

前言
欢迎来到深入理解 RxJava2 系列第五篇。在上一篇文章中,我们在一个例子里用到了 parallel 操作符,本篇我们便是要介绍该操作符,并对比 RxJava 一些常见的并发手段,详述 parallel 的优越性。
陈旧的 parallel
出生
Parallel 这个操作符首次在 RxJava 0.13.4 版本添加进去,作为一个实验性质的 API,并在同一个版本为Scheduler添加了degreeOfParallelism方法为parallel独用。
public abstract class Scheduler {
public int degreeOfParallelism() {
return Runtime.getRuntime().availableProcessors();
}
...
}
后来在 0.18.0 版本重构了一次Scheduler,并顺带把degreeOfParallelism简化成了parallelism。
遗弃
然而这个操作符当时的实现,并不是那么恰当,和大家预期的用法不一致。类比 Java8 的 Stream API,开发者们期望的是在调用parallel后,后续的操作符都会并发执行,然而事实并不是这样。
当时的parallel实现的有点半成品的意味,因此在 1.0.0-RC2 时被移除了。详情见 Issue :github.com/ReactiveX/R…
与此同时Scheduler的parallelism便不再有用了,随即在 1.0.0-RC11 版本被移除。
GroupBy 与 FlatMap
在parallel不在的日子里,我们如果想并发的做一些操作,通常都会利用flatMap:
...
.flatMap(new Function<Object, Publisher<?>>() {
@Override
public Publisher<?> apply(Object o) throws Exception {
return Flowable
.just(o)
.subscribeOn(Schedulers.computation())
...;
}
})
...
.subscribe();
有些读者会疑问为什么要这样写,直接用observeOn与subscribeOn不行吗。显然不行,我们在《深入理解 RxJava2:Scheduler(2)》强调过,每个Worker的任务都是串行的,因此如果不用flatMap来生成多个Flowable,就无法达到并行的效果。
事实上上面的这种写法吞吐量非常的差,因此我们还需要借助groupBy和 flatMap来配合:
Flowable.just("a", "b", "c", "d", "e")
.groupBy(new Function<String, Integer>() {
int i = 0;
final int cpu = Runtime.getRuntime().availableProcessors();
@Override
public Integer apply(String s) throws Exception {
return (i++) % cpu;
}
})
.flatMap(new Function<GroupedFlowable<Integer, String>, Publisher<?>>() {
@Override
public Publisher<?> apply(GroupedFlowable<Integer, String> g) throws Exception {
return g.observeOn(Schedulers.computation())
... // do some job
}
})
...
.subscribe();
通过groupBy将数据分组,再将每组的数据通过flatMap调度至一个线程来执行。groupBy与flatMap的组合,可以任意控制并发数,由于避免了很多无用的损耗,性能较单独的flatMap大大提升。
然而上面的代码表述力不太好,而且很多不熟悉这些操作符的开发者写不出类似的代码,简单的说就是不太好用。
于是一个能无缝的嵌入Flowable调用链的parallel迫在眉睫。
重生
在 RxJava 2.0.5 版本,parallel终于浴火重生。而这次重生后的parallel不再寄托于Flowable,而是自立门户,通过独立的ParallelFlowable来实现。
public abstract class ParallelFlowable<T> {
public abstract void subscribe(@NonNull Subscriber<? super T>[] subscribers);
public abstract int parallelism();
}
从类的定义可以看出,这个对象的订阅者是Subscriber数组,且数组的长度必须严格等于parallelism()返回值。由于subscribe接口的变化,并发的操作符编写就简单很多。
ParallelFlowable也类似Flowable内置了一些操作符,虽然数量有限,但是非常实用,且可以与Flowable无缝转换。
操作符
Parallel
在Flowable中, 可以通过Parallel操作符将Flowable对象转变成ParallelFlowable对象:
public final ParallelFlowable<T> parallel(int parallelism) {
return ParallelFlowable.from(this, parallelism);
}
从一个Flowable转变成ParallelFlowable并没有线程相关的操作,从参数也可看出,并无Scheduler的参与。数据流的转换也非常简单:
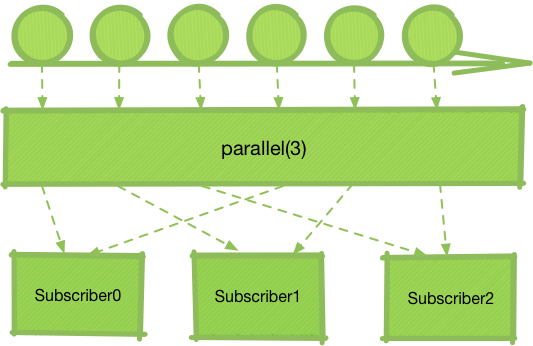
可见Parallel仅仅是将原本应该分发至一个Subscriber的数据流拆分开,“雨露均沾”了而已。
但是转变成ParallelFlowable后,由于多个Subscriber的存在,并发就非常的简单了,我们只需要提供一个线程操作符即可:
RunOn
RunOn于ParallelFlowable就像ObserveOn于Flowable:
public final ParallelFlowable<T> runOn(@NonNull Scheduler scheduler, int prefetch) {
return new ParallelRunOn<T>(this, scheduler, prefetch);
}
public final Flowable<T> observeOn(Scheduler scheduler, boolean delayError, int bufferSize) {
return new FlowableObserveOn<T>(this, scheduler, delayError, bufferSize);
}
这两者参数几乎一致,唯一不同的是ObserveOn额外提供了一个delayError的参数。
他们的效果是非常相似的,都是对下游的onNext / onComplete / onError调度线程。不过RunOn对于下游的每个Subscriber都会独立创建一个Worker来调度:
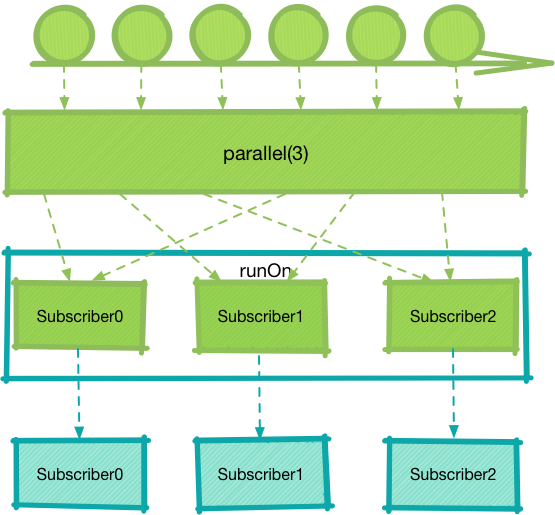
因此多个Subscriber是可能并发的,这取决于选择的Scheduler。我们在前文中强调过,每个Worker创建的任务仅与该Worker相关联,但是这并不意味着每个Worker对应一个线程,不同的Scheduler的实现创建的Worker效果大相径庭,更多细节可查看《深入理解 RxJava2:Scheduler(2)》。
Sequential
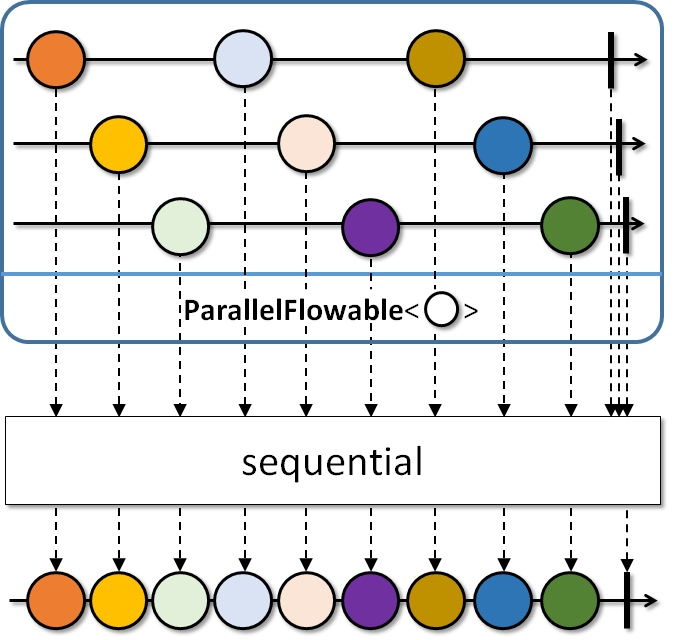
顾名思义,该操作符就是重新把ParallelFlowable转回Flowable,但是数据是循环发射的,不保证遵循数据原始的发射顺序:
其他
以上三个操作符是最核心也是最常用的,除此之外,ParallelFlowable还有诸多操作符,效果与Flowable中类似,部分可根据实际情况与runOn结合使用,以达到最佳效果。
- Map
- Filter
- FlatMap
- doOnXXX / doAfterXXX
- reduce
- sorted
- ...
对比
GroupBy 与 Parallel
上面我们举例了通过groupBy与flatMap组合实现的并发效果。事实上,除了从感官上更加好用外,parallel的并发效果也是最好的。
Benchmark
在 GitHub RxJava 的仓库中,其实已经内置了基于 OpenJDK JMH 的 Benchmark 的代码,均在 src/jmh 目录中,对 JMH 不熟悉的同学可以自行去了解。
我们这里对并发的性能做一次测试,使用仓库中的ParallelPerf类即可,笔者机器的配置是 3 GHz Intel Core i7 4 核 + 16 GB 1600 MHz DDR3,效果如下:
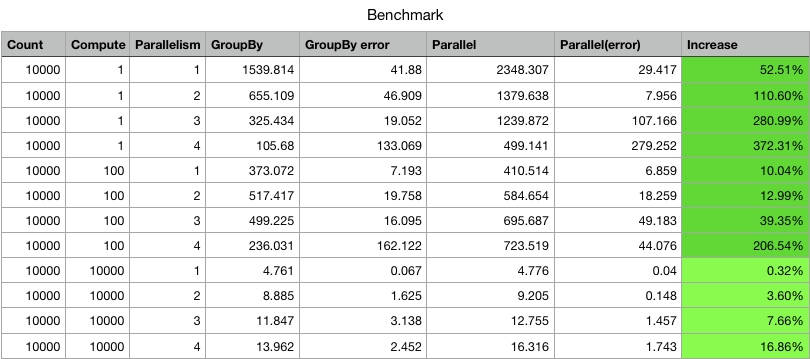
我这里解释一下参数的含义:
- Count:数据源数目
- Compute: 可以认为是 CPU 耗时的单位,随着数值增大而接近线性增长
- Parallelism:并发数目,这里可以近似地认为是线程数目
另外图表中表头带 error 的字样是表示 99.9% 的置信区间,如 第一行的 GroupBy 置信区间为:[1539.814 - 41.88, 1539.814 + 41.88]。
根据图中的结果,可见在Compute较小的情况下,parallel比groupBy是有着绝对的优势的,说明parallel的性能损耗较小。
而Compute较大时,操作符内部的性能损耗相对全局的影响较小,因此这两者性能则差不多。
SchedulerMultiWorkerSupport
不仅如此,runOn操作符在创建Worker时,有特别的优化:
public interface SchedulerMultiWorkerSupport {
void createWorkers(int number, @NonNull WorkerCallback callback);
interface WorkerCallback {
void onWorker(int index, @NonNull Scheduler.Worker worker);
}
}
Scheduler通过实现这个接口,能够针对一次创建多个Worker的情况做优化,目前仅ComputationScheduler支持。具体的源码不列出来了,优化后实际的效果就是尽可能的平均了线程和Worker的负载。
换言之,如果我们使用groupBy做并发时,对应的分组后的Flowable可能由于其他的操作符也在使用ComputationScheduler导致分下去的Worker对应的线程可能有重合和遗漏。
举个例子,请看下面的代码:
Flowable.just(1, 2)
.groupBy(new Function<Integer, Integer>() {
@Override
public Integer apply(Integer v) throws Exception {
return v % 2;
}
})
.subscribeOn(Schedulers.io())
.flatMap(new Function<GroupedFlowable<Integer, Integer>, Publisher<Integer>>() {
@Override
public Publisher<Integer> apply(GroupedFlowable<Integer, Integer> g) throws Exception {
Publisher<Integer> it = g.observeOn(Schedulers.computation()).doOnNext(i -> {
System.out.println(Thread.currentThread().getName());
});
Thread.sleep(1000);
return it;
}
})
.subscribe();
输出:
RxComputationThreadPool-1
RxComputationThreadPool-2
以上的结果是符合我们期望的,数据根据模 2 的剩余类划分了两组,每组的数据的分发在不同的线程中,但是我们在上面的代码后面追加以下的代码执行:
...
Thread.sleep(1500);
int core = Runtime.getRuntime().availableProcessors();
for (int i = 0; i < core - 1; i++) {
scheduler.createWorker();
}
输出:
RxComputationThreadPool-1
RxComputationThreadPool-1
为什么发生这样的情况呢,首先我们在每个数据源observeOn后,休眠一秒,随后这个Flowable会被立即订阅,触发createWorker,我们下面的代码休眠了 1.5 秒,即处于第一个Flowable被订阅后触发了createWorker,第二个Flowable尚未被订阅时,我们又分配了core - 1个的Worker,因此groupBy分配的下个Worker的线程又和第一个分配的相同了。注意这里我们说的是依赖的线程相同,但是每个Worker对象都是独立的,具体原因在上面链接的系列第二篇中详细讲述过。
而在parallel中Worker是连续分配的,因此不受这种情况的干扰,有兴趣的读者们可以自己尝试一番。
结语
Parallel 在改版后,确实是 RxJava2 中并发的不二选择。配合内置的操作符能够让大家收放自如,不再受并发的困扰。
深入理解 RxJava2 系列持续连载中,欢迎关注笔者公众号随时获取更新。

