

这不是一个纯粹的学习帖子,最开始为了生产项目考虑的。公司有个新的、小的活动项目。以此为假想,所以我希望学习一些新的技术应用在上面;这个新的项目是作为旧项目的一个子系统存在的,所以又必须在一定程度上保持一致。
而这个旧项目的原有使用构建工具fis的版本比较老旧,不敢升级,怕出什么幺蛾子,所以又不能动他。
在网上学习了众多攻略之后自己尝试搭建了一下,解决了一些问题,也留下了一下疑惑。
项目资源路径
github: github.com/johnshere/a…
一、环境配置
node: v10.6.0(v6.12.3)、yarn: 1.7.0、webpack: 4.16.1
系统:windows10
yarn是类似npm但是效率更高的包管理工具,命令互换参考yarnpkg.com/zh-Hans/doc…
可以使用npm安装(这里让我想到IE存在的意义,-_-)
npm install -g yarn
也可以去官网下载客户端
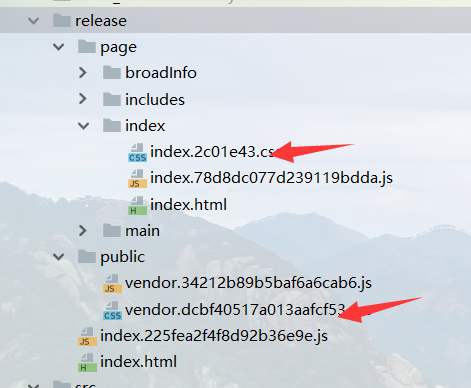
二、目录结构
如图:
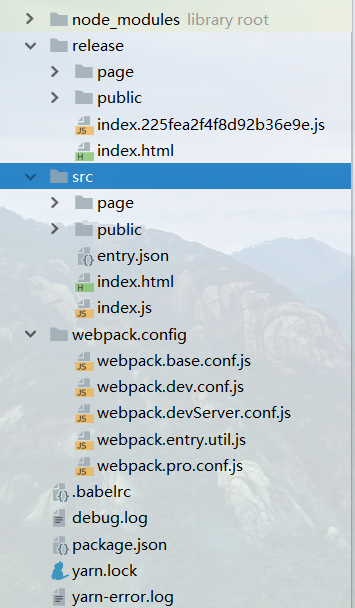
src:工程源代码; release:工程发布; webpack.config:webpack配置文件;
发布之后的HTML保持与src中的路径一致;这样代码中使用相对路径访问页面就不会出现结构错乱的问题。
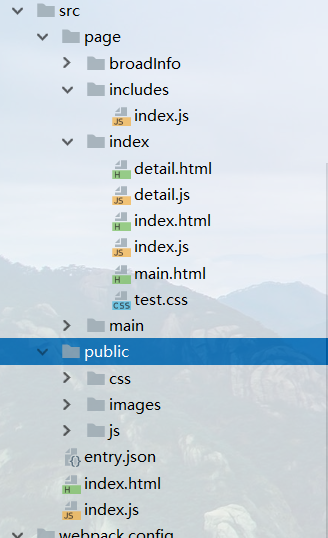
这是目录索引页面,因为是多页面入口,webpack-dev-server模式打开的时候用于快速进入自己想要的页面(下面会说)
三、两个构建环境切换(与webpack无关)
公司原有的fis是最初版本的,一直没有人做更新维护,现在已经落后现在的技术版本多年,但是又必须使用。
webpack4不可能在和他进行兼容,所以我安装了两个不同版本的node,v10.6.0、v6.12.3;使用的时候切换
set dir=D:
set name1=node612
set name2=node106
set name=node
if exist %dir%\%name1% (
echo "node612 ==> node"
ren %dir%\%name% %name2%
ren %dir%\%name1% %name%
)else (
echo "node106 ==> node"
ren %dir%\%name% %name1%
ren %dir%\%name2% %name%
)
pause
这样切换了node,实际上就是切换整个开发环境,毕竟这两个构建工具都是依赖于node的。
切换时在cmd或者powershell里执行:
changeNodeName
四、webpack配置
这个应该是重中之重了,在写配置之前我首先确定了自己想解决的一些问题
- 发布后保证目录结构不变
- 分割公共文件,如样式、图片;达到缓存目的
- 分割的大文件不能过大(未解决)、不能让用户频繁加载
- 保证文件之间缓存良好互不干扰
- 转义语法
1、webpack.entry.util.js
const path = require("path");
const Glob = require("glob");
const fs = require("fs");
let obj = {
/**
* 根据目录获取入口
* @param {[type]} globPath [description]
* @return {[type]} [description]
*/
getEntryJs: function (globPath) {
globPath = path.resolve(__dirname, globPath);
let entries = {};
Glob.sync(globPath).forEach(function (entry) {
let basename = path.basename(entry, path.extname(entry)),
pathname = path.dirname(entry),
paths = pathname.split('/'),
fileDir = paths.splice(paths.indexOf("src") + 1).join('/');
//仅处理page路径下的js
if (pathname.indexOf("page") > -1) {// && fileDir && fileDir.indexOf(("page") === 0)) {
entries[(fileDir ? fileDir + '/' : fileDir) + basename] = pathname + '/' + basename;
}
});
//目录页保留
entries["index"] = path.resolve(__dirname,"../src/index").split("\\").join("/");
console.log("---------------------------------------------\nentries:");
console.log(entries);
console.log("----------------------------------------------");
return entries;
},
/**
* 根据目录获取 Html 入口
* @param {[type]} globPath [description]
* @return {[type]} [description]
*/
getEntryHtml: function (globPath) {
globPath = path.resolve(__dirname, globPath);
let entries = [];
Glob.sync(globPath).forEach(function (entry) {
let basename = path.basename(entry, path.extname(entry)),
pathname = path.dirname(entry),
paths = pathname.split('/'),
// @see https://github.com/kangax/html-minifier#options-quick-reference
minifyConfig = process.env.NODE_ENV === "production" ? {
removeComments: true,
// collapseWhitespace: true,
minifyCSS: true,
minifyJS: true
} : "";
//只处理page目录下的HTML
//保留目录页
if (entry.indexOf("page") > -1 ) {
let chunkName = paths.splice(paths.indexOf("src") + 1).join('/') + "/" + basename;
entries.push({
filename: chunkName + ".html",
template: entry,
chunks: ['public/vendor', chunkName],
minify: minifyConfig
});
}
});
//保留目录页
entries.push({
filename: "index.html",
template: path.resolve(__dirname,"../src/index.html").split("\\").join("/"),
chunks: ['public/vendor',"index"]
});
//保存entry的json文件
this.entry2JsonFile(entries);
return entries;
},
/**
* 生成entry对应的json文件
* @param entries
*/
entry2JsonFile: function (entries) {
console.log(entries);
let json = {};
if (entries) {
entries.forEach(v => {
json[v.filename] = v.filename;
});
}
console.log(json);
//同步写入文件
let fd = fs.openSync(path.resolve(__dirname, "../src/entry.json"), "w");
fs.writeSync(fd, JSON.stringify(json), 0, "utf-8");
fs.closeSync(fd);
}
};
// obj.getEntry("../src/page/**/*.js");
// obj.getEntryHtml('../src/page/**/index.html');
module.exports = obj;
这个地方的entry识别参考了:
github地址:github.com/givebest/we…
这个entry工具主要是为了识别js和HTML;我在原有的逻辑上进行了修改,符合了我的要求,即只识别page目录下的entry。
同时,我添加了一个方法,即将所有的HTML路径写入到一个json文件中保存起来(后面dev-server模式用到)。前两个方法里也为入口目录页做了特殊处理
这个工具中对chunk的key值做了特殊处理,可以看出,切割出了从src之后的路径作为key值,因为webpack的name是支持路径的,这样就达到问题1的效果。
2、webpack.base.conf.js
const path = require("path");
const HtmlWebpackPlugin = require('html-webpack-plugin');
// const ExtractTextPlugin = require('extract-text-webpack-plugin');
const CleanWebpackPlugin = require("clean-webpack-plugin");
const MiniCssExtractPlugin = require("mini-css-extract-plugin");
const entryUtil = require("./webpack.entry.util");
let entryJs = entryUtil.getEntryJs('../src/page/**/index.js');
let conf = {
entry: entryJs,//js打包入口识别
output: {
path: path.resolve(__dirname, "../release"),
filename: "[name].[chunkHash].js",
// publicPath: "../../public"
},
module: {
rules: [
{
test: /\.css$/,
// loader: ExtractTextPlugin.extract({
// fallback: 'style-loader',
// use: 'css-loader'
// })
use:[MiniCssExtractPlugin.loader,'css-loader']//'style-loader',
},
{
test: /\.html$/,
loader: 'html-withimg-loader'
},
{test: require.resolve("jquery"), loader: "expose-loader?$!expose-loader?jQuery"}
]
},
plugins: [
// new HtmlWebpackPlugin({
// filename: "index.html",
// template: "src/page/index.html",
// chunks: ["main", "vender"]
// }),
// new ExtractTextPlugin("./[name].[chunkHash].css")
new CleanWebpackPlugin(["release"],{
root: path.resolve(__dirname, ".."),
verbose: true,
dry: false
}),
new MiniCssExtractPlugin({
filename: "[name].[contenthash:7].css",
chunkFilename: "[name].[contenthash].css"
})
],
optimization: {
splitChunks: {
cacheGroups: {
commons: {
name: "public/vendor",
chunks: "all",
minChunks: 2
}
}
}
},
resolve: {
extensions: [".js", ".jsx"],
alias: {
layer: path.resolve(__dirname, "../src/public/js/layer/mobile/layer.js"),
"layer.css": path.resolve(__dirname, "../src/public/js/layer/mobile/need/layer.css")
}
}
};
//HTML入口
let entryHtml = entryUtil.getEntryHtml('../src/page/**/index.html');
entryHtml.forEach(function (v) {
conf.plugins.push(new HtmlWebpackPlugin(v));
});
module.exports = conf;
这里就需要给解释了,开始学习webpack,然后网上不断找各种帖子,学习、修改、测试最终成了这些配置文件,有些改动时间长了我自己都忘记(-_-)!。
2.1 获取entry、HtmlWebpackPlugin
使用工具获取指定的HTML和js,这里我做一个限制,只取index名称的,这是因为公司很多模板文件都是用html后缀。
webpack的入口是只识别js的,这里就需要用到HtmlWebpackPlugin,没生成一个HTML与js的对应关系就要new一个HtmlWebpackPlugin。所以上面entryHtml是push进去的,还有就是entryHtml中做了生产环境的判断。
2.2 分割css文件
现在使用的是MiniCssExtractPlugin,但是从注释开出来我最开始使用的是ExtractTextPlugin(我也是从注释看到才想起来的,哈哈哈哈)。
先说ExtractTextPlugin,这个要在webpack4上面用正常安装是不行的,现在必须指定版本@next,否则不能兼容webpack4。如下:
yarn add ExtractTextPlugin@next
配置好了之后,我用了一段时间,最后在思考上面第四个问题的时候,把这个替换掉了,ExtractTextPlugin好像不能使用contenthash。
我们公司是做bss系统的,业务复杂,而且更换业务逻辑的频率很快,所以index.js修改比较多,但是样式和图片其实改动不多,不能因为改了一个if else,就需要用户更新css和图片吧。所以换成MiniCssExtractPlugin现在的样子。
然后关于MiniCssExtractPlugin的配置
filename是配置每个chunk对应分割出css文件的配置
chunkfilename是配置分离出的公共css文件的配置
2.3 加载jquery
jquery没有实现模块化,在loader里面做了特殊处理;这样之后在每个js里面就可以使用require或者import引入jquery
但是实际上,这个只能达到引入效果,$还是全局对象。
2.4 HTML中的图片路径
我在有些前辈的帖子中看到是需要在HTML标签中加一下引用判断、loader标识;这样很不友好;这里使用了一个loader:html-withimg-loader,用这个loader,就不用管了,他自己处理HTML中出现的图片链接。
2.5 清理
清理已经存在的文件,如果不清理每次发布都会有残余文件,虽然没有什么影响,但是不能忍。 CleanWebpackPlugin可以指定清理的正则配置,如:
new CleanWebpackPlugin(["release"],{
root: path.resolve(__dirname, ".."),
verbose: true,
dry: false
}),
new CleanWebpackPlugin(["release/*.js","release/**/*.*"],{
root: path.resolve(__dirname, ".."),
verbose: true,
dry: false
}),
3、webpack.devServer.conf.js
开发环境
'use strict';
const path = require("path");
const webpack = require("webpack");
const merge = require('webpack-merge');
const base = require('./webpack.base.conf');
// process.env.NODE_ENV = "development";
module.exports = merge(base, {
mode: "development",
devtool: "eval-source-map",
output: {
path: path.resolve(__dirname, "../release"),//"../release_dev"),
filename: "[name].[hash].js",
},
module: {
rules: [
{
test: /\.(png|jpg|gif)$/,
// loader: 'url-loader?limit=8192&name=./public/images/[name].[hash].[ext]'
loader: {
loader: 'url-loader',
options: { // 这里的options选项参数可以定义多大的图片转换为base64
name: '[name].[hash].[ext]',
// limit: 8192, // 表示小于50kb的图片转为base64,大于50kb的是路径
// outputPath: '/public/images' //定义输出的图片文件夹
}
}
}
]
},
plugins:[
new webpack.HotModuleReplacementPlugin()
],
devServer: {
port: 8080,
contentBase: path.resolve(__dirname, "../release"), //本地服务器所加载的页面所在的目录
historyApiFallback: true, //不跳转
inline: true, //实时刷新
hot: true, // 开启热更新,
//服务器代理配置项
proxy: {
'/o2o/*':{
target: 'https://www.baidu.com',
secure: true,
changeOrigin: true
}
}
}
});
这个在base的基础上做了些许调整,主要是为了使用webpack-dev-server;这个配置文件是为它存在的。
3.1 output hash
这里的hash有chunkhash改成hash,原因是使用HotModuleReplacementPlugin之后不能使用chunkhash和contenthash。
看到有些地方说把“hot:true”去掉就行了,但是我自己实际测试不行,只是去掉hot还是会报错;所以我索性给改成hash了,反正是本机调试,影响不大。
3.2 devServer
这个功能很强大,对开发人员来说是非常友好的。
安装webpack-dev-server
yarn add webpack-dev-server
这个代理proxy功能还是非常强大的,将后台服务请求指向我们的测试环境或者本地。我们原有的fis是包装了一层nginx,每次还要单打开,单独配置nginx。这里集成这个功能,很好。本地开发减少依赖,也便于调试。
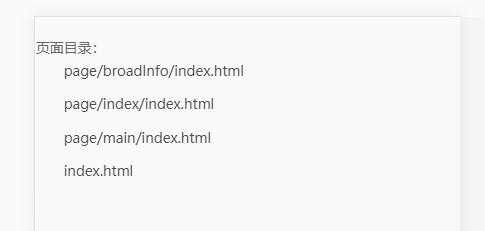
3.4 入口(entry)目录页
前面在entry工具中将所有的entry写入到一个json文件中了。在这个地方就用到了,我们项目本质上根本不是spa,使用webpack还是比较牵强的。
当启动了webpack-dev-server之后它会默认打开根目录下的index.html。其实我们项目的页面很多,不论默认打开哪个都不方便开发,我干脆把这个index.html做成了一个目录页面。将entry.json中所有的路径全显示,点击之后进入各个页面。
// const $ = require("jquery");
import $ from "jquery";
const entryJson = require("./entry.json");
console.log(1122333,entryJson);
$(() => {
$("html").css("font-size","16px");
for (let k in entryJson){
$("body").append("<a style='margin: 1rem;padding-left:3rem;font-size: 2rem;line-height: 2rem;display: block' href='"+entryJson[k]+"'>"+entryJson[k]+"</a></br>");
}
});
4、webpack.pro.conf.js
生产环境
'use strict';
const path = require("path");
const merge = require('webpack-merge');
const base = require('./webpack.base.conf');
module.exports = merge(base, {
mode: "production",
optimization: {
splitChunks: {
cacheGroups: {
commons: {
name: "public/vendor",
chunks: "all",
minChunks: 2
}
}
}
},
module: {
rules: [
{
test:/\.js$/,
exclude: /node_modules/,
loader: "babel-loader"
},
{
test: /\.(png|jpg|gif)$/,
// loader: 'url-loader?limit=8192&name=./public/images/[name].[hash].[ext]'
loader: {
loader: 'url-loader',
options: { // 这里的options选项参数可以定义多大的图片转换为base64
name: '[name].[hash].[ext]',
limit: 8192, // 表示小于的图片转为base64,大于的是路径
outputPath: 'public/images' //定义输出的图片文件夹
}
}
}
]
}
});
这个生产的配置也是在前面的base基础上调整的。
4.1 发布目录调整
这个小的工程是作为一个子工程存在于旧项目,所以url不是直接访问的,需要加上“工程名”的一级路径。url-loader的outputPath、所有chunkname都需要多加一段“activity”,具体需要自己调试。
例如:
xxxx.com/index.html -> xxxx.com/activity/in… xxxx.com/public/1.cs… -> xxxx.com/activity/pu…
这个地方有个需要注意,最开始尝试的时候,我想只要只要改output就行了;但是测试之后才发现不行。原因很简单,这个图片src是给浏览器用的,是统一资源定位符。仅仅调整output的path是不会在定位符上加“activity”的,那仅仅是改变了发布后文件保存的路径。x现在需要在发布的时候加深一个目录级别,例如:
optimization: {
splitChunks: {
cacheGroups: {
commons: {
name: "activity/public/vendor",
chunks: "all",
minChunks: 2
}
}
}
},
{
test: /\.(png|jpg|gif)$/,
// loader: 'url-loader?limit=8192&name=./public/images/[name].[hash].[ext]'
loader: {
loader: 'url-loader',
options: { // 这里的options选项参数可以定义多大的图片转换为base64
name: '[name].[hash].[ext]',
limit: 8192, // 表示小于的图片转为base64,大于的是路径
outputPath: 'activity/public/images' //定义输出的图片文件夹
}
}
}
4.2 图片分割
如代码中展示这里使用了url-loader,并且设定limit;当图片超过limit限制会单独生成文件,否则就是base64存储。
但是这里我遇到一个棘手问题,当图片单独存储时,options.name的hash值不能设置成contentHash或者chunkHash,并且也没有找到合适的解决办法,希望知道的朋友给我说一下。(虽然在一定程度上说不用hash值也行,但是我感觉这样不好)
4.3 babel编译
使用babel转义ECMAScript6的语法,使之兼容旧的浏览器。如代码中设置loader,然后在项目根目录创建新文件.babelrc,内容:
{
"presets": ["env"]
}
安装babel
yarn add babel-core babel-loader babel-preset-env
4.4 mode NODE_env
这里在webpack配置文件中设置了mode:production,并且在启动脚本中也设置node的环境为production。删掉了devtool。 这里设置的环境配合entry工具中对环境的识别,会配置压缩设置。
package.json的scripts
如下:
{
"scripts": {
"dev": "cross-env NODE_ENV=development webpack --config ./webpack.config/webpack.dev.conf.js",
"pro": "cross-env NODE_ENV=production webpack --config ./webpack.config/webpack.pro.conf.js --progress",
"devServer": "webpack-dev-server --config ./webpack.config/webpack.devServer.conf.js --open --mode development",
"watch": "webpack --config ./webpack.config/webpack.dev.conf.js --watch"
}
}
首先安装cross-env,用于设置node环境;在上面的脚本中可以看到cross-env的使用
yarn add cross-env
上面设置两个webpack的配置文件,但是没有实际使用,其实使用的命令就是scripts中的内容。只不过这里可以是操作简化,但我们使用时只需要启动脚本,如下: 开发环境:
yarn run devServer
生产环境:
yarn run pro
run也是可以省略的。 webpack-dev-server模式下不会将实际发布的内容写入在硬盘上,如果我们需要自行查看内容,可以执行:
yarn run watch
只不过这样做意义不大,因为我发现,你每次修改都会产生一些列文件,很快你就发现生成的是一堆垃圾,从中找东西费劲的很。
问题遗留
- 大图片大单分割出来后无法使用contenthash,我如何能让一个大图长久缓存呐
- 公共文件过大,仅我写的这个测试工程vender就已经一兆多,感觉不是很大,但是真实项目中就很可怕了。而且我们项目是移动端的,这样大文件下载的留白时间也很难受。
