

写在前面
该文章是继Java注解解析-基础+运行时注解(RUNTIME)之后,使用注解处理器处理CLASS注解的文章。通过完整的Demo例子介绍整个注解处理器的搭建流程以及注意事项,你将知道如何去搭建自己的注解处理器。前提是你知道如何去写自定义注解,不清楚的可以点击我上面的链接哦~
介绍
顾名思义注解处理器就是javac包中专门用来处理注解的工具。所有的注解处理器都必须继承抽象类AbstractProcessor然后重写它的几个方法。注解处理器是运行在它自己的JVM中。javac启动一个完整Java虚拟机来运行注解处理器,这意味着你可以使用任何你在其他java应用中使用的的东西。其中抽象方法process是必须要重写的,再该方法中注解处理器可以遍历所有的源文件,然后通过RoundEnvironment类获取我们需要处理的注解所标注的所有的元素,这里的元素可以代表包,类,接口,方法,属性等,具体的解释放在下一章节,因为这里面牵扯到的东西实在是太多了。再处理的过程中可以利用特定的工具类自动生成特定的.java文件或者.class文件,来帮助我们处理自定义注解。
下面开始搭建
1.创建
首先注解处理器需要javax包的支持,我们的Android环境下是访问不到javax包的,除非我们自己配置。
//app:build.gradle中加入依赖,一定要使用provided files来引入.
provided files('/Applications/Android Studio.app/Contents/jre/jdk/Contents/Home/jre/lib/rt.jar')
所以我们需要创建Java Library包来提供javax环境,另外注解处理器要被打包进jar包里面才能被系统识别,这就是选用ava Library的原因,目前注解注解框架均是如此。
创建好Module之后就可以写我们的自定义的注解处理器了。首先需要继承抽象类AbstractProcessor,然后重写process()方法。该方法是核心方法,该方法将遍历源代码,找出我们想要注解标注的元素。单单重写这一个方法是不够的, 在我们的开发中往往需要重写init(),getSupportedSourceVersion(),getSupportedAnnotationTypes()这几个方法就可以了。另外再Java7及其以后我们还可以使用注解@SupportedSourceVersion()和@SupportedAnnotationTypes() 去替代上面的方法,见于该注解有Java版本的限制,所以还是建议直接重写方法为好。
public class AnnotationTwoProcessor extends AbstractProcessor {
private Messager messager; //用于打印日志
private Elements elementUtils; //用于处理元素
private Filer filer; //用来创建java文件或者class文件
//该方法再编译期间会被注入一个ProcessingEnvironment对象,该对象包含了很多有用的工具类。
@Override
public synchronized void init(ProcessingEnvironment processingEnvironment) {
super.init(processingEnvironment);
messager = processingEnvironment.getMessager();
elementUtils = processingEnvironment.getElementUtils();
filer = processingEnvironment.getFiler();
}
/**
* 该方法将一轮一轮的遍历源代码
* @param set 该方法需要处理的注解类型
* @param roundEnvironment 关于一轮遍历中提供给我们调用的信息.
* @return 改轮注解是否处理完成 true 下轮或者其他的注解处理器将不会接收到次类型的注解.用处不大.
*/
@Override
public boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment) {
return false;
}
/**
* 返回我们Java的版本.
* @return
*/
@Override
public SourceVersion getSupportedSourceVersion() {
return SourceVersion.latest();
}
/**
* 返回我们将要处理的注解
* @return
*/
@Override
public Set<String> getSupportedAnnotationTypes() {
Set<String> annotataions = new LinkedHashSet<>();
annotataions.add(MyAnnotion.class.getCanonicalName());
return annotataions;
}
}
2.注册
注册注解处理器的方法有两种:
第一种: 处理器必须被打包进一个jar包里面,这也是为什么要建立一个Java Module。该jar包需要有一个特定路径resources/META-INF/services的文件javax.annotation.processing.Processor,该文件的路径和名称都是特定的,然后将我们声明注解处理器的全路径写到该文件中,这样Java虚拟机会自动找该路径下中我们声明的处理器。
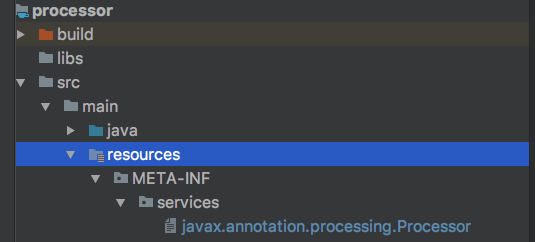
我们再创建文件夹的时候一定要确定其命名的准确性。创建文件的时候直接右键->new file,保证我们的文件的名字为javax.annotation.processing.Processor。
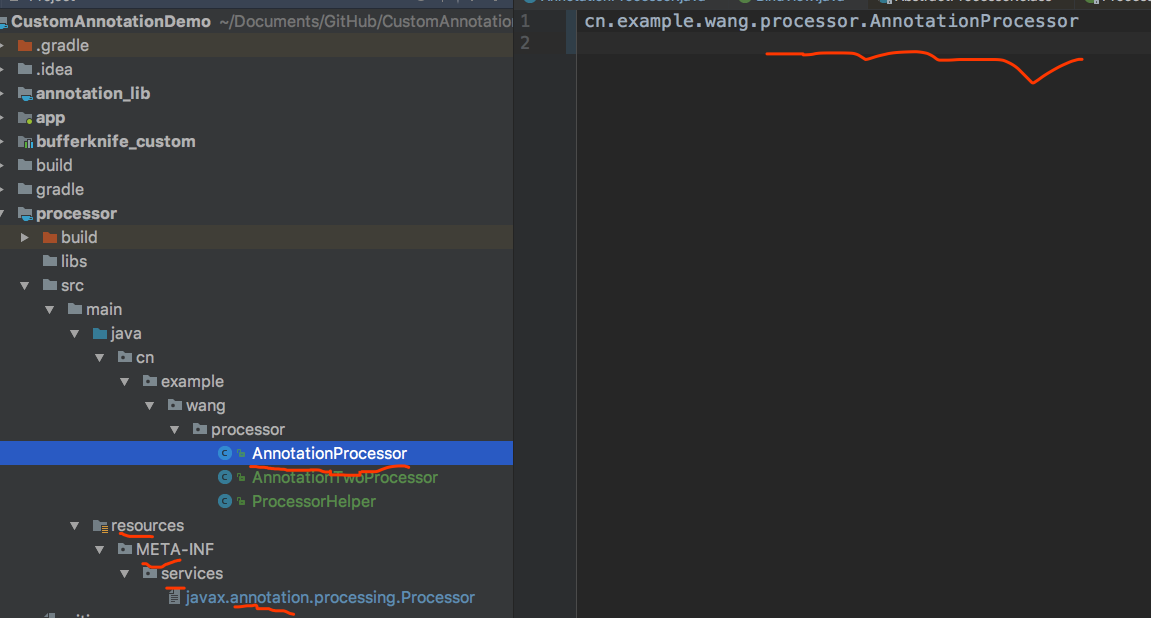
这样问题来了,如我我们写了多个注解处理器该怎么声明呢?接着看。如果我们一个Module里面声明了多个注解处理器,再该文件中声明的时候每个注解处理器要换行声明,运行的顺序就按声明的顺序去执行。这里需要对注解处理器的运行顺序解释一下,再编译期间并不是一个注解处理器完全的处理结束再开始下一个的,而是在扫描一轮源代码 的时候注册的第一个处理器先执行一轮,然后注册的第二个处理器开始执行然后。。。三个。。四个。第二轮的时候还是注册的第一个处理器先执行,然后第二个。。。三个。。。这里面的深刻解释会在下一篇讲解,这篇只是使用。
第二种: 当觉得第一种方法配置繁琐的时候就会有新的更简洁的方式出现。谷歌公司推出的使用注解去注册注解处理器。
-
添加依赖,可以去GitHub上面查找最新版本。
implementation 'com.google.auto.service:auto-service:1.0-rc4' -
我们就可以使用了,它的作用和我们手写的作用是一样的。不过注释的处理器的处理顺序跟你类创建的顺序是一致的,跟方法一中文件声明的顺序不一样。
@AutoService(Processor.class) public class AnnotationTwoProcessor extends AbstractProcessor { }
总的来说方式1的注册方式目前仅在EventBus里面有用到,方式2还是推荐使用的,比如:Arouter,BufferKnife等流行框架都是采用的这种方式注册的,方便快捷。
3.APP引用注解处理器
再引用注解处理器的Module的时候坑其实挺多的。首先我们得确保处理器所在的jar包会添加到我们运行的项目中,注解处理器才会被得到执行,这里呢因为源码不清楚,所以只好自己去试了。Application引入注解处理器包的时候并不像我们引入其它的Android Module一样,这里列举三种种引入方法。
-
plugin: 'com.android.application'我们可以使用implementation,compile,api直接引用注解处理器的module,但是会有一个编译错误:
Error:Execution failed for task ':app:javaPreCompileDebug'. > Annotation processors must be explicitly declared now. The following dependencies on the compile classpath are found to contain annotation processor. Please add them to the annotationProcessor configuration. - annotation_processor.jar (project :annotation_processor) Alternatively, set android.defaultConfig.javaCompileOptions.annotationProcessorOptions.includeCompileClasspath = true to continue with previous behavior. Note that this option is deprecated and will be removed in the future. See https://developer.android.com/r/tools/annotation-processor-error-message.html for more details.我们需要加一段代码,代码位置如下所示,这样就可以愉快的引入注解处理器了:
android { defaultConfig { javaCompileOptions { annotationProcessorOptions { includeCompileClasspath = true } } } }另外我们可以用annotationProcessor引入注解处理器,这个引入方式是为了替换Gradle版本2.2之前的apt引入方法。该引入方式专门用来处理注解处理器。使用该引入方式的时候不会出现错误提示,也是Android中推荐使用的引入方法,该方式也是主流方式。
annotationProcessor project(':annotation_processor') -
apply plugin: 'com.android.library'前提module一定要被android application引入。module里面引入注解处理器的module的话,基本跟android application中一致,这里说一下两个不同点annotationProcessor和implementation方式的引入都不会执行注解处理器,真实的原理并不清楚,只能猜测是application才能正真的处理注解,所以得把依赖暴露出去。这点再android library的module中一定得注意。不太建议该方式引入。
-
apply plugin: 'java-library'前提java library一定要被android application引入。声明这样的module 的话我们就可以直接引入注解处理器了,也不用担心用什么方式引入。不过这种场景不太多。
如何确保你的注解处理器已经注册成功了。首先你已经自定义好了一个注解,并且该注解已经用到了你的代码里面。如下代码所示,你已经设置了我们要处理的是那种类型的注解(代码1所示),然后再我们的process方法里面打上日志(代码2所示),然后点击Android Studio的Make Project按钮,之后打开Gradle Console窗口看build信息,当你发现信息中打印了代码2所示的信息之后就表明你的注解处理器已经运行起来了。如果没有打印信息的话尝试 clean一下项目然后重新Make Project。如果发现没有打印日志的话,尝试查看注解处理器是否已经注册和注解处理器所在的module是否被android application成功引入。
@AutoService(Processor.class)
public class AnnotationProcessor extends AbstractProcessor {
private Messager messager;
@Override
public synchronized void init(ProcessingEnvironment processingEnvironment) {
super.init(processingEnvironment);
messager = processingEnvironment.getMessager();
}
@Override
public boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment) {
//代码2
messager.printMessage(Diagnostic.Kind.NOTE,"日志开始---------------");
return false;
}
//代码1
@Override
public Set<String> getSupportedAnnotationTypes() {
Set<String> supportedOptions = new HashSet<>();
supportedOptions.add(MyAnnotion.class.getCanonicalName());
return supportedOptions;
}
@Override
public SourceVersion getSupportedSourceVersion() {
return SourceVersion.latest();
}
}
4.自动生成Java文件
走到该步骤的时候,你要确保你的注解处理器已经正常的运行。我们使用注解处理器处理源码注解的目的,就是再编译期间完成我们对某个注解的处理工作。比如:BufferKnife再编译期间会在使用特定注解的文件路径生成***—ViewBinding的源文件去处理特定注解。这里用一个Demo去演示如何生成代码:
先看我的注解:
@Retention(RetentionPolicy.CLASS)
@Target({ElementType.TYPE,ElementType.FIELD,ElementType.METHOD,ElementType.LOCAL_VARIABLE})
public @interface MyAnnotion {
String value() default "ssssss";
}
在我的MainActivity上面使用注解:
@MyAnnotion()
public class MainActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
}
}
接着使用注解处理器去处理注解,生成对应的MainActivity_ViewBinding源文件。
public class AnnotationProcessor extends AbstractProcessor {
private Messager messager;
private Elements elementUtils;
private Filer filer;
@Override
public synchronized void init(ProcessingEnvironment processingEnvironment) {
super.init(processingEnvironment);
messager = processingEnvironment.getMessager();
elementUtils = processingEnvironment.getElementUtils();
filer = processingEnvironment.getFiler();
}
@Override
public boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment) {
messager.printMessage(Diagnostic.Kind.NOTE,"日志开始---------------");
Set<? extends Element> elementsAnnotatedWith = roundEnvironment.getElementsAnnotatedWith(MyAnnotion.class);
for (Element element:elementsAnnotatedWith) {
if(element.getKind() == ElementKind.CLASS){
TypeElement typeElement = (TypeElement) element;
PackageElement packageElement = elementUtils.getPackageOf(element);
String packagePath = packageElement.getQualifiedName().toString();
String className = typeElement.getSimpleName().toString();
try {
JavaFileObject sourceFile = filer.createSourceFile(packagePath + "." + className + "_ViewBinding", typeElement);
Writer writer = sourceFile.openWriter();
writer.write("package "+packagePath +";\n");
writer.write("import "+packagePath+"."+className+";\n");
writer.write("public class "+className+"_ViewBinding"+" { \n");
writer.write("\n");
writer.append(" public "+className +" targe;\n");
writer.write("\n");
writer.append("}");
writer.flush();
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
messager.printMessage(Diagnostic.Kind.NOTE,"日志结束---------------");
return false;
}
@Override
public Set<String> getSupportedAnnotationTypes() {
Set<String> supportedOptions = new HashSet<>();
supportedOptions.add(MyAnnotion.class.getCanonicalName());
return supportedOptions;
}
@Override
public SourceVersion getSupportedSourceVersion() {
return SourceVersion.latest();
}
}
结果展示:
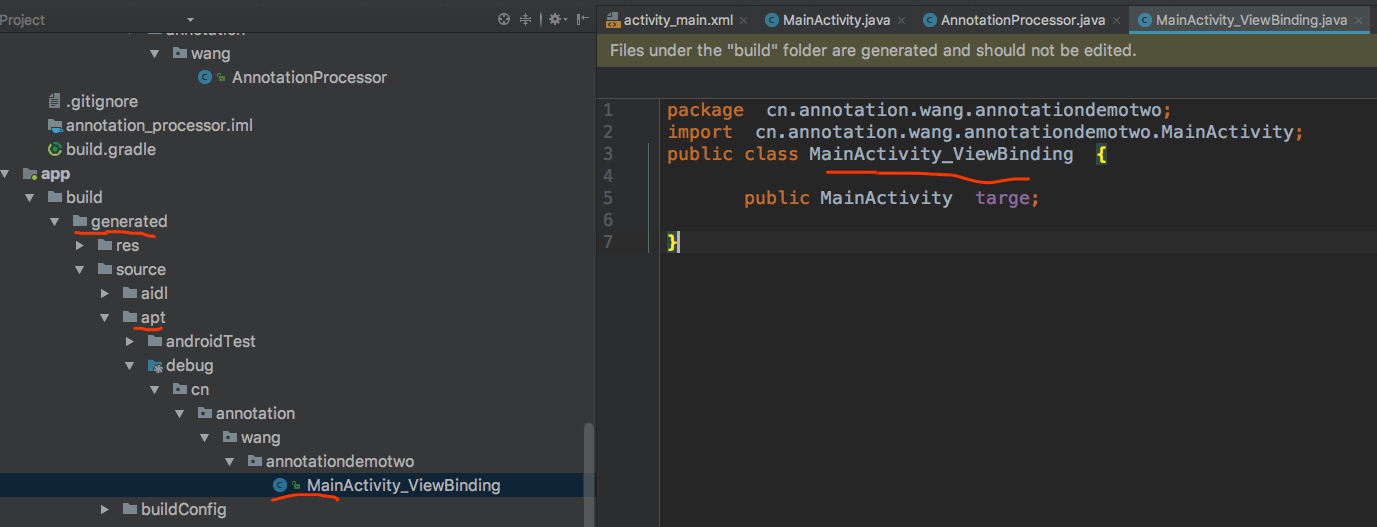
注意一下生成的位置!我们可以直接再我们正常的代码中应用到该文件,因为该文件是会生成class文件的。
5.总结
该文章只是介绍了如何搭建起一个Java注解处理器,没有更深入的去讲解AbstractProcessor类以及我们再处理注解的过程中用到的各种类的API。当然接下来的文章就会详细的介绍注解处理器所使用到的类,方法,属性等的用法和意义,这一定是史上最全的注解处理器API。之后你会更加随心所欲的去构建自己的注解框架。
下章节 史上最全的注解处理器API指导!
欢迎大家留言提出文章中出现的错误以及不理解的地方,会在第一时间进行更正和解答~
