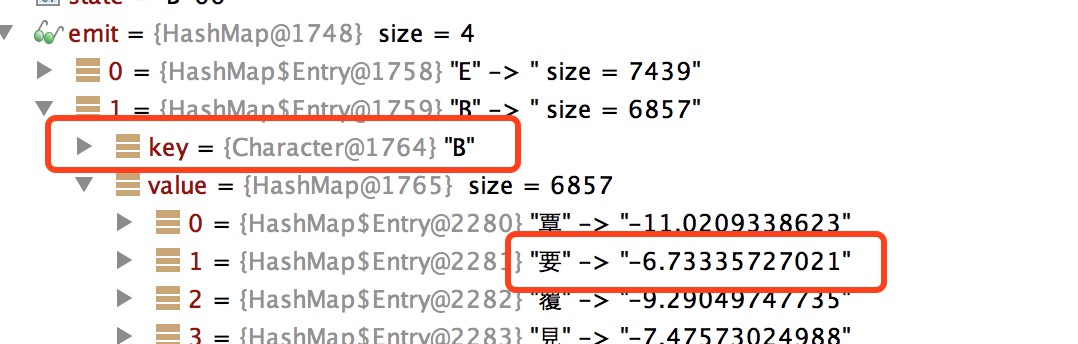
另外它预定义了每个隐藏状态之前只能是那些状态
prevStatus.put('B', new char[] { 'E', 'S' }); prevStatus.put('M', new char[] { 'M', 'B' }); prevStatus.put('S', new char[] { 'S', 'E' }); prevStatus.put('E', new char[] { 'B', 'M' });比如 'M' 它的前面必定是 'M' 和 'B' 之间的一个
算法的流程如下:
- 获取句子中第一个字符在所有隐藏状态下的概率
for (char state : states) { Double emP = emit.get(state).get(sentence.charAt(0)); if (null == emP) emP = MIN_FLOAT; //存储第一个字符 是 'B' 'E' 'M' 'S'的概率,即初始化转移概率 v.get(0).put(state, start.get(state) + emP); path.put(state, new Node(state, null)); } - 计算根据观察序列得到和HMM模型求隐藏序列的概率,并记下最佳解析位置,通过父指针连接起来
for (int i = 1; i < sentence.length(); ++i) {
Map<Character, Double> vv = new HashMap<Character, Double>();
v.add(vv);
Map<Character, Node> newPath = new HashMap<Character, Node>();
for (char y : states) {
//y表示隐藏状态
//emp是获取混淆矩阵的概率,比如 在 'B'发生的情况下,观察到字符 '要' 的概率
Double emp = emit.get(y).get(sentence.charAt(i));
if (emp == null)
emp = MIN_FLOAT; //样本中没有,就设置为最小的概率
Pair<Character> candidate = null;
for (char y0 : prevStatus.get(y)) {
Double tranp = trans.get(y0).get(y);//获取状态转移概率,比如 E -> B
if (null == tranp)
tranp = MIN_FLOAT; //转移概率不存在,取最低的
//v中放的是当前字符的前一个字符的概率,即前一个状态的最优解
//tranp 是状态转移的概率
//三者相加即计算已知观察序列和HMM的条件下,求得最可能的隐藏序列的概率
tranp += (emp + v.get(i - 1).get(y0));
if (null == candidate)
candidate = new Pair<Character>(y0, tranp);
else if (candidate.freq <= tranp) {
//存储最优可能的隐藏概率
candidate.freq = tranp;
candidate.key = y0;
}
}
//存储是'B'还是 'E'各自的概率
vv.put(y, candidate.freq);
//记下前后两个词最优的路径,以便还原原始的隐藏状态分隔点
newPath.put(y, new Node(y, path.get(candidate.key)));
}
//存储最终句子的最优路径
path = newPath;
}
- 找到句子尾部的字符的隐藏个状态,并通过最佳路径旅顺整个句子的切割方式
double probE = v.get(sentence.length() - 1).get('E'); double probS = v.get(sentence.length() - 1).get('S'); Vector<Character> posList = new Vector<Character>(sentence.length()); Node win; if (probE < probS) win = path.get('S'); else win = path.get('E'); while (win != null) { //沿着指针找到句子的每个字符的个子位置 posList.add(win.value); win = win.parent; } Collections.reverse(posList); - 遍历这个句子,根据标注,记下所有切割点的词
int begin = 0, next = 0;
for (int i = 0; i < sentence.length(); ++i) {
char pos = posList.get(i);
if (pos == 'B')
begin = i;
else if (pos == 'E') {
//到词尾了,记下
tokens.add(sentence.substring(begin, i + 1));
next = i + 1;
}
else if (pos == 'S') {
//单个字成词,记下
tokens.add(sentence.substring(i, i + 1));
next = i + 1;
}
}
if (next < sentence.length())
tokens.add(sentence.substring(next));
自此执行结束
